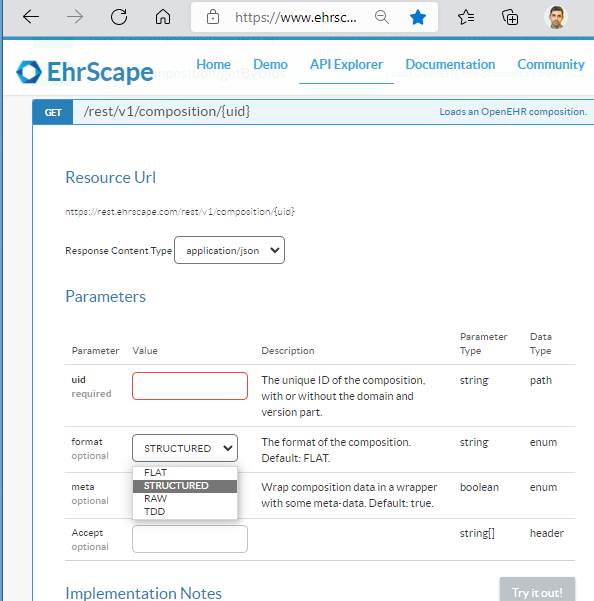
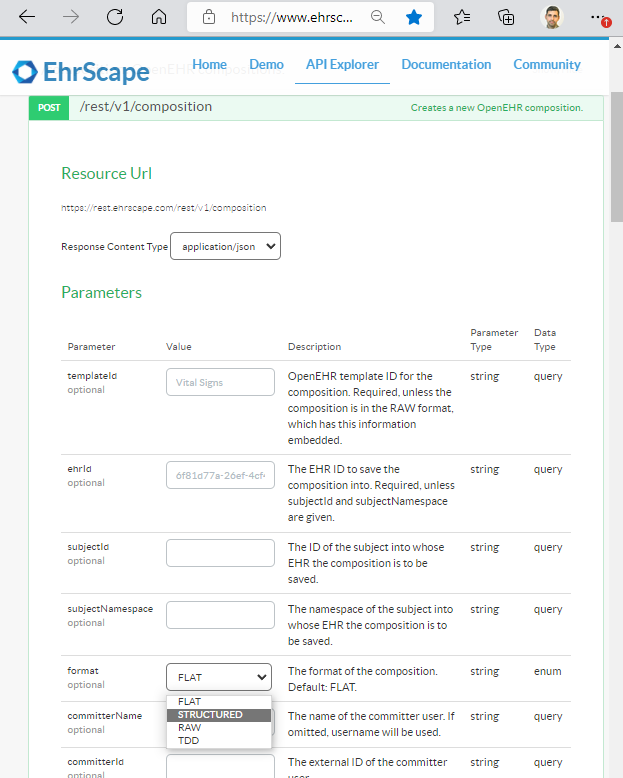
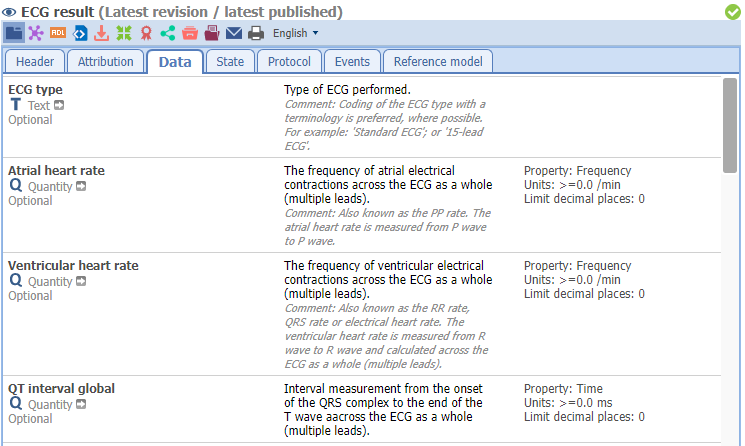
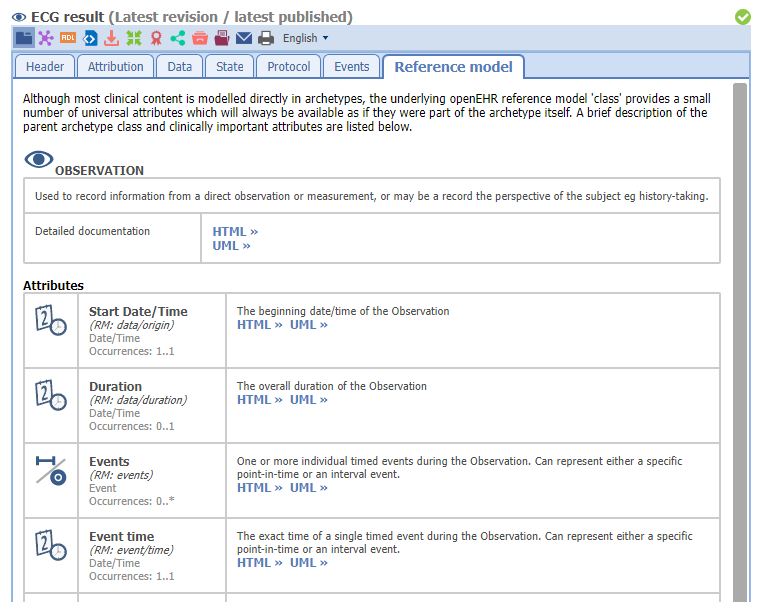
I’ll respond carefully and in case I fail to reflect the history/motivation accurately, @heath.frankel is welcome to correct me.
Both the TDS/TDD and TDO approaches were Heath’s babies. He’s the one who came up with the idea, and the aims were at some level overlapping with what’s being discussed here: make it easy for non-openEHR systems/actors to talk to openEHR, make it easy to work with templates for a developer.
In case of TDS/TDD, Ocean’s template designer produces an XSD from a template, called TDS, and if you can produce an XML file (called TDD) that is valid according to that XSD (schema). This approach dealt with the interoperability requirements of the time neatly. Back then, XML was the dominant ITS for exchange, and an XSD and an XML file did not take much explaining. Sure, XSD could not express all the constraints expressed by a template, but it was a good balance between stopping openEHR leaking to non-openEHR world and validation at source. When TDD(XML) arrives at Ocean land, it is transformed to a canonical Composition XML, then deserialised to RM and validated. Ocean template designer is still freely available after all these years, so you can play with it. The transformation to canonical XML is done via XSLT but I’m not sure if we made that available publicly.
The slight problem with TDSs is, they’re fully self contained. As in, each XSD creates its own little type universe, and with xml namespacing etc, two DV_TEXTs in two XML files end up having different XML types from two different schemas. Not a real problem because a TDS is meant to be a messaging artefact, but in the context of conversation going on here, it is something to keep in mind. Actually, the openEHR SDK from EhrBase had the same behaviour (or I think it did): it generates a set of Java artefacts from models and same RM types end up with duplicate, yet technically different representations in generated code, because they’re based on different opts. Again, corrections are welcome.
A TDO is actual C# source code, generated from templates, and it allows a developer to populate data using the names/concepts as they’re used in the template. This makes a big difference in terms of productivity, but Heath was concerned about various software engineering aspects of using TDOs so he was not entirely enthusiastic about using them, and I disagreed  If my memory is correct, when they started using openEHR based on the Ocean platform, Marand (Better now) even produced Java TDOs and used them for a while. Happy to be corrected on this if my memory is wrong.
If my memory is correct, when they started using openEHR based on the Ocean platform, Marand (Better now) even produced Java TDOs and used them for a while. Happy to be corrected on this if my memory is wrong.
The tricky bit with TDOs was that they required code to go from the TDO type to a canonical RM composition, which is what’s done with XSLT in TDS scenario, and that functionality was not convenient for us to distribute as a library, though at some point around 2014 or so I remember doing it for a partner in an Australian project.
As of today, we have TDOs in our production code, I’m pretty sure of that, and one or more of our integration endpoints may be using TDSs; this I’d need to ask Chunlan Ma, who’s the queen of openEHR implementation
So as you can see, the idea of isolating (which I prefer to separating as a term) openEHR from the non-specialised developers is something we’ve been experimenting with and doing in different ways for some time.
I personally think it is a very good idea, and the eco-system of today provides a lot more options than the time Ocean did TDS/TDD: that’s the thing with arriving too early, there’s nothing around for you to leverage…
This thread has enough disagreements without me pouring gasoline over it, so I’ll keep my specific opinions to myself, but as someone who does this for a living, I see a worrying gap between off the shelf developers and their practices and what we’re doing. Yes, we’re taking steps, but there’s a long way to go and I see lots of good ideas being exchanged, so hopefully we’ll do better come this time next year.