Although OpenEHR is now getting more traction there is a still a considerable learning curve and barrier to adoption. I quick review of other posts suggest it takes at least a year of continual study to gain a good understanding of OpenEHR.
We would all benefit if the models produced by the CKM were much more widely used across the industry. (they should be ubiquitous).
I know first hand from talking to a number of companies and investors that this learning curve is just too steep, and they walk away from OpenEHR.
What I would like to see is an option to separate the Clinical model from any dependencies introduced by OpenEHR, such as the RM. I can see how the RM is very useful for Clinical Modellers, but there should be an option to express (export from the CKM) the model in a more generic way, one that does not require any understanding of the RM, or indeed require OpenEHR tooling to parse/understand.
Essentially an export to XML, JSON or similar, with no dependency on the RM, the model exported a concrete rather than meta-model.
I would say it is almost a moral imperative to realise the value of the thousands of hours of clinical time and governance that have gone into the archetypes & subsets.
As has been discussed elsewhere, the technical side of this is relatively trivial, and indeed has been available in tools for some years. New exports can fairly quickly be coded up.
There is sometimes a misconception that the openEHR RM is a data schema or data model. It can be used as the basis of such, but really the core of the RM (the part that is archetyped) is a small ontology of common clinical information types and context data items.
If the RM is removed, you lose:
types like COMPOSITION, SECTION, OBSERVATION, ACTION, INSTRUCTION etc
the clinical data types, i.e. DV_TEXT, DV_CODED_TEXT, DV_ORDINAL, DV_QUANTITY, etc
attributes like ENTRY.subject, ENTRY.provider, COMPOSITION.context.start_time etc
Every health information model I know of contains types and attributes with the same meanings - they are essentially standard. If they are not defined in a standard way (i.e. names and types), everyone has to recreate all these necessary attributes directly in the archetypes - and they will do it with different names - which will decrease interoperability, not improve it.
So it is a point of curiosity for me at least what is gained by removing the RM entirely. Or maybe you are thinking of retaining these standard attributes, but somehow converted to just more data items in a large tree? This seems to me more useful, although any variation is technically possible.
The tools export archetypes in XML and JSON. I have attached a shortened version of the blood pressure observation template in JSON.
Would this be useful for your approach? If not please show an example of XML/JSON that would be a useful export from the openEHR archetype modeler. Maybe it can be done.
Combinations of properties like e.g. “@type” : “C_COMPLEX_OBJECT” and “rm_type_name” : “OBSERVATION” could be entities in an E/R model.
Properties like “@type” : “C_ATTRIBUTE” and “rm_attribute_name” : “units” could be attributes in the entities.
And many of the properties in the attached JSON can probably be omitted.
Yes, the CKM could support the format you need (up to the CKM vendors) or an online tool could convert the files exported from the CKM into the one you need (this is independent of the CKM vendors who might not have time to support such a format).
At the moment I’m curious what format would help you achieve your goals?
So once you have a Blood pressure archetype (or template - which do you plan to use?) in a JSON file, how would you use it? For the backend, frontend, ETL,…?
You probably already found these (and other posts):
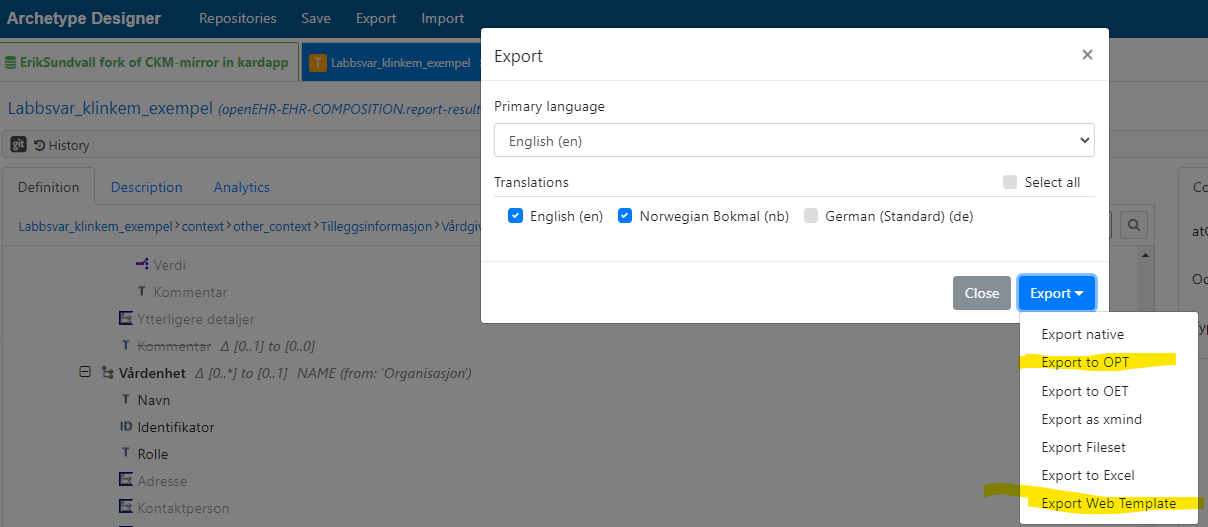
The “web template” format could be described as a kind of pre-parsed version of OPT (operational template), would that work? It can be exported from Archetype Designer:
Yes, for example auto-generation of a template-specific JSON-schema for the simplified “structured” format (that is a tree- version of the same sematics as “flat format”) would be wonderful. I’d guess somebody with less rusty programming skills than me could easily make a generator that consumes a web template file and spits out a template-specific JSON schema…
Here is a piece of an instance example that should adhere to such a schema:
Also, generating a readable template-specific GraphQL schema might be just as useful as a JSON schema. It could be used with a potential future Contribution builder API.
Thank you for sharing your experience here. I’m sure most agree the learning curve for openEHR is way too steep. And the investors walking away is a new perspective that adds to the information around this discussion.
I do feel that one of the reasons the learning curve is too steep is that it’s the most comprehensive list of requirements for storing clinical data I know of. (Almost a handbook on health IT). And since this knowledge is not readily available elsewhere and should be common knowledge for people in the field. It adds to the learning curve, while it should be a prerequisite. And my view is these requirements (E.g. always recording context, full version history with audit trail etc.) can’t be simplified without violating medico legal and clinical safety rules. And that should never be an option. If someone is unaware of these requirements or judges there importance difficulty (as happens often), this is very distressing to people who do see those risks, or even experienced themselves how badly health IT is if stuff goes wrong. And this leads to heated debate that can be hurtful and unproductive.
The other part of the learning curve is in openEHR trying to boil the ocean e.g. do everything perfectly flexible (item_tree and many variants on it) and the decision to let clinicians do the modelling in a computable way (ADL) and the design choice of a RM meta model comes from this. I like this a lot about openEHR, because in the words of @bna‘I know I can handle any clinical (modelling) problem’ . But it’s a valid choice to simplify many things at the cost of flexibility, if you don’t need it. I’m really curious about what parts of openEHR you want to simplify. But maybe that’s better for a separate discourse topics.
The third part where we should improve is education. How do we teach people about openEHR instead of our current approach of referring them to hundreds of pages of documentation. (Your words, right?). There are efforts here but they are constrained by resources. All help welcome here I guess.
The fourth part is abstracting away most of the complexity. This is where open source software (ehrbase) libraries (Archie) and tools (ckm, archetype designer, medblocks ui components, OpenAPI generator etc). There has been great progress in this area, we’re almost at a point where if you develop a simple app or create a clinical form, you don’t need to know technical details of openEHR and work in your preferred stack, while retaining the comprehensive requirements of openEHR and strongly increasing the speed of development compared to starting from scratch or smart on fhir. Where before it was a huge challenge to first engineer a Clinical Data Repository, and openEHR front-end. This is still where I believe the openEHR community should focus it’s efforts. With generating OpenAPI models (JSON schema variant) from openEHR templates, that allow generating code (as first class citizens in your words) in many languages, without knowing much about openEHR as my desired next step.
But you, as an enterprise architect are not directly the target audience here. You should know what’s under the hood. As you’ve repeatedly expressed and as shown by you detailed questions about ADL, Odin etc. And I understand your company to work on an ‘openEHR compliant’ EHR platform.
But the availability of open source CDRs should help greatly in the speed of getting familiar with openEHR. To start I’d recommend the videos by @pablo, they explain how to get data and how to work with it. A lot better way to get started on openEHR then to implement a new CDR by reading the specs, which used to be the only option to get started.
As a final part, now that I mention Odin, there’s also the part of domain (openEHR) specific languages. This also is a barrier to understanding compared to reusing similar languages that are familiar to many people. This is also something I heard you complain about repeatedly. And I agree with you here, as many people in the openEHR community do. I shared before the openEHR confluence/jira issue where there’s talk about replacing odin with json. The other side of this discussion is twofold: 1 are they as fit for purpose (I’m not an engineer and hardly qualified to answer this, but I’m curious for your opinion), 2: openEHR is old, which means when it was developed there was no json as a clear standard, this is only a question of resources to update it. But mostly this is about it’s designed to be used to store lifetime health records. So for the life of the people being (about to be) born. The standard should exist, since most tech is designed to be obsolete in a few decades, this means openEHR should be (and is) tech neutral and it makes us reluctant to create dependencies on other tech to interpret the data. There’s a lot of room to debate specific choices e.g. Odin vs json, ADL vs OpenAPI, GDL vs drools, openEHR DL vs BPMN etc etc.
But since you’ve clearly stated you’ve made up your mind let’s now focus on your request of having the CKM models as json schema without RM as a meta model.
I have to say once (I’ll try to make it the last time): I strongly believe this is only going to be useful for very simple use cases (e.g. a patient self measurement app for blood pressure) where not all openEHR requirements are relevant. And in integration scenarios in conjunction with a full openEHR CDR. Uses like this have been described by Patrik from Karolinka in the present ion slides I tweets to you recently. For other: slide 7 https://www.highmed-symposium.de/
The next thing to state (hopefully for the last time as well) the reference model is an integral part of the CKM archetypes, so you can’t seperate the two. E.g. every blood pressure measurement needs to record the time and setting of that measurement, that is not in the ADL of the CKM archetype, it’s inherited from the RM by statements (in the ADL) like OBSERVATION.
What we can do however is flatten out those inheritances, so that if you export the BP ADL as json (schema)/ OpenAPI that file does contain the relevant inherited datapoints like a time and setting. So that you don’t need to know anything about the RM (nor need an openEHR CDR to use it).
Would that be what you’re after?
And finally I believe we should maybe focus on exporting templates on COMPOSITIONs: models for a specific purpose. E.g recording the result of a BP measurement (instead of a generic BP observation) since many relevant data points (e.g the start time) actually inherit from compositions instead of observation and it’s valuable to have that standardised. Since the modellers of the CKM assumed all archetypes would be used in templates on compositions. So I’d argue the model is (unsafely) incomplete without it.
Would that be ok for you?
It would help me a lot of you would be willing to share a bit more of what your trying to achieve with the models. E.g. what kind of applications/platform for which markets, why usecases etc etc.
From my own experience, it depends on the role of the person learning. When I started learning openEHR my role was Java developer, and my goal was to implement the RM in a working EMR. For an implementer I would say it takes 3 months to get a basic understanding of the basic models (RM and AOM), but requires also hands-on testing of reference implementations like the Java Ref Impl and using the modeling tools (at that time only Ocean tools were available, this was 15 years ago). Then in a total of 6 months I got a good grasp of the specs and basic implementation, which requires almost daily communication with the community (I asked a lot of questions in the mail lists we had back then). I was also able to contribute to the specs and the Java implementation, reporting errors and things that were not so well defined/described in the specs.
Then I had I degree thesis project, which was basically an year and a half of openEHR implementation and integration with DICOM and CDA. This gave me in deep knowledge of the implementation of the specs and how it plays with other standards. After 2 years in total of implementation experience I felt proficient enough to create an online course 100% about openEHR, including specs, modeling and implementation topics.
That is a simple equation: benefits perceived vs. investment estimated should be positive for them to get into openEHR. The issue I see is most companies just get into the specs for a couple of weeks, some without any experience implementing other standards, and want to build a full EHR compliant with openEHR. I believe there is a wrong expectation for some of these companies, which most get into openEHR just for the hype.
To get into openEHR a company should know 1. which problem openEHR solves, 2. see the value in that, 3. most important: they should have detected the problems that openEHR solves into their current systems.
Most want a solution to a problem they don’t have… yet.
For companies that have specific EMR systems or clinical apps, openEHR might not be a good fit. openEHR is about EHR platforms, not apps. It’s about what will happen to clinical information in 20-50 years, not what will happen in 6 months.
This is not the problem, and it is clearly not the how openEHR works. First thing to understand about openEHR is the layered model paradigm, where each layer adds semantics to the previous layer. The RM is the basic semantic model in openEHR, defining the basic information building blocks. The archetype model is the second layer, adding semantics to the RM layer, defining clinical information building blocks. Templates are a third layer, CDS rules a fourth, and so on.
Then, if the archetype model doesn’t reference an RM, you are losing the basic building blocks, and if the archetype model is totally stand-alone, then it will need to define it’s own RM or another RM that is simpler than the openEHR RM. Though, the AM currently can reference ANY reference model, so that is totally possible right now, I mean defining a simpler RM and define archetypes over that RM.
Another point is the current RM has 20 years of R+D of designing, testing and fixing. Though it still has it’s problems, I doubt anyone can come up with a simpler RM that is expressive enough and is better than the current RM. On the other hand, ISO13606 is simpler than openEHR and is expressive enough to represent any clinical data structure, so I guess that one is the best candidate you have today without the need of another 20 years to design and refine a new model.
As a related comment there is no “more generic way”, since when you get your hands dirty in the “generic” approach you will end up with something similar than we have right now. “generic” without any concrete requirement behind is too generic.
My recommendation for companies wanting to get into openEHR but don’t want to spend too much:
understand your problem(s)
contact an expert with real world implementation experience
ask him/her all the questions you have to estimate the effort you need to implement openEHR and/or have your employees trained in openEHR to own the know-how, or just hire people that already knows to lead your team so your team can learn along the way
There is no simple approach to health information management and health platforms, the inherent complexity is just too high.
@pablo I agree with what you write, but would like to improve a streamlined way for app-building etc for use-cases where a template (made by people understanding enough of openEHR and the use case) is already available.
Perhaps a way to, based on an OPT/Web-template file, generate running example projects in environments like https://stackblitz.com/ based on an operational template.
CKM has a lovely REST API which is very simple to use and will give you most of the things the interface gives you. If you are only interested in the mindmap (or other derived materials) other tooling that made use of that API can provide you with the output you need (e.g. LinkEHR can access CKM archetypes and can export them to xmind, but I’m sure there are several examples on other tools)
Here is the blood pressure archetype in Web Template format (stripped out from the parent composition wrapper
I think this is currently the easiest approach.
The full template, which has to include the parent composition is at
and example of how to parse it to an Asciidoc Thx @bna is at
I think what we are really talking about is not to ‘remove the RM’ as such, since have others have said, it provides a lot of basic components such as datatyypes, some basic clinical structures like Observation, Action etc and provenance.
I think it should be possible to construct a subset of the RM that can be folded into Entry-level archetypes, sufficient for clinical sense-making/ implementation guidance and supported in our tooling as well as ‘external’ efforts as @ToStupidForOpenEHR is suggesting.
In a sense, this is exactly what the web template format is doing - it brings in only those aspects of the RM that are necessary to ‘understand’ the model without a deeper commitment to those aspects which are necessary for CDR persistence.