@erik.sundvallmentioned that my generator could also generate OpenAPI schemas. I’ve spent the past few hours writing a generator of OpenAPI schemas from the BMM files.
Please download the generated schemas and report what needs to be fixed:
Lets see if the OpenAPI schemas will be used. @pieterbos generated them a while back and people still weren’t using them (or are they?)
I may use SDT when a generated form will send data to a CDR.
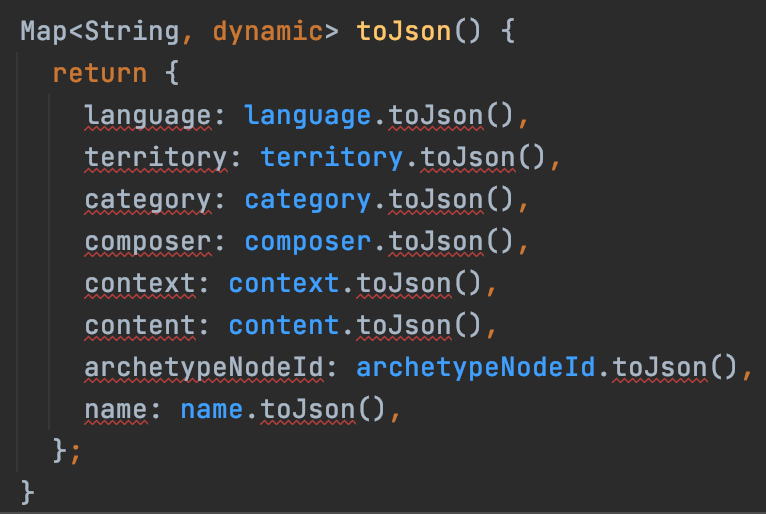
However the code for AM model is only 115 KB and it can be executed on server & frontend. This means I probably won’t need any intermediary formats to generate JSON for the CDR. Just a bunch of generated “toJson()” methods for the models (similar to “fromJson” to read the OPT).
I don’t mind generating stuff that people will actually use.
I don’t want to spend time generating stuff people say they need but then don’t do their part to make something useful with it.
Maybe what they are asking for isn’t the best approach (see the paragraph about using AM model instead of intermediary formats above). Sometimes cleaner architecture makes applications easier to develop, maintain and upgrade.
Cool work @borut.jures a next step I get exited about would be generating OpenAPI from a template. This one is simplish and useful: Clinical Knowledge Manager
.
If you want I can create an even simpler one for e.g. the BP result we talked about with @gary.
Maybe I’ll do that after somebody presents what they did with OpenAPI for AM and RM models.
The generated files aren’t usable as they are at the moment. I will know when somebody is serious about using them - they will start asking questions and suggesting fixes. I’ll wait until that happens
I get excited about the approach I described in my previous post. I should focus on that
The thing is that RM/AM is useful for already openEHR-savvy people creating openEHR tools and CDRs. Those that do that likely already have some kind of solution (e.g. hand coded), thus no rush and less activity seen. What is missing is modern version of the TDO/TDS/TDD approach as discussed in the thread Separating Models from Implementation - #75 by erik.sundvall.
(Of course some of the generated general RM class descriptions are usable also as e.g. data type descriptions to be included in the template specific “streamlined/flattened” approach)
I agree with @heath.frankel’s comment. Many attempts were made to “simplify” OPTs and “protect” developers from learning openEHR AM/RM. None made them happy.
My opinion is that if developers don’t want to familiarise themselves with the openEHR approach to data modeling, they shouldn’t keep asking the community for yet another “simplification” that would enable them to work with openEHR. Just count the number of different simplifications that are useful to their authors but are still not appealing to developers who demand such simplifications. Everything is too complicated for them. I’m afraid that any solution will be too complicated with that way of thinking.
I hope there will always be developers that are willing to spend some time learning before they start building openEHR solutions.
I attempt to skip all the intermediary XML/JSON/paths… and work directly with the model. The prerequisite to this approach is to have the AM/RM available in the frontend app. Then you can write code like:
ehrGate.CreateComposition("Lipids")
…and it will use the models built on the base of OPT to serialize the data for the COMPOSITION that can be sent to the CDR.
Here is an example toJson() method for COMPOSITION that calls toJson() for its attributes (which do the same for their attributes,… turtles all the way down):
I don’t want to be disrespectful to anybody but I believe there is a minimum effort required before starting to build software. I wasn’t afraid of flying until:
“The Max has been grounded since March 2019, after some badly written software caused two crashes that killed 346 people. And while Boeing has received plenty of scrutiny for its bad code.”
There really is. People want the power of modern aircraft, mobile telephony, AI radiology assessments and video-conferencing, while also claiming that ‘every kid should program’ and ‘anyone can build software’. Sorry, but it’s not the same software.
NB: I am talking about back-end systems here. Low-code development is something else - high-level tooling for domain and UX experts to build quality applications. THis also can’t be done by just anyone because it requires some knowledge of cognitive psychology, usability and many other things. There’s really no escape anywhere for actually learning properly what needs to be learned before trying to build things. And the learning has to start with understanding the problem space.
What fits DDD much better is to have a single level model.
This is a crude attempt using some JSON (it’s an instance rather than definition, and not pulled through all the RM attributes, but hopefully self explanatory) AdverseReactions.json (1.0 KB)
Also had a look at the EHR Toolkit provided by @pablo. This is template JSON export to EHRServer, which is getting closer but still refers to RM types that I as a consumer don’t know anything about.
I could however probably write a parser for this, without having to use archie or get into ADL.
That looks very verbose if you are looking for streamlined formats and a single level model. I’d guess most developers would consider the e.g. structSDT format described in Simplified Data Template (SDT) simpler to work with, see example below. It is autogenerated from templates and has sensible defaults for many use cases.
There are useful ideas in this book (which I have had for years) but they apply to reference model development, and indeed I have used some.
Trying to use this approach for a really large volatile domain doesn’t work. It can work for a constrained domain though. You might envisage treating each application, or each clinical subdomain as its own thing, and doing DDD to solve it. THe problem is that there are literally thousands of clinical data points/groups common across all those domains (vital signs, common labs, for a start), so you quickly have to get into mapping data from each separate app with its own model to a common model. How will that be represented? As 5,000 Java classes? And the data set definitions are changing all the time, so it’s a giant moving target.
Martin Fowler almost figured out the correct answer in Analysis Patterns - have a look at the diagrams with the dotted lines, to distinguish between classes representing things, and classes representing kinds of things. All he had to do was to go one step further and get out of the class model for the second category.
So, this is part of the point. We think the future is going to see EPR’s broken up into several specialised app’s working across fairly fixed domains. An app for dementia, and app for joint replacements. Ecosystem is the buzz word they usually use.
OpenEHR could provide the clinical models these apps are built on…