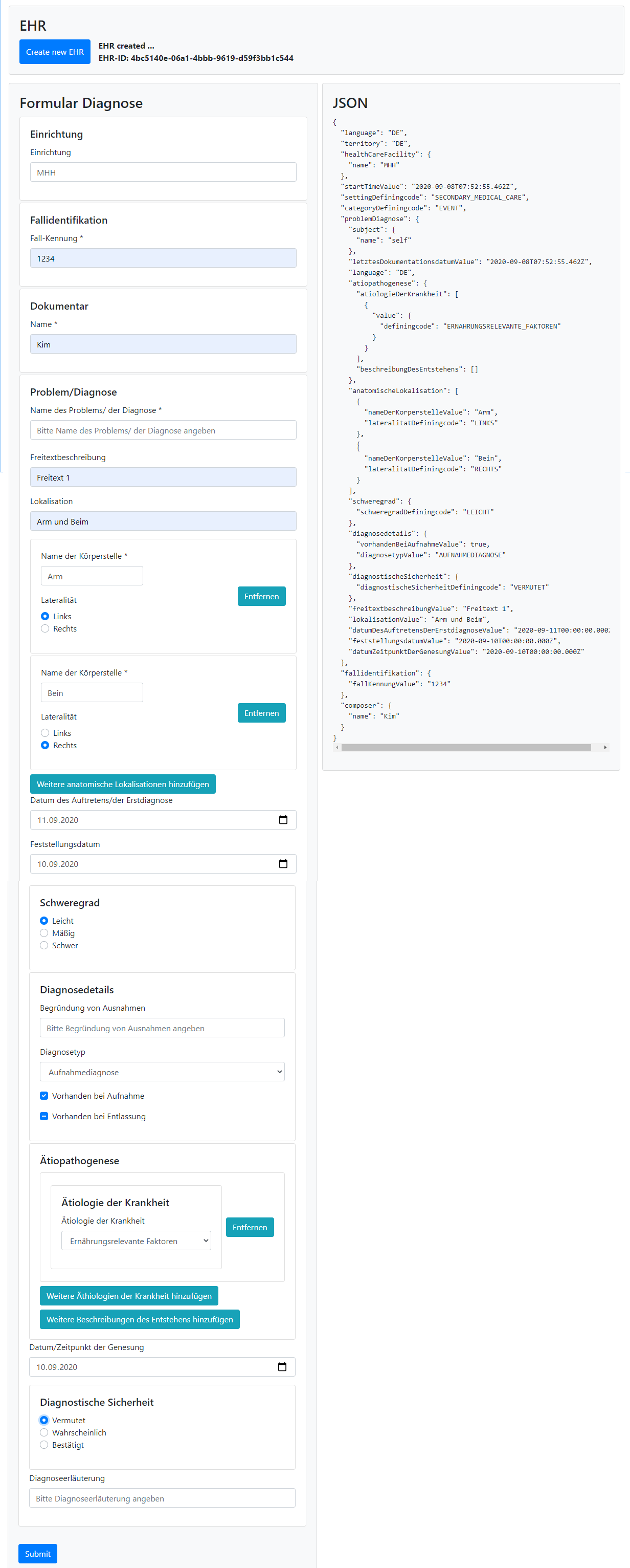
I find your original request there very reasonable. I believe that what you are asking for is exactly what the TDS/TSS approach did/does using normal XML-schema and XML instances (that any XML tool understood, without being an openEHR-specific tool). We’d need a JSON schema-based equivalent nowadays. (And likely a similar GraphQL approach.) Would the approach discussed in post #12 above achieve what you are asking for?
The Web template JSON-files are semantically a schema like TDS but in a custom JSON structure, not in a format that non-openEHR tools like Altova can ingest. Let’s fix that by creating a way to generate proper (template specific) JSON schema (that can be used in regular non-openEHR tools).
The openEHR vendor Better has separated out some generic things (user, language etc) into a context (ctx) object that can be reused in API calls and automatically populate some COMPOSITION and VERSION values from that. That kind separation would likely be clever to allow if we want a simpler format for specific templates.
Yes, what you have in post 12 is closer to my suggestion, a format that non-OpenEHR Tools can ingest.
Let me give you a simple use case. Let’s say an app developer in the UK wants to build a small app for Diabetes patients, they know that the concrete classes will be small, they conclude that a single level model approach is sufficient, rather than two-level. At the moment they have the choice of creating the information model themselves, trying to adapt something from FHIR or going to somewhere like https://theprsb.org/ or using models designed by the OpenEHR clinical community. As it stands the models from the OpenEHR community are only available to those with OpenEHR tools and I think in fairness do require at least a decent understanding of the relationship between the RM, Archetypes and Templates.
If the model could just be exported from the CKM or as you suggest from Templates then I think more people would use the OpenEHR clinical models. This app developer may in due course realise the power of OpenEHR and expand their offering, at which time they may decide to fully adopt OpenEHR.
Yes, that’s a great usecases for the described export!
I think we should do OpenAPI as a format mainly because it allows code generation from the models to first class citizen, so no RM/openEHR or anything! (More detail in the topic by Pieter references by Borut)
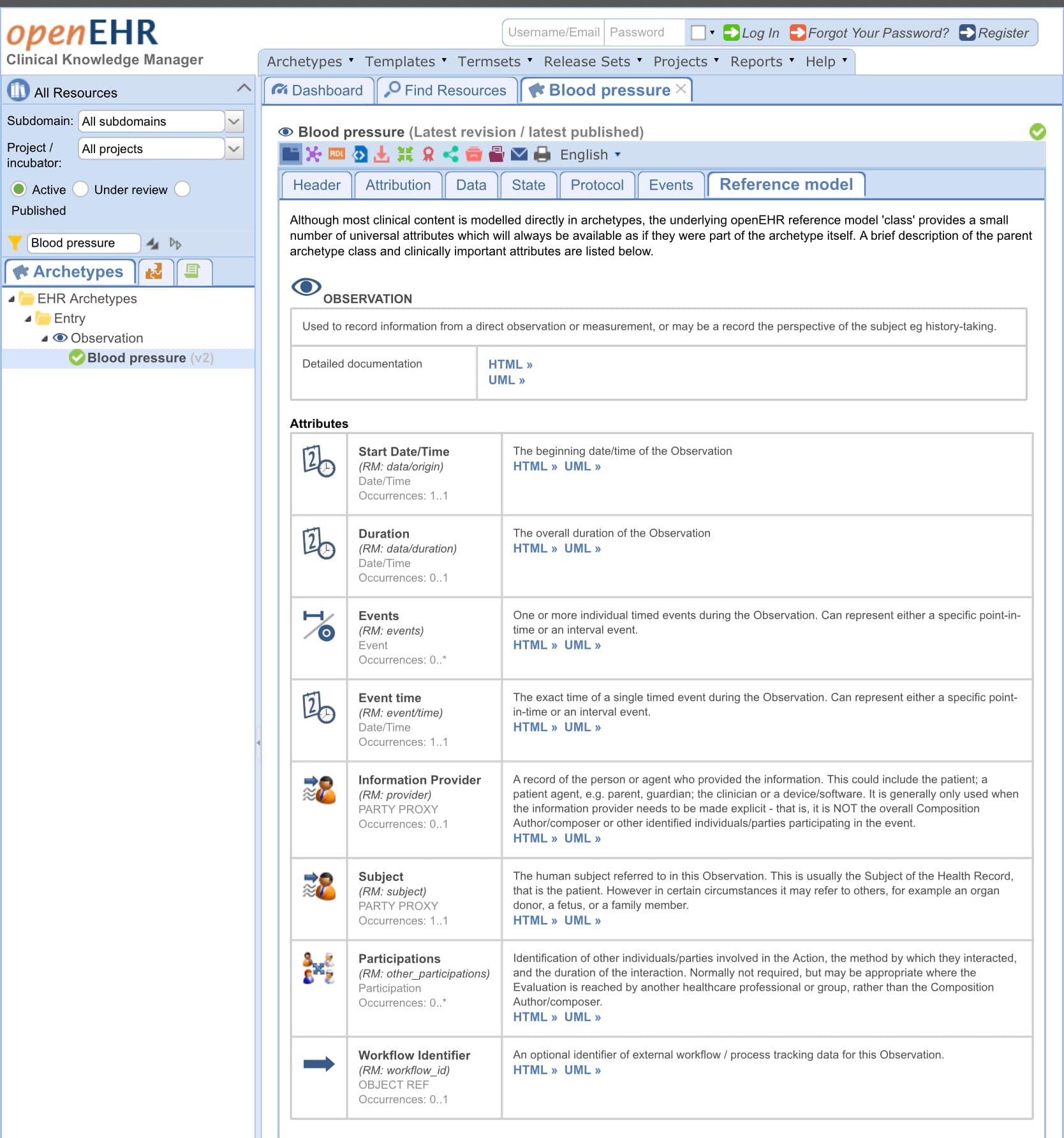
You state you don’t want a multi level modelling approach. The challenge here is what kind of data do you record and how does the app record enough context (meta information) to make it meaningful. Simplest way to do this would be to only use the BP observation archetype and set an (potentially implicit) default context (e.gl time, non professional recorder, etc) in the app. This might be ok, but I’d still say it’s much easier and safer to export the relevant RM attributes (qualification of recorder, time of measurement etc) from the RM with the archetypes. These are the ones on CKM you see at the ‘reference model tab’ Clinical Knowledge Manager
But what the app builder will also have to do is to only render the relevant datapoints from multiple archetypes in a form like ui: e.g. to record a glucose measurement once a day, you need 3-5 archetypes, and disable 95% of the available data points. And if you also want to record say blood pressure and some more related data this gets to be a lot off work quickly. And there’s already a solution for this in the form of templates. And tools to easily create those to achieve the described requirements and export to a webtemplate.
So I’d argue the best way to achieve your scenario currently would be to use archetype designer to do the data modelling work, export as webtemplate and use medblocks ui to render it. Should be doable in less than a day without knowing about openEHR.
If you don’t want an openEHR export format (again I’d prefer openapi), someone would have to build that into Archetype designer (or CKM). What would you be able to contribute to get this done?
Hi @erik.sundvall I don’t see any issues on working on the tech side to build frameworks, SDKs, libraries and tools to make things easier, I did that myself.
What I tried to tell, and might be misunderstood, is my own experience with openEHR and it’s learning curve, and based on that experience, my own opinion on why some companies run away from openEHR, since I don’t think the main issue is complexity of the specs or the lack of tooling available. Though I see more issues in the tooling side than in the spec complexity side. That is also why I created my own tools (https://toolkit.cabolabs.com/).
Another thing is what was proposed here about separating the RM from the AOM just doesn’t work since AOM depends on a RM. My point was that the AOM is already abstracted from the RM since it can be ANY RM, even a custom one, but at design time the RM should be defined so archetypes and templates could be created. The key think to get clear is: this is the core design of openEHR, it is not right or wrong, is the design, so any change at that core area is basically not going in the openEHR way.
That is totally fine, I guess they have a list of core requirements / problems to solve, and some knowledge about what openEHR is for, and openEHR wasn’t a fit for the project. Though there are other things to consider like hidden business goals and politics. I guess they didn’t share with you a detailed rationale why they are not including openEHR in the architecture.
If a decision is made at a strategic level without having a clear list of requirements and knowledge about the specs that could help tackling those requirements, they are clearly considering other things to decide what goes in or not, despite any logic reason.
I mean, some people see interoperability as a business killer, and they promote vendor lock-in. Bottom line: openEHR is not for everyone and that is OK.
You need to define those “things” so the different programs could take a look, community input is important, but we need details.
For instance, what you mention on your first message of separating the RM from the AOM, is not possible as I already mentioned, but the AOM is not depending on the RM, you can use any RM or define your own. The issue is tools available can’t support multiple models (I think only LinkEHR supports multiple models).
My message is not about a lecture, it’s about my own experience when starting from scratch with openEHR, and my opinion why some companies don’t get into openEHR. I thought that could help giving a sample path for people just starting with openEHR, specially to give an idea of the time required to get proficient in openEHR specs and implementation, which is information you can’t find out there…
Which does a good description of describing the thinking behind OpenEHR that had not jumped out at me from the specs page.
Now, I am used to a single model approach, that not only encapsulates data but business logic in the domain model, as per Eric Evans and DDD, and Fowler in PEAA (domain model and all the design patterns)
OpenEHR seems to have started of as a two-level approach (which I think still holds true for RM and Archetype), and is now a multi-level approach (I think templates are the 3rd level on this stack)
I’m asking can OpenEHR models stored as multi-level (I think I want RM+ArcheType+Template) also be exported as single-level. The multi-level approach suggests this would be doable
It is; just a question of the details. I think between the OpenAPI, TDS (others will explain) and Web template options, you will get a solution. My suspicion is that OpenAPI might do the better job today. This allows us to look at it as a model-to-model transform problem - the output is a kind of custom single level UML equivalent, with the concrete format being OpenAPI. But we could pump out real UML or Java, or… whatever you want.
Fellow propeller-heads - do we have an OpenAPI conversion that compresses useful parts of the RM into the output?
I’ve only just got caught up on openAPI formats but I agree - I think that is a pretty decent start point (GraphQL second?). There are almost certainly limitations and complexities .esp. that (as for every health model standard) much more complex basic datatype classes that need to be included and their constraints represented but I can see how that might be a good target for what Gary has in mind.
Has anyone done any practical work or thinking on openEHR opt (or WebTemplate) to OpenAPI? are the aspects of the JSON Schema work that we can pick up?
@nedap we are specifying all apis (incl their models) as OpenAPI 3.0. We’re working on a project to also offer some openEHR data as OpenAPI. Probably a specific template to a specific OpenAPI endpoint with a url that has the template name and the model a fixed map from the template, with manually mapping mandatory openEHR paths to the OpenAPI model.
So there’s a big interest from Nedap and we’re willing to collaborate.
And as has been shared before, @pieterbos already generated the RM as OpenAPI. There are also ideas to generate OpenAPI endpoints for every openEHR template (version). The main benefit is client apps don’t need to now about openEHR complexity for simple stuff (I named our calendar app before).
Finally I think I heard having models in OpenAPI also helps a lot to do graphql. But not an expert here.
Stupid question: my understanding is that OpenAPI is basically swagger which is a way to document a REST API. Or am I missing something here?
Edit: as mentioned once or twice, our software development kit allows to automatically generates human-friendly, non-abstract classes. The endpoint name is derived from the template id. We have also a demo app for this:
Well, OpenAPI is a successor to swagger and indeed is a way to describe REST APIs. What you’re ‘missing’ is that it’s also a way to describe the model of the data that the api gets/posts.
This is modelled using (something very close to) json schema. And this model has proven powerful enough to express the entire RM (for details see Pieters topic). And the OpenAPI has nice tools to work with those models. Visual modelling tools like stoplight studio. And tools that generate code from those models so that a specific BP measurement result template could be a class in swift (or many other languages). And all the benefits that come with that: IDE auto completion, DDD etc, so that its very easy to work with OpenAPI in your native app, and hopefully also openEHR data gets very easy to work with, without the app having to understand OpenEHR data formats and RM.
I am happy to collaborate and help where I can in defining what the flattened model should look like. (we need to find a better term than flattened !!)
I think we should look to flatten both the two-level (archetype) and three-level (template) models.
There probably needs to be some kind of mechanism to specify how much of the optional parts of the RM should be included. For example, reference ranges are very useful for lab results, but maybe not for medication dosages.
If you mean we’d flatten archetypes+RM without having a containing template things may get pretty confused when implementing since most concrete use cases will need a combination of archetypes (+often template level terminology binding) and when comitting data at least be contained in a COMPOSITION.
If you mean we’d flatten all three levels together then I am with you. The simplest free-statnding and comittable thing would be templates where the root is a COMPOSITION.
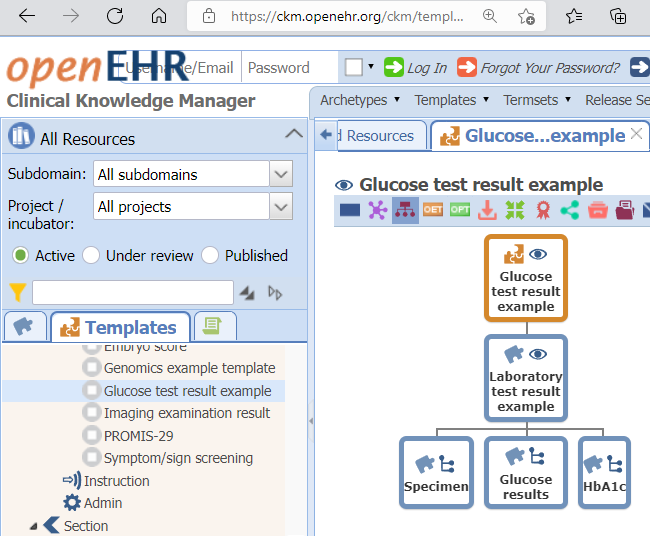
A third option - that might be the real modular use case you might be looking for - may be to flatten templates for reusable sub-parts of a COMPOSITION, similar to the (Glucose/HbA1c) LABORATORY TEST RESULT EXAMPLE template that is made up of several, partly terminology bound, archetypes - in this case rooted in an OBSERVATION. See image below.
Perhaps we should then also offer a list with a set of commonly used pre-packaged flattened templates with user guides, e.g. vital signs.
 (
(