Thanks, Sebastian! Looks like I only have access to view.
That’s an interesting approach. We are actually testing some AI to generate human like text for the text fields in the openEHR Toolkit (https://toolkit.cabolabs.com/) for which we are generating just random text now.
I like the script thing, though some of the constraints could be directly set in the OPT itself, like the ranges for some vitals, but I get that the script constraints could be narrower for testing purposes, which is something we currently do when we test Atomik/EHRServer from Insomnia REST Client (it’s like Postman but friendlier) which allows to set small data generators in JSON payloads. So we first generate the canonical JSON using the openEHR Toolkit, then on Insomnia we adjust the data generators for some nodes.
You could also use the openEHR SDK. Maybe something that we provide in a more convenient way, though.
Does the Composition generated by openEHR-tool needs to fully support UTF-8 encoding? Currently, Chinese characters (zh–CN, therefore other language characters) in the catenated path key are Unicode-encoded , such as \u4e00, which are not human-readable.
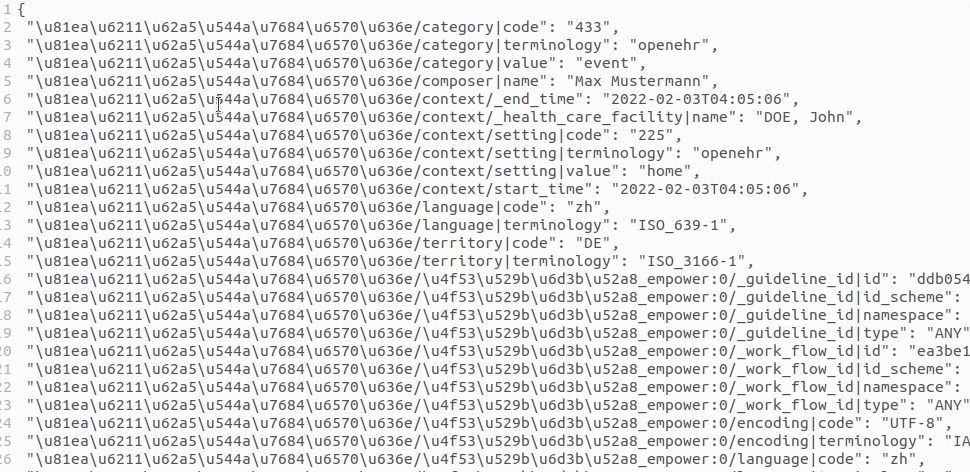
Does this encoding issue of Composition generatation originate from openEHR-tool or openEHR_SDK?
Both github project repo directories have been searched, and Only one file contains ‘Unicode’ in the openEHR-tool project but it looks like directly related to XML:

In addition, both XML and JSON formats are OK with the encoding; both Structured and FLAT formats are not.
When POST a Composition in the formats above, only the XML format works but the other three formats all get a Composition insertion failure (status code = 400):
