Very interesting @borut.jures ! I am no GraphQL expert, but have asked experienced colleagues to have a closer look.
I wonder about some initial things:
The intended/possible context of GraphQL query/mutation execution etc. A single field or subtreee of a versioned openEHR COMPOSITION is not modifiable without making and commiting a new version of the entire COMPOSITION (logically via a CONTRIBUTION). Are you considering using this in a “contribution builder” of some kind e.g. as described in: CONTRIBUTION builder supporting collaborative (multi user, multi device) editing? GraphQL? Operational Transformation? ? (If so, we could load an existing version of a COMPOSITION (or several different compositions etc) into the builder, query and manipulate it (them) and then when we feel finished tell the builder to committ the changed objects via a new CONTRIBUTION.
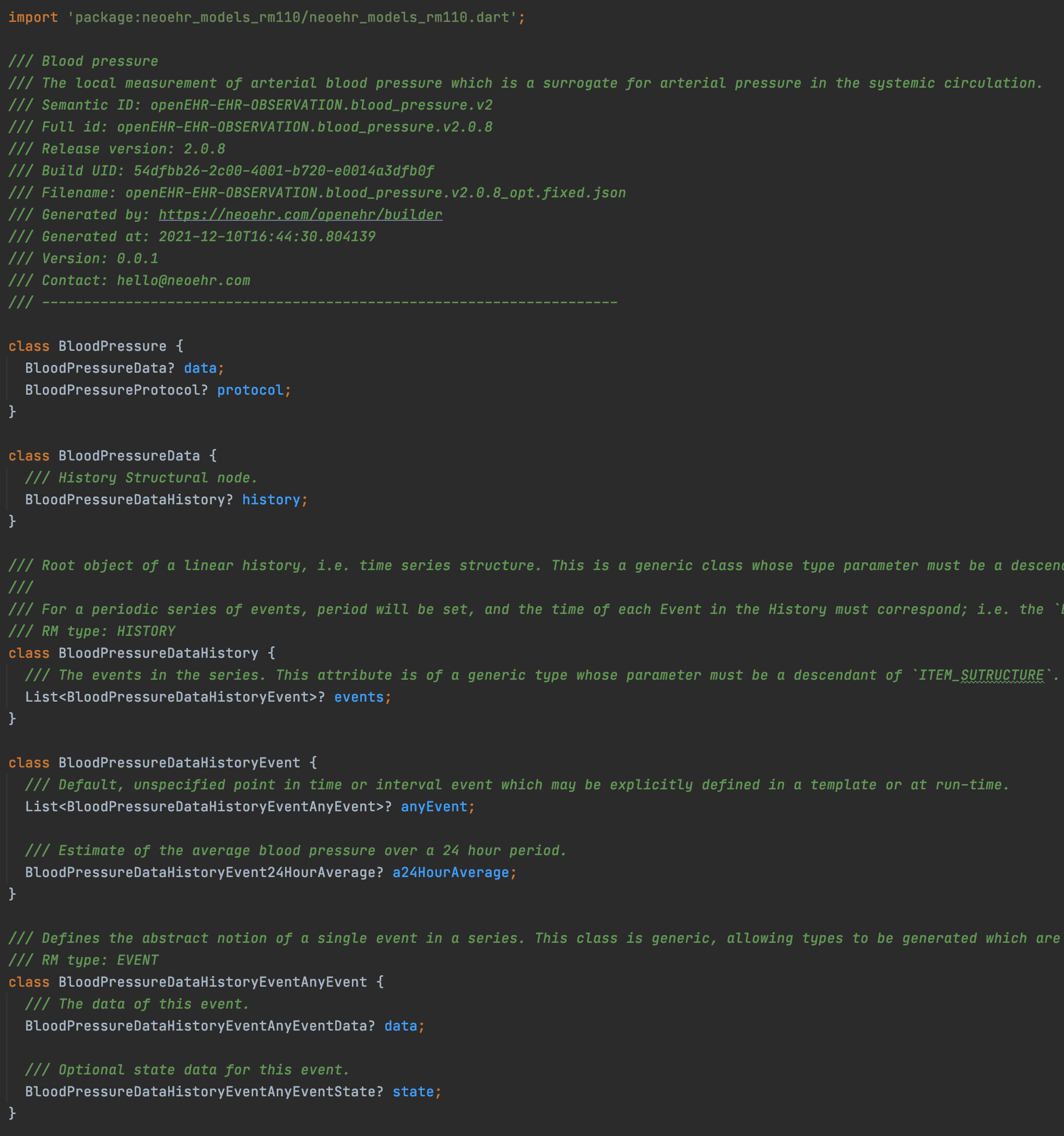
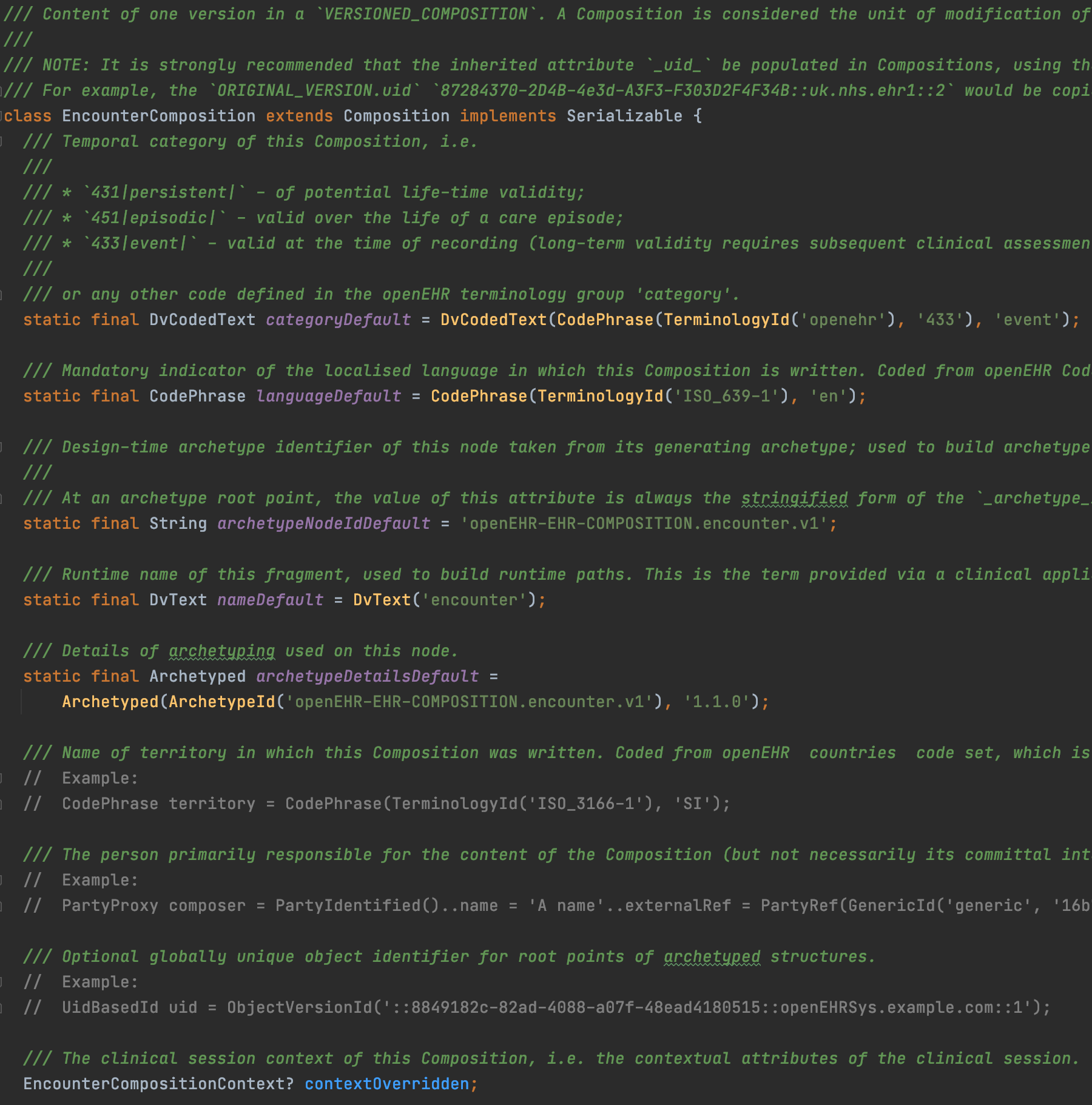
The leaf data types, like different instances of DV_QUANTITY at different paths in listing 1 below seem to repeat the basic structure of DV_QUANTITY under new names BloodPressureDataHistoryEventAnyEventDataBloodPressureItemDiastolicValueDvQuantity has the same content as the corresponding BloodPressureDataHistoryEventAnyEventDataBloodPressureItemDiastolicValueDvQuantity
This touches a bit upon what @Seref wrote about repeated data types in self contained worlds in Separating Models from Implementation - #79 by Seref
If the model/subtree is an unconstrained type (like DV_QUANTITY) I’d guess having and repeating a generic corresponding structure would be more readable
If the model/subtree is a constrained type like the systolic and diastolic subtrees actually are in the archetype (constrained min/max values, chosen units, different terminology bindings etc) then specially named repetitions would be understandable. But maybe that is something you aim for later?
Since I am a GraphQL noob I don’t know if the graphql-constraints-spec is used in tools etc or if it is currently just a seemingly useful suggestion. Or maybe constraints are ususally taken care of by object definitions in client implementations (e.g. constraints built in to a generated TypeScript class for BloodPressure)? - The openEHR backend (CDR) will enfoce constraint checks later anyway…
The structure in Listing 2 below is very readable by the way.
Listing 1 - graphql\schema.graphql
type BloodPressureDataHistoryEventAnyEventDataBloodPressureItem {
# Peak systemic arterial blood pressure - measured in systolic or contraction phase of the heart cycle.
systolic: BloodPressureDataHistoryEventAnyEventDataBloodPressureItemSystolic
# Minimum systemic arterial blood pressure - measured in the diastolic or relaxation phase of the heart cycle.
diastolic: BloodPressureDataHistoryEventAnyEventDataBloodPressureItemDiastolic
# ...example snippet abbreviated here...
}
# The leaf variant of `ITEM`, to which a `DATA_VALUE` instance is attached.
# RM type: ELEMENT
type BloodPressureDataHistoryEventAnyEventDataBloodPressureItemSystolic {
value: BloodPressureDataHistoryEventAnyEventDataBloodPressureItemSystolicValue
}
type BloodPressureDataHistoryEventAnyEventDataBloodPressureItemSystolicValue {
dvQuantity: BloodPressureDataHistoryEventAnyEventDataBloodPressureItemSystolicValueDvQuantity
}
# ...example snippet abbreviated here...
# RM type: DV_QUANTITY
type BloodPressureDataHistoryEventAnyEventDataBloodPressureItemDiastolicValueDvQuantity {
property: TerminologyCode
magnitude: Float
units: String
precision: Int
}
# ...example snippet abbreviated here...
# RM type: DV_QUANTITY
type BloodPressureDataHistoryEventAnyEventDataBloodPressureItemSystolicValueDvQuantity {
property: TerminologyCode
magnitude: Float
units: String
precision: Int
}
Listing 2 - structure from generated\typescript-apollo-angular.ts and many of the other example files
bloodPressure {
data {
history {
events {
a24HourAverage {
data {
itemTree {
items {
systolic {
value {
dvQuantity {
property {
terminologyId
codeString
terminologyVersion
}
magnitude
units
precision
}
}
# ...example snippet abbreviated here...
The requirements in the linked thread are clear - make it as simple as possible for the developers to use an openEHR CDR.
I’m still putting together my thoughts but I guess there will be a GraphQL middleware server that will sit on top of openEHR CDR. It will be a proxy between the CDR and applications that need to interact with it.
Is there a better name for this (middleware/proxy)?
Application developers would get a library (in their programming language) that they would use to store/retrieve documents from the CDR using GraphQL (or REST). They would not need to know anything about the openEHR (although I add all the possible documentation for the interested ones to the generated schema/code).
Thank you for the notes about unconstrained types (like DV_QUANTITY). The generator already has few rules to decide whether to create a specific type or use a standard one that is the same for every property of that type.
I have a TODO to check whether DV_QUANTITY is really the same for every property. It doesn’t satisfy the current rules in the generator as it specifies which DV_QUANTITY properties are used. In the case of Blood pressure OPT it always uses the same 4 properties but there are more in the DV_QUANTITY. I’ll do some more research about this. Any help in figuring this out is appreciated.
In 2013 I did not think of providing simplified formats/paths or GraphQL (not published by then), but accessing the contribution builder via GraphQL would be one of the obvious alternatives that should be provided today.
And now, future speculations:
Another piece of, partly related, middleware could be an AQL result* parser that could be accessed via GraphQL. If it is combined with the contribution builder in smart ways I think that would cover most “simplifying” middelware needs.
*) Perhaps a GraphQL-accessible AQL result parser is not very useful for all kinds of AQL query results, some are really simple enough already, but it would likely be useful at least for certain (stored?) queries that return either:
entire templated compositions (naturally containing “template_id” - see class “ARCHETYPED”) or
lists of subtrees of content extracted from parts inside templated compositions. Perhaps one would need to include the template IDs (+path?) in a response column always named “template_id” - or have some other way to make life easier for the template-based model-translating result parser.
The generator currently outputs Dart code (its syntax is almost the same as Java and JavaScript). Dart tools can compile it to JavaScript (dart2js, dartdevc). It remains almost readable even after compiling. But the readability is not important. The important part is that the code can be run on Node.js or be called from other JavaScript code.
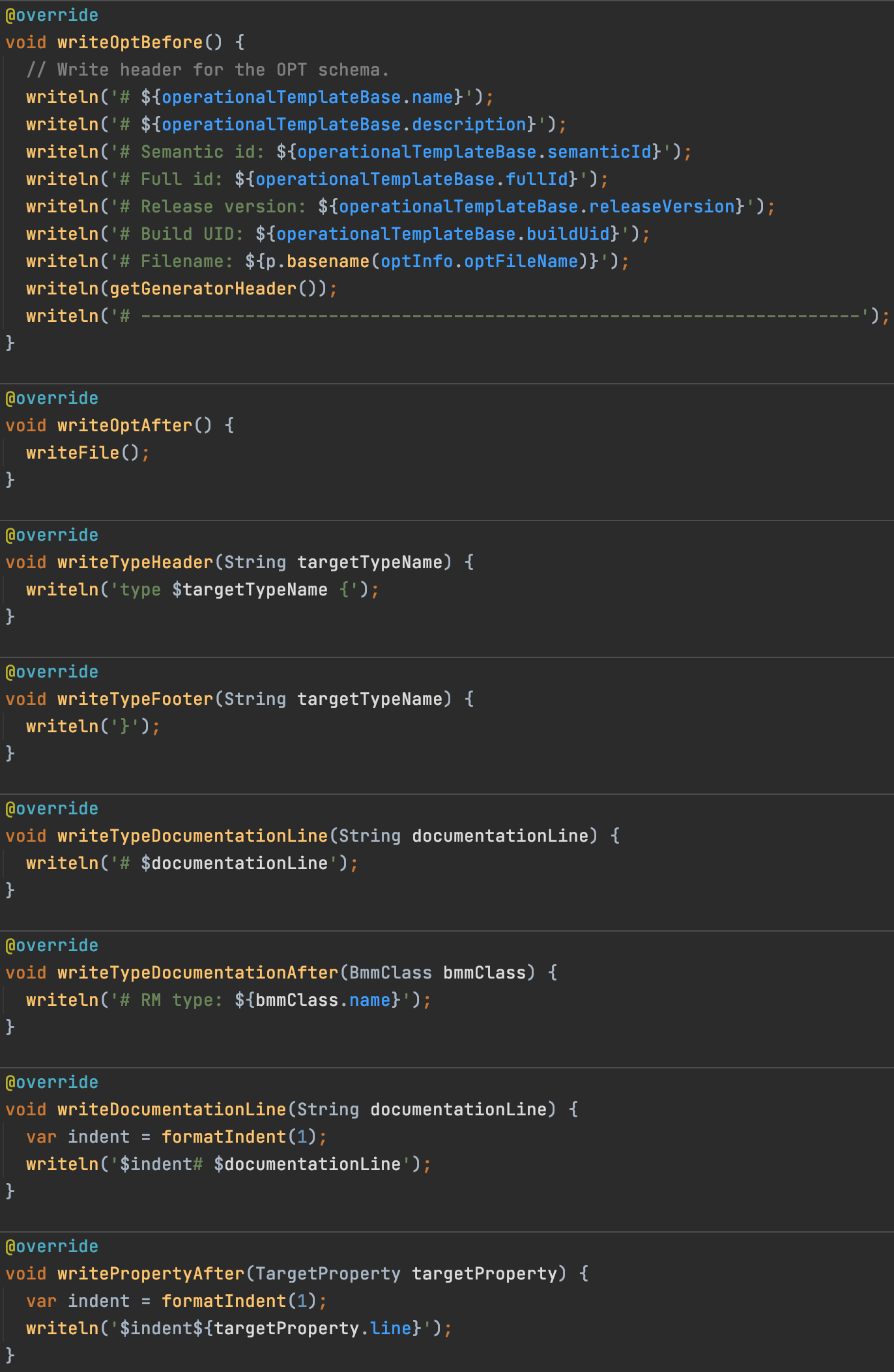
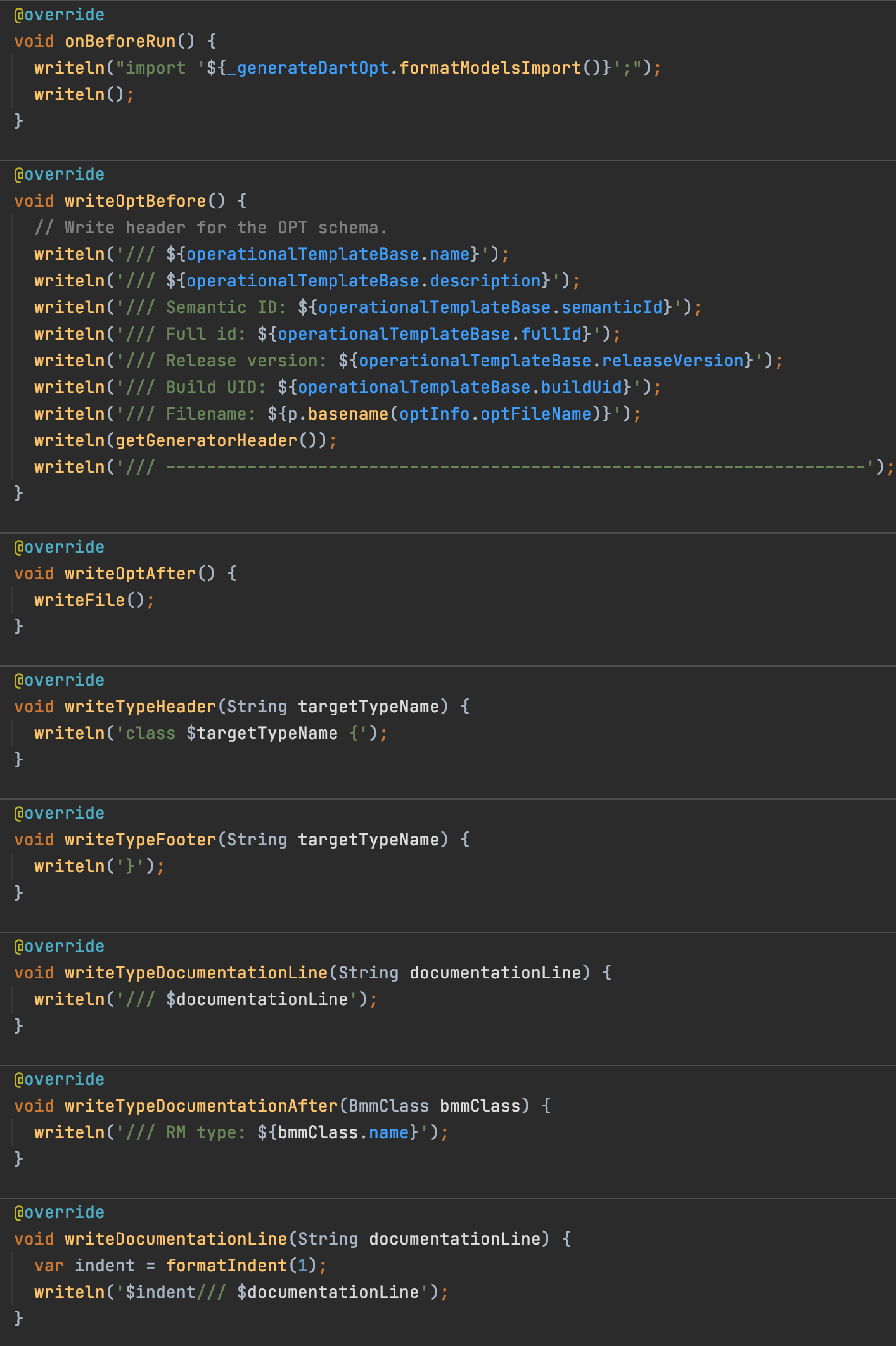
Here is the generator code for GraphQL and Dart. Almost the same. It takes only these few methods and the generator can output code in TypeScript, C#, Kotlin,…
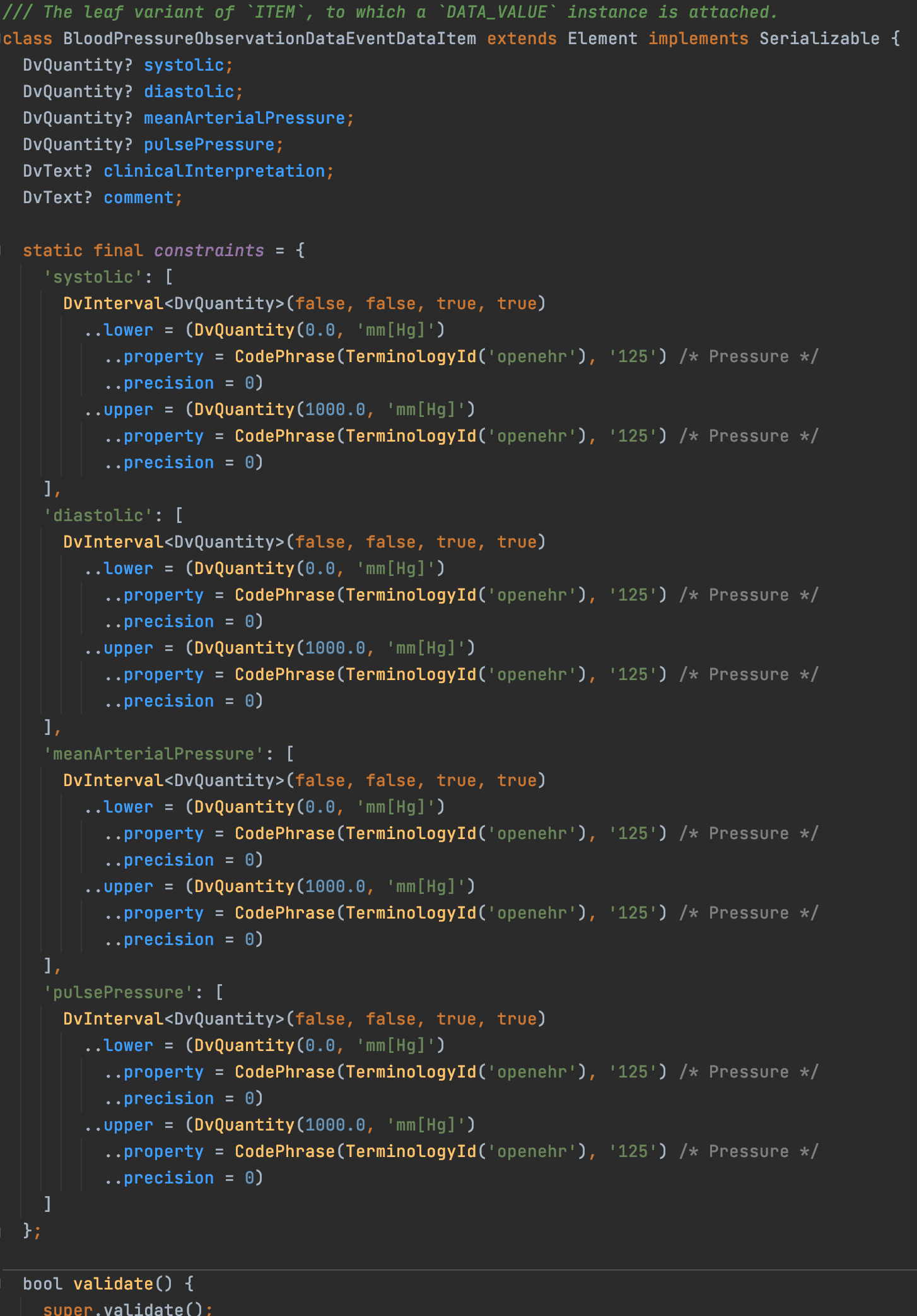
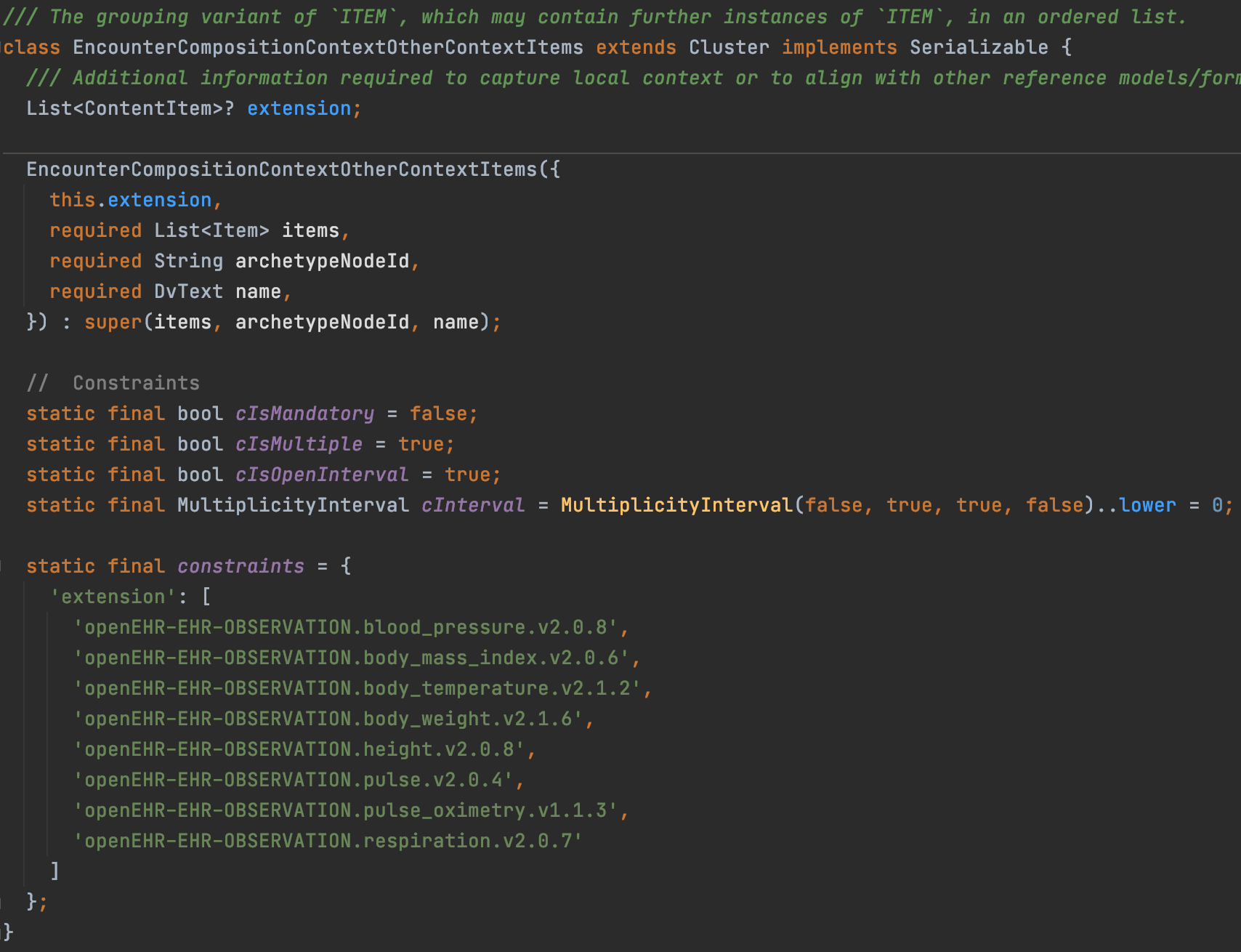
I managed to remove the repeating classes for leaf data value attributes. Now they are all in a single class and using the basic DV_QUANTITY type. The constraints are all in the same class too:
So does the superclass Element(or some other ancestor) contain a validator algorithm that makes use of the Constraints?
P.s.
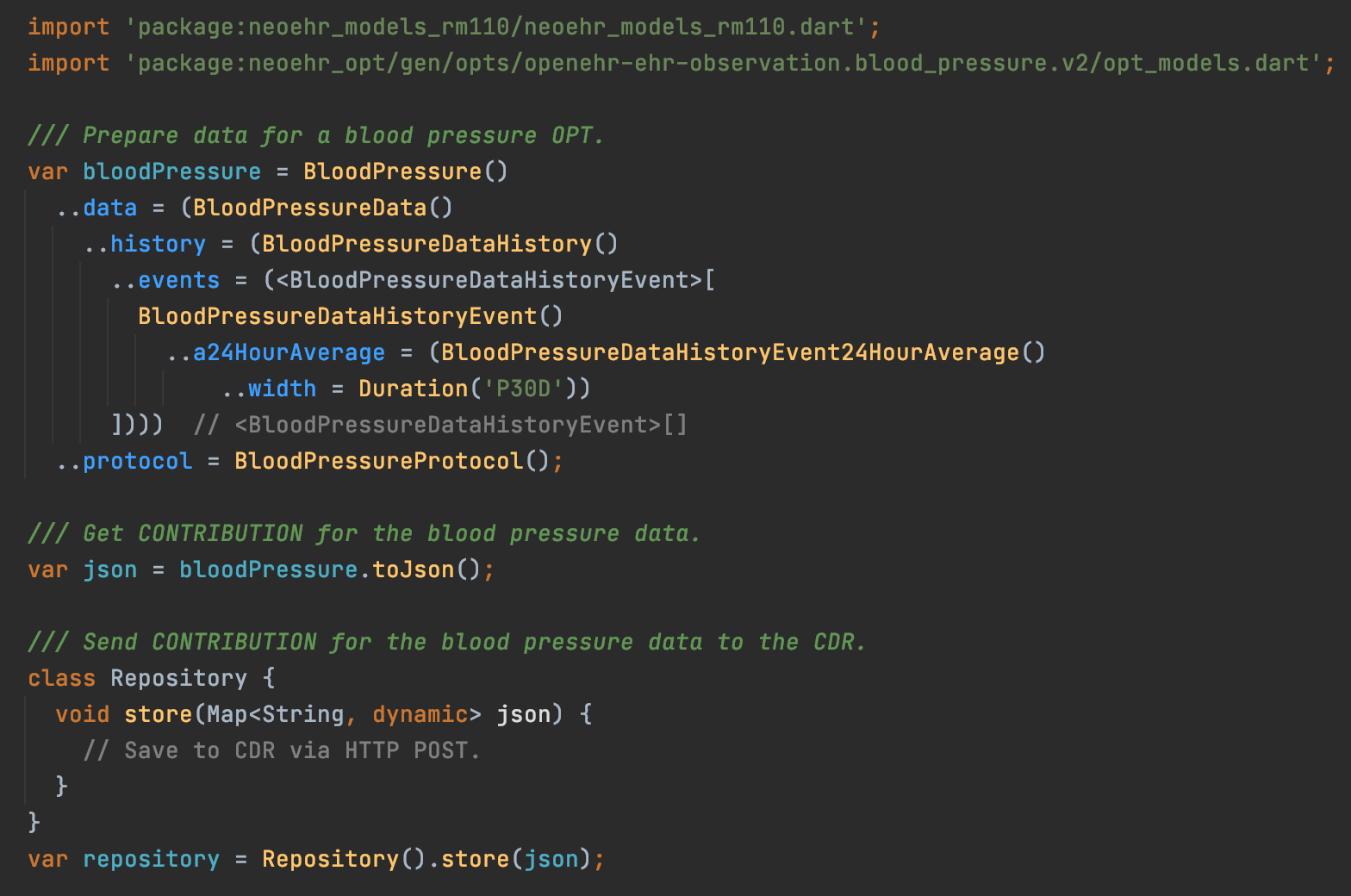
To make examples more realistic and complete (and possible to submit to an openEHR CDR) you could wrap the Blood pressure OBSERVATION in a COMPOSITION an add time an other mandatory fields (and skip pulse pressure + mean arterial pressure).
Showing example code instantiating a BP measurement would also help people understand usage
P.p.s.
I have had a look at Dart, Flutter etc
and believe there is definitely room for openEHR-related innovation/implementation in that space, e.g. for:
simple UX/forms in cross platform developed native apps for old low end phones/tablets (Devices that often have poor/old web view capabilities - as we have noticed in app access logs from patients/inhabitants of Region Stockholm)
openEHR data handling in embedded computing
performance hungry UX (visualisations etc) on “normal” hardware
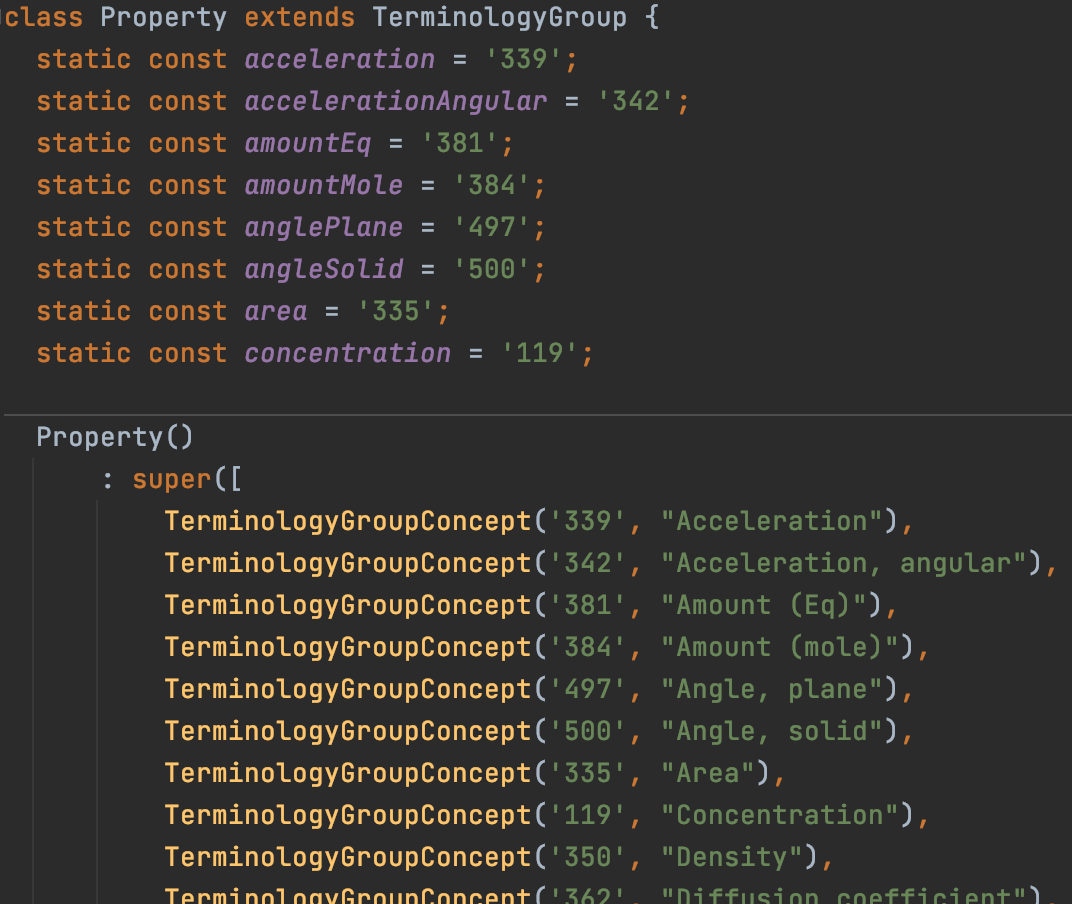
Since you have automated transformations from BMM, OPT etc., you may some time in the future also want to autogenerate utility enumerations for things in the openEHR TERM specs openEHR - openEHR Terminology (TERM) Component - latest
Then code would be even more readable and less prone to error by programmers, perhaps part of your code above could then be something like: ..property= TERM.property.Pressure
In the above example CODE_PHRASE is used since that is what is expected by the RM. To help programmers understand the codes I added the terminology text in comments:
In my quest for simplifications I neglected specifications.
I’ve spent the past few weeks massaging attributes into condensed form likable to human eyes. I ran into all kinds of problems. I should have taken these as an indicator of going down the wrong path.
Yesterday I finally succeeded in generating readable data classes
And today I’ll delete them and return to separate classes for the leaf types
The question I asked myself: Is SDK meant to be used by humans or computers (e.g. generators)?
The clear answer is the latter. Even a simple OPT has too many classes for a human to program into a web form or as an integration interface.