I’ll just talk about my personal journey here.
What really started challenging my view about “API shielding persistence” was Hasura. It’s a project that, given a database schema, will automatically generate GraphQL on top of it. And it’ll also ensure all queries you’re doing via GraphQL are performant and convert them to native SQL.
There are other projects that have similar functionality - PostgREST is an excellent one, widely adopted and supported by Supabase, and they make a similar claim about APIs as a leaky abstraction:
Database as Single Source of Truth
Using PostgREST is an alternative to manual CRUD programming. Custom API servers suffer problems. Writing business logic often duplicates, ignores or hobbles database structure. Object-relational mapping is a leaky abstraction leading to slow imperative code. The PostgREST philosophy establishes a single declarative source of truth: the data itself.
Once our team adopted and started using Hasura, there was no going back to writing REST APIs for every service by hand. We were able to cut down development times by close to 5 - 10x. We didn’t think we were really losing out on anything - we had full type-safety in our applications, and you could autogenerate the types from the schema in seconds. As soon as someone changed the schema in the database (again version-controlled and applied via CI/CD), all types in your system would update and indicate all the places in the application logic you have to update. The application had a GraphQL layer that can let it do WHATEVER can be done in SQL, without writing a separate API route for each functionality by hand. This saved us just SO MUCH time.
Almost all of the SQL queries generated were super performant. We only had to stop and create indexes sometimes - but even these would be suggested by the API engine - “consider creating an index on x”. And our developers promptly did that.
This real-world experience made me believe: Automatically generating scalable APIs on top of a database schema is a solved problem.
What wasn’t still solved well was the security model around these APIs - who were allowed to do what on which resources. This is why we were still building wrapper APIs on top of the Hasura GraphQL APIs to expose to the end user.
But 2 major innovations changed that:
- Hasura came up with its own Authorization layer, which had granular row-based / column-based security
- PostgreSQL’s Row-Level Security
The reason we didn’t go all in on option (1) was that all of the rules had to be authored as YAML that only worked with Hasura. What if we wanted to move to another API generation engine later? We didn’t want to build all our business logic on Hasura that much.
Option (2) RLS was especially interesting, because this was already widely supported by other API generation projects like PostgREST (and Supabase / Lovable by extension) having the core business logic like the security model in SQL just made sense - it was portable, not very vendor specific (given we agree on the premise “Postgres is a standard”), and we were able to use our CI/CD migration pipeline to apply the security model along with the data models.
Previously, RLS had a bad reputation for not being performant, but with recent releases, it’s probably faster than implementing authorization in the API layer.
This also gave us “deep security”. If all your policies about who has access to what, and the data models are present in the database, you can actually give anyone full access to your APIs (GraphQL or SQL, even) while still maintaining peace of mind that they can’t really access what they’re not supposed to access.
Taking this idea even further, I re-read the whole openEHR technical architecture, and the requirements of a health data plaform. And I realized that every single one of the requirements could be done directly in the database. We built triggers and procedures to handle audit logs, we built versioning into the database - so even if someone makes an API call through GrahpQL or SQL, all these operations will ALWAYS be done at the database level.
Combine this with clinical data models in plain SQL (https://github.com/medblocks/health-tables private repo - ping me if you’re interested in checking this out), and this gave me something that I was always looking for (in openEHR and other standards) - a platform that will implement the hard bits for you and guarantee that all the security + compliance is taken care of, have uniform information models that’s widely accessible, I can open this up to any tools that already works with SQL, I can have a regular developer not learn anything about openEHR and have them working on an app.
We’re also experimenting with mapping these simple relational data models back to openEHR CDRs (via REST APIs), FHIR CDRs, and OMO - and this works really easily with patterns that are super easy to implement on SQL, like the transactional outbox. And app developers can optionally set up their common data models in one set of tables, and have their own internal application logic in another - and they can write to the common data model tables and their app tables within the same transaction to ensure all apps stay on the same page - something that openEHR has always been about, but technically doing this with multiple system would be a very complex process (SAGA, Even sourcing are not operationally simple to implement).
So this is how I came to the conclusion that “A Postgres database directly as the health data platform used by multiple apps is our best bet”.
By adopting this, we get extreme operational simplicity - anyone can run this on any cloud / on-prem - you just need to apply some special SQL migrations. It’s easy to maintain over a long period of time - we are almost guaranteed that we’ll get future updates to Postgres, and our data models, as they evolve just need to think about how to move existing data to newer schemas upfront. All of the complexity and compliance requirements of healthcare are hidden away in database triggers and procedures. Regular developers with simple tools can just use the Postgres database as they always do - just ask, they do use the common data models while persisting shared clinical information.
Of course, this would definitely be a thing. But before we get into that, I just wanted a system that worked well for me and my team. I want something I can confidently suggest to healthcare organizations. Something that would scale, be maintainable, and be reliable over time. To me, that answer is “just use Postgres”.
That’s why I think being “technology-neutral” also sometimes makes openEHR “technology-unaware”. And this is never the case:
The vision of a specification can only be achieved when it knows the engineering possibilities and the constraints:
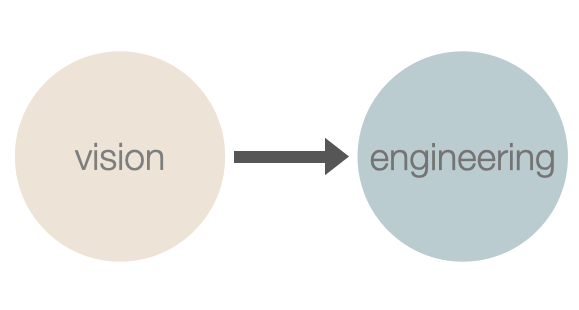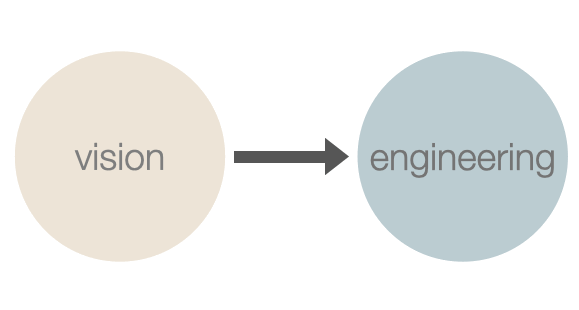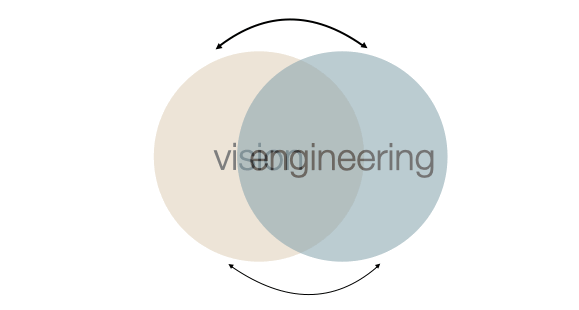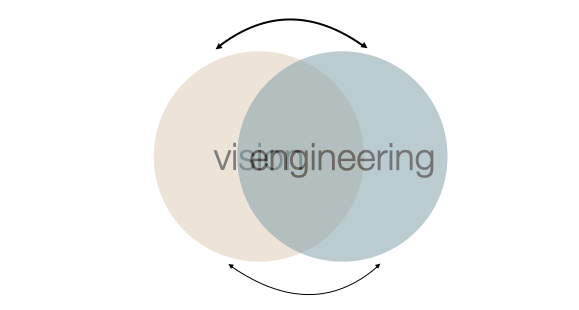
I think we can implement the principles of openEHR and what it stands for directly on top of Postgres - we can’t implement everything as is, and we might need a rethink of what openEHR should look like, given the engineering constraints.