I sometimes say this in lectures about openEHR.:

…and since you want to use RUST, the third rule probalby appllies to you ![]()
My advice regarding storage would be to pick a database that:
- is good at storing and querying tree-structures,
- capable of storing an existing standardised canonical openEHR serialisation format, wich currently would be JSON or XML and
- the database should also already have a built in query language for graphs or tree-structures
There are many such DBs, our research in the ORBDA paper indicates that for example ElasticSearch and Couchbase could be interesting for large scale deployments. If you are targeting something smaller with Rust like running openEHR in a resurce constrained environment like a Raspberry Pi then other options are likely better.
When it comes to AQL you then “just” need to make a translator that transforms AQL to the DB’s built in query language. Likely using a RUST-based parser generator and the published AQL grammar files. (A long time ago I was invovled in doing this in Java with XQuery as target since we used an XML database).
Then there is the problem of eating the openEHR elephant… Although some things have changed and the REST-spec that became openEHR standard is different than in the REST+openEHR-paper the suggested architecure breakdown into smaller pieces (Figure 3) likely still would be useful and let you complete one useful Rust-based piece at a time:
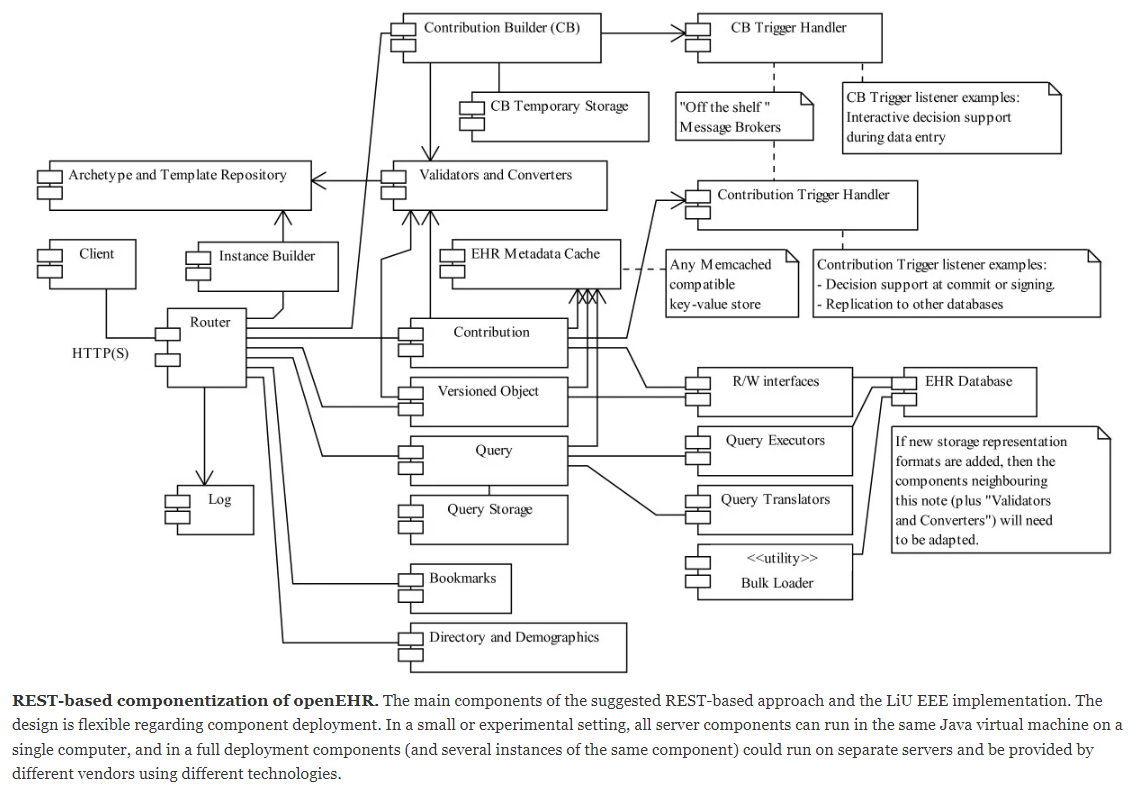
You could for example make an excellent RUST-based read-only openEHR CDR (useful as backup copy, research DB or for load-splitting/sharing of read operations) It could have full AQL capabilities without you even having to first learn and make complex validation stuff.
It could be used also in read+write scenarios by piggy-backing on EHRbase or any other openEHR CDR with validation - or just call and use their input validation code until you some time in the future may have written one (which may be a challenge in RUST).