…and since you want to use RUST, the third rule probalby appllies to you
My advice regarding storage would be to pick a database that:
is good at storing and querying tree-structures,
capable of storing an existing standardised canonical openEHR serialisation format, wich currently would be JSON or XML and
the database should also already have a built in query language for graphs or tree-structures
There are many such DBs, our research in the ORBDA paper indicates that for example ElasticSearch and Couchbase could be interesting for large scale deployments. If you are targeting something smaller with Rust like running openEHR in a resurce constrained environment like a Raspberry Pi then other options are likely better.
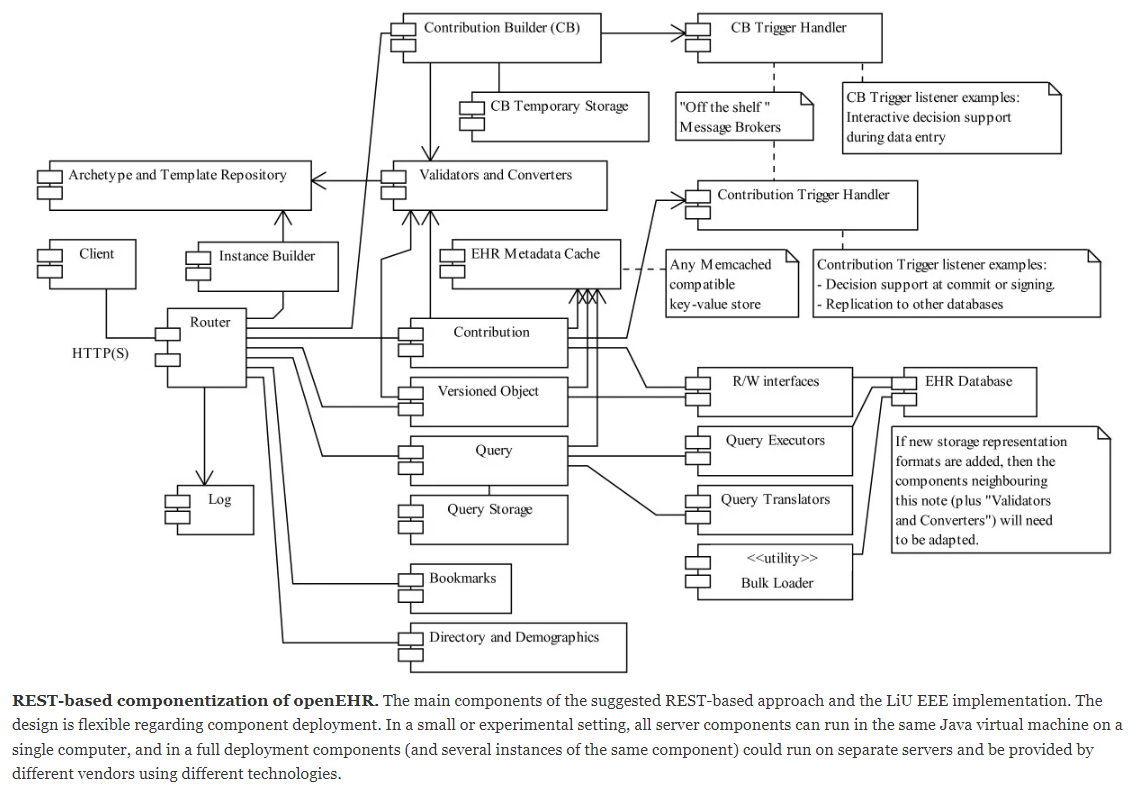
Then there is the problem of eating the openEHR elephant… Although some things have changed and the REST-spec that became openEHR standard is different than in the REST+openEHR-paper the suggested architecure breakdown into smaller pieces (Figure 3) likely still would be useful and let you complete one useful Rust-based piece at a time:
You could for example make an excellent RUST-based read-only openEHR CDR (useful as backup copy, research DB or for load-splitting/sharing of read operations) It could have full AQL capabilities without you even having to first learn and make complex validation stuff.
It could be used also in read+write scenarios by piggy-backing on EHRbase or any other openEHR CDR with validation - or just call and use their input validation code until you some time in the future may have written one (which may be a challenge in RUST).
Okay that’s a lot of replies I did not expect this . Let me get through them one at a time.
Okay I think I’ll start with web templates then and put off the .opt parsing until I get a better idea about the system.
I didn’t really put a lot of thought in the database, I’m starting with PostgreSQL as EHRBase is also using it. If I wanna go the “Rust purist” way, perhaps SurrealDB could be a good fit? It’s still in development but I think it has a lot of features that could help with implementing an openEHR compliant CDR.
Also I want to thank everyone for your quick replies, they’ve been very helpful and gave me quite a lot to think about! I think I’ll start either like @erik.sundvall recommended with a read-only CDR with full AQL capabilities, or a CDR with only web templates support or maybe both I’ll see how much time I can dedicate!
If you want to build a CDR I think database query considerations will be pretty central. You likely don’t want to reinvent a system for tree traversing queries unless it is your main interest or if it would be a PhD project of yours…
I don’t know much about SurreadlDB, but it looks like a relational database. Plain relational DBs are not a good fit for (very variable) tree/graph structures (like openEHR) in themselves. Experienced openEHR system vendors like https://www.better.care/ that I believe offer their customers very many options regarding what relational DB to use for storage usually have other tricks like an inverted index (like Lucene) for the AQL path traversal/resolution and use the relational DB maily as a blob/JSON/XML storage plus some predifined index fields.
I believe the reason EHRbase gets away with using what looks like a relational DB is that they have focused on using PostgresQL that has a lot of nice JSON (tree) traversing functions built in, right @birger.haarbrandt and @christian? Look for things like JSONB and JsonPath in 3.5. Technical Documentation — EHRbase documentation (or the source code) for clues. (But just cloning the EHRbase approach in another language might not be the most fun and productive use of time.)
Anyway if you in Rust make what in the figure is labelled as “R/W interfaces” and “Query executors” you can experiment with different storage implementations without having to redesign the rest of your application stack.
Please note that there is nothing in the official openEHR REST specs corresponding to the “Versioned Object” box of Figure 3 - since when makng the standard (some years after the openEHR-REST-paper publication) in the SEC we chose to split that into more specialised resources like “/ehr/{ehr_id}/composition” and some of it’s siblings. The “Query” box corresponds fairly well to the “/query” API plus some query storage from the “/definition/query” API.
OAS generated code is now at specifications-ITS-REST/codegen/oas-ehr at feature/codegen_testing · openEHR/specifications-ITS-REST · GitHub; this was an experiment around best way of describing OAS model schema so that we get best outcome when we generate code in various languages; in earlier stages I also added Rust, but looks like I did not included in the end that branch anymore. If you are interested in helping in reviewing that code, then I can then keep you updated next time I’m working on it. Or you could also try to generate done using some very dev-mode tooling I made in that branch.
about plans on v2: we will work it year on it, and it is not yet decided how many of the outstanding issues will be in v2 and how many in v1 as release-1.1.0; this subject is still under discussion. In any case, v2 will include a few small breaking changes as we try to fix some inconsistencies in v1, but the goal is anyway to minimize them. More links about plans: CRs - Change Requests, Open Issues and this work-overview page.
I missed it too when trying to explain it to a colleague!! Knew it wassomwhere , justcouldn;lt find it. @sebastian.iancu - I think we need to somehow connect the generic Header infomation with each of the resources that might need it, and add headers to the examples. Happy to help - does this need a CR?
That’s in a way one of the reason we moved to OpenAPI format, so that we can better specify examples, and formally indicate supported headers for each path/resource. These changes will come (to some extent) with the next release, and yes, it would be helpful to have a CR.
Yes, EHRbase is using a hybrid approach with larger parts represented in tables, complemented by JSONb. However, this is currently being re-evaluated and we will change towards a different model that will make EHRbase more independent of Postgres and comes closer to ANSI/ISO SQL specifications.
What’s middle? First design the architecture needed to retrieve data from an abstract storage, figure out what metadata is needed in your DB to get that data out, then design your DB. Then figure out how to get your data in, and finally design the internal management of versions. All design first. And I would also follow that order for the implementation. Then the last thing is to put the API over your platform (data first - API last approach, with strong emphasis on the architecture design).
Note: if you try to implement AQL, that will affect the structure of your database, since you need some kind of document storage (for AQL you need the trees in your DB or have a hybrid DB like relational + document).
I suppose if a hybrid approach is needed, SurrealDB could be the right choice. I’ll have to play around with it. I’ll report back here if I manage to get something done, I’m a bit busy right now
But thank you for your help, I’ll make sure to follow your recommendations!
I would say “needed” is a strong word. The right choice will be the one that allows you to implement the openEHR specification and comply with your platform requirements. So there is no “needed” approach, just a set of possibilities (architectures and technologies) to choose from. There is no such thing as “one fits all”.
Surreal DB does seem to have some object/tree storage and query capabilities so it might work for translated AQL-queries if you are lucky. That would be one of the first things I’d investigate when picking a DB if you want AQL support in your CDR. (On the other hand it of course would help to have the knowledge level of people like @Seref that spent part of his PhD on AQL reasoning or @chunlan.ma that invented AQL/EQL)
If the object/tree-querying mechansims in the DB are too weak for AQL then you’ll need a hybrid solution as discussed earlier (e.g. Dewey encoding or a DB-external inverted index).
Another design choice to investigate when it comes to DBs that (like SurrealDB]?) do have support for tree-shaped object/document schema defintions is, if you either want:
to validate data using an openEHR (operational) template based validator before the incoming data gets pushed to the DB, or instead
to push as much validation as possible into the validation features of the DB itself by first auto-creating a schema for each (operational) template that gets loaded/configured into the CDR.
Just to clarify, both 1 & 2 validation methods above would likely configure their validation based on an admin uploading an operational template using for example ADL 1.4 API or the ADL2 API for operational templates.
#2 may result in very many schema in the DB over time (which may be fine if the DB was designed for handling that).
#1 makes your validation algorithms DB-independent so that it is easier to change DB engine later and easier to use your validator as a freestanding component in other contexts.
One thing that is easy to forget for beginners when it comers to planning openEHR validation (or tool design) is that you need to validate based both on the rules in the (operational) template AND the model/rules of the openEHR RM.
Hey guys. I’m Maxwell Flitton. The author of the Packt book “Rust web programming” and the other book “Speed up your Python with Rust”. I’m currently writing the O’Reilly book on async Rust. I’ve recently joined the SurrealDB team as a core dev. I have a deep interest in medical applications. Before going back to study physics I was a nurse in A and E for 7 years. I’m based in London. If anyone on here wants to talk to me about collaboration shoot me an email at: maxwell.flitton@surrealdb.com would love to hear from you about how I can get SurrealDB into the medical field as SurrealDB also supports embedded, in-memory, server, and cloud. I had a lot of options and chose to sign with SurrealDB because once SurrealDB can comply with the medical community, it’s going to be a pretty good Swiss army knife to solve a lot of problems. I also plan on integrating transaction logging and encryption. This open-source database will hopefully empower hospital and research departments.
Hi maxwell, welcome to the community. What do you like best about surrealDB?
Did you know openehr does not have a relations datamodel? Usually it’s json objects. Because medicine has highly (hourly) changing datamodels with complex variable structures.
Postgres with json support usually works acceptably. But performant querying across/within json structures is still a major engineering challenge solve by inleveren a handful of parties.
How do you look at this problem?
and welcome. Just to add to what Joost has said, as you may not get the answer here you were hoping for!!
openEHR is all based on the idea that we can construct vendor/tech-neutral datastores (CDR) where the interfaces are all based on open standards but critically where new data models can be implemented without changing the internal database schema, and where different dB technologies like SurrealDb (with possibly veery different internal schema, can be swapped in to a CDR without disturbing the application layer , where everything is logically arranged and queried according to the models uploaded by clinical informaticians.
So this is a very opinionated world that any new DB has to fit into, and which may negate many of the advantages of flexibility that you mentioned. In an openEHR world no-one is talking directly to the DB. It is the job of the CDR implementer to make that magic happen, and to choose their DB / schema approach.
It’s not hard to build an openEHR CDR, it is hard to make it perform but we have many examples of this approach working at scale now.
Of course many hospitals etc will continue to use traditional wired-to-DB approaches but we think that the complexity of clinical data and the need to be vendor/tech-neutral will quickly make that a thing of the past.
I’m well aware that wired-to-DB approaches are not advised for openEHR but with new databases and DevOps tools it would be interesting to try such an approach just for the fun of it.
It would mean using the native features that databases like SurrealDB offer and expecting the full performance of the database engine. Basically to update the native schema description after each openEHR template is deployed and deploy the schema to the database. If everything is automated the clinicians wouldn’t depend on the IT (for them such an approach shouldn’t be any different as it is with the existing CDRs).
I know it is a crazy idea but it could be an interesting way to spend a few months on it – maybe as a proof-of-concept for presenting SurrealDB to the openEHR community. But @maxwell_flitton re-read this thread and read twice what @ian.mcnicoll says (the short answer is don’t do it ).
SurrealDB has some interesting features for the hierarchical data (a summary that might be relevant to openEHR from their site – @erik.sundvall also hinted on these in other databases):
As a multi-model database, SurrealDB enables developers to use multiple techniques to store and model data, without having to choose a method in advance. With the use of tables, SurrealDB has similarities with relational databases, but with the added functionality and flexibility of advanced nested fields and arrays. Inter-document record links allow for simple to understand and highly-performant related queries without the use of JOINs, eliminating the N+1 query problem.
SurrealDB doesn’t force you into setting up your data model in any one way. Instead you can choose between simple documents, documents with embedded fields, or related graph connections between records. Use schemafull or schemaless tables giving you the flexibility to store whatever you need. Once stored in SurrealDB, all data is strongly typed.
With full graph database functionality, SurrealDB enables more advanced querying and analysis. Records (or vertices) can be connected to one another with edges, each with its own record properties and metadata. Simple extensions to traditional SQL queries allow for multi-table, multi-depth document retrieval, efficiently in the database.
The primary method of querying SurrealDB is using SurrealQL, a similar but modified version of traditional SQL. SurrealQL enables linked documents to be traversed and queried efficiently, while still using an imperative language which remains understandable by data scientists.
SurrealDB can be run as a single in-memory node, or as part of a distributed cluster - offering highly-available and highly-scalable system characteristics. Designed from the ground up to run in a distributed environment, SurrealDB makes use of special techniques when handling multi-table transactions, and document record IDs - with no use of table or row locks.