I’ll just go out on a limb and say there are no fixed domains ![]() I’ve never even seen a fixed single app data set. Everything changes, all the time…
I’ve never even seen a fixed single app data set. Everything changes, all the time…
I’d like to disagree a bit here. I think FLAT and STRUCTURED formats + TDS + our own TDOs are covering different needs.
For example, within HiGHmed, we use TDS/TDD for data integration with Intersystems Ensemble and Mapforce
FLAT FORMAT has become quite handy for some app development and is used in multiple low-code tools like the ones provided by Better and Solid Clouds
We were able to build a full AQL query editor using our DTO model (+ AQL parser) and some more applications which require some stronger focus on backend processing.
Long story short: I don’t think there can be one single perfect format that will make everybody happy to develop software. Having the openEHR RM and Templates allows to make flexible transformations and tweaks to serve different needs.
Surely the openAPI approach would complement this by enabling some convenient support in multiple language. Hence, I think the situation has drastically improved since 2013 and an average developer is able to have their first “hello world” app up and running within 1-2 days. Not saying we cannot further improve but this is more about open educational resources and not the available tooling.
You reaffirm my point - those that invested their time in learning the openEHR data model and architecture, have no problem using these simplified data formats. The formats are useful.
Those that want to skip the learning part are usually not satisfied with any simplified data format. Even when the same format was successfully used by the developers from the first paragraph.
Summary: TDS/TDD is B2B-oriented; flat formats (and TDOs by the way) are C2B-oriented.
I think this diagram from a few years a go is still not a bad way to think about the various kinds of mappings needed to get from canonical-based formats to OPT-specific messages (TDD-type things) and micro-APIs (TDOs).
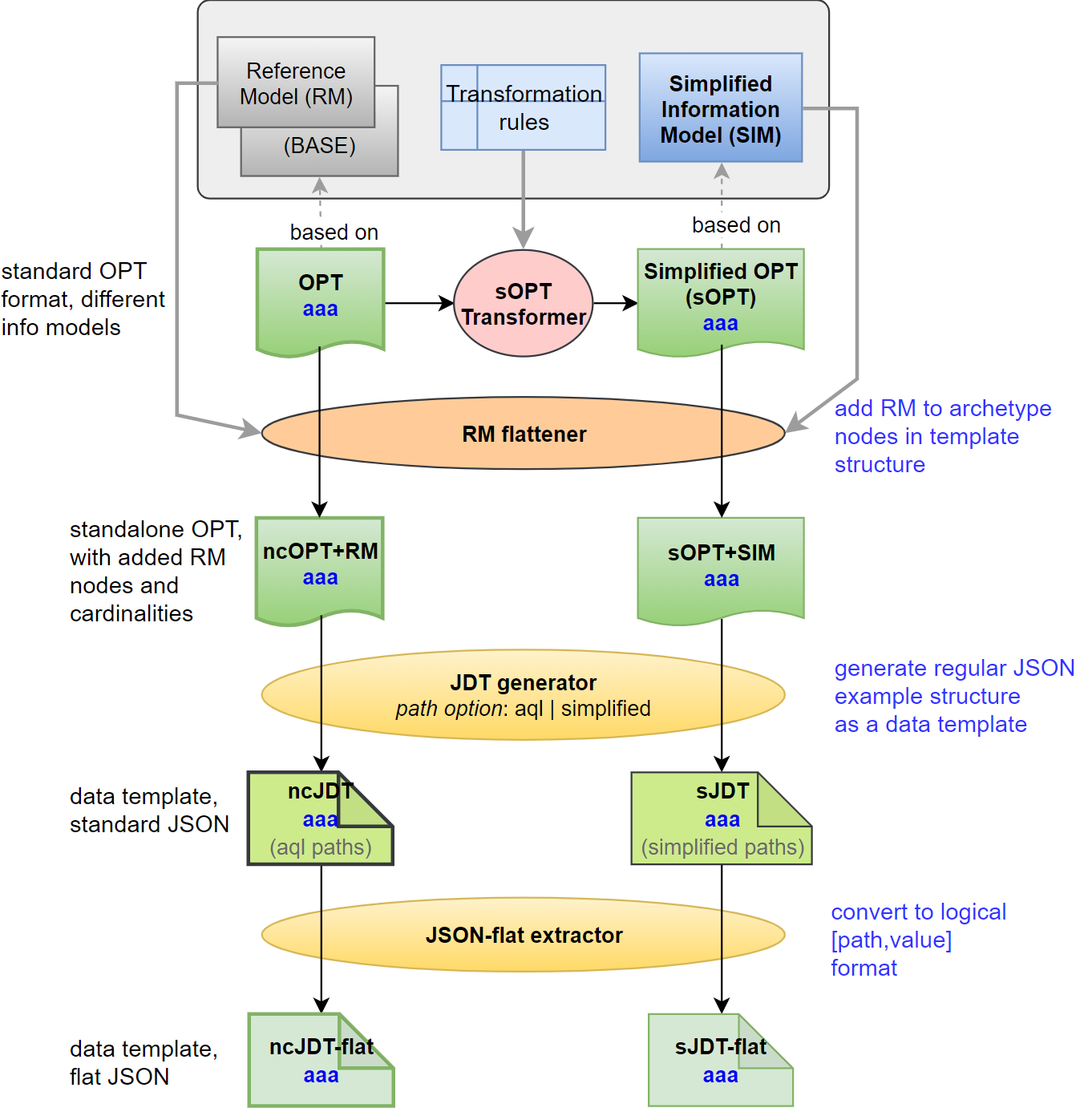
{kind=link}
Indeed.
Well I think we need a bit more tool chain in existence first, but that’s the idea for sure.
Yep. But they may not want to skip the learning; perhaps their employer never gives them time or space to go and get training on new methods. That is what is needed, as per my other post.
The big advantage with FHIR is that people are experiencing success very early. Once you bought into it (because it is deceptively easy), you are going down the rabbit hole. There is just no simple solution for health IT, this is more about perception and psychology.
@ToStupidForOpenEHR that is the canonical openEHR XML format for a COMPOSITION inside the VERSION object (a wrapper which adds versioning info to the clinical document), with a canonical JSON transformation applied (which is supported by the EHRServer to commit data, but is not a canonical JSON). That is why you see those @ attributes there, those are XML attributes in JSON notation.
If you check the new openEHR Toolkit , it provides a tool to generate canonical JSON, which is the same data but slightly different, and openEHR valid, JSON format.