@Maurice247 (and perhaps I) will present some things in a few hours, I just thought it might be nice for you to peruse at your leisure the colon FHIR questionnaire which is nearing completion.
Hi all,
This is great discussion.
Rather than modifying the agenda (which means re-sending the invite to everyone) we can start directly with the discussion here.
From my little understanding I think that the hybrid option would be the preferred. To have a generic core set of elements which are loosely modelled to capture different tumours and possibly slots for margins, IHC, or other elements that repeat at ‘title level’ in all tumours, but have very different data being captured.
This is really great
PS: I’ll take down notes to try to summarise the discussion
Style Guide for Diagnostic Archetype Design in openEHR
Introduction and Purpose:
This guide aims to provide a structured approach for designing diagnostic archetypes in openEHR. The purpose is to ensure that archetypes are consistently, accurately, and effectively modeled to represent diagnostic data, particularly in the field of pathology.
Requirements:
Completeness of data elements
Correct mapping of relations among data elements (semantic)
Standardization
Background:
Unlike clinical chemistry laboratory data, which primarily consists of name/value pairs, diagnostic pathology data is characterized by its rich semantics. For example, a malignant tumor requires detailed information such as morphological descriptions and specific tumor characteristics.
Structure of the Generic Archetype:
The generic archetype contains standardized core data elements applicable across various examinations. From these, more detailed and specific information is differentiated.
Checklist for Adding New Data Elements:
Generic Element Check: Is the data element generic enough for various examinations?
Multiplicity Check: Determine the occurrence of the data element (once or multiple times).
Grouping/Nesting Check: Decide how to group or nest the data element.
Data Type and Format Rule (Datentypen- und Formatregel): Confirm the data element’s conformity to established types and formats.
Example: Modeling “Malignant Tumor”
1. Generic Element Check:
Is the data element generic enough for various examinations?
Application: Yes, “malignant tumor” is a generic concept applicable across numerous types of pathological examinations, such as lung, breast, or colon biopsies.
2. Multiplicity Check:
Determine the occurrence of the data element (once or multiple times).
Application: “Malignant tumor” can occur multiple times within a single examination. For instance, in a lung biopsy, there could be multiple distinct tumors.
3. Grouping/Nesting Check:
Decide how to group or nest the data element.
Application: Each instance of a “malignant tumor” should be nested within the biopsy report. Further, specific information like tumor type, size, location and ICH results should be nested under each tumor instance.
4. Data Type and Format Rule:
Confirm the data element’s conformity to established types and formats.
Application: The “malignant tumor” data elements should conform to established medical terminologies and formats. For example, tumor size should be recorded in standardized units (like centimeters), and tumor type should use recognized classifications (like those from SNOMED CT).
I tried to keep it concise and hands-on using an example. The stage is open for feedback.
The Confluence site is where openEHR International publishes style guides, so it would have to be published there at some point anyway. And using a wiki may lower the threshold to comment or otherwise participate, compared to using Github
Also looking beyond relationships within an archetype we should consider how to connect data elements across archetypes. For example, radiology typically provides the tumor locations, while microscopy determines if and what type of tumor it is. This means all forms for prostate cancer like MRI, microscopic findings, lab results provides us with pieces of the puzzle. Like in the image below
To provide the full picture of e.g. prostate cancer we need matching at archetype/database level. I know many might think this is done through queries, but it’s not that simple. In radiology, there can be multiple PIRADS lesions, each has its unique finding in microscopy. If data elements have relationships across the archetype we need a primary key, e.g. the exact location. This would also enable for quality control. Our radiologists are very interested in knowing the actual results of their PIRADS predictions. I will put that in the style guide.
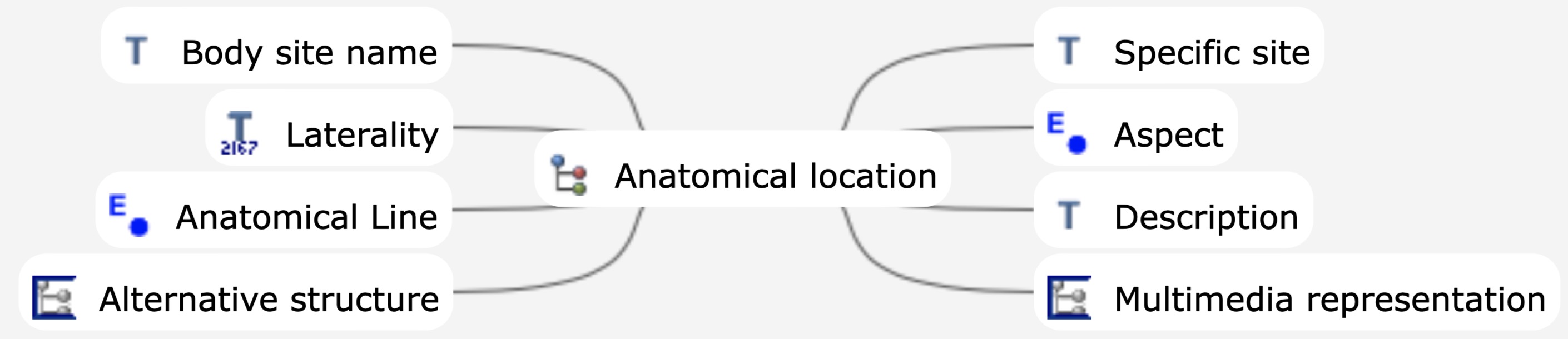
Match an anatomical location (probably SNOMED coded), by using the cluster.anatomical_locaiton archetype, that can be indepedently queried across ENTRY archetypes. e.g imaging, pathology. DIPS have done somewthing like this in opthalmology @bna ?
Add a specific tumourID or another pathway/journey ID for every interaction, either embedded in each relevant composition or use openEHR FOLDERS @sebastian.iancu -can explain how they use folders for mental health care planning.
Both Better and ehrbase are developing the option in AQL to look for Elements within archetypes that are labelled with a particular external code (this is similar to how FHIR Observation.code works). This would allow us to use term mappings on nodes to semantically label and query elements with e.g SNOMED that are internally coded differently.
Making progress on this but it might take a little while to establish the governance arrangements.
@erik.sundvall - can we start by creating the shared repo in the Karolinska Github repo (preferably on a separate Organisation), then we can transfer to openEHR in due course?
When I read Maurice’s post I also felt that anatomical site would be the first possibility for interconnection. Are we only talking about tumours? Taking prostate as an example: an anatomically defined lesion might be deemed PIRADs 4, but histologically only show inflammation. Would you still be able to / want to give that lesion a specific tumour ID, as you suggest? On the other hand, anatomy within SNOMEDCT still has some gaps and ambiguities (eg, thoracic lymph nodes). Would this last problem be addressed with your 3rd solution?
whom at SNOMED could we contact re the inclusion of S-CT codes in openEHR?
Scott Campbell at the University of Nebraska suggested the openEHR organisation get in touch with Jane Millar, jmi@snomed.org. Who at openEHR would know whether Jane or anyone else at SNOMED already has been contacted re our request? How do we take this further?
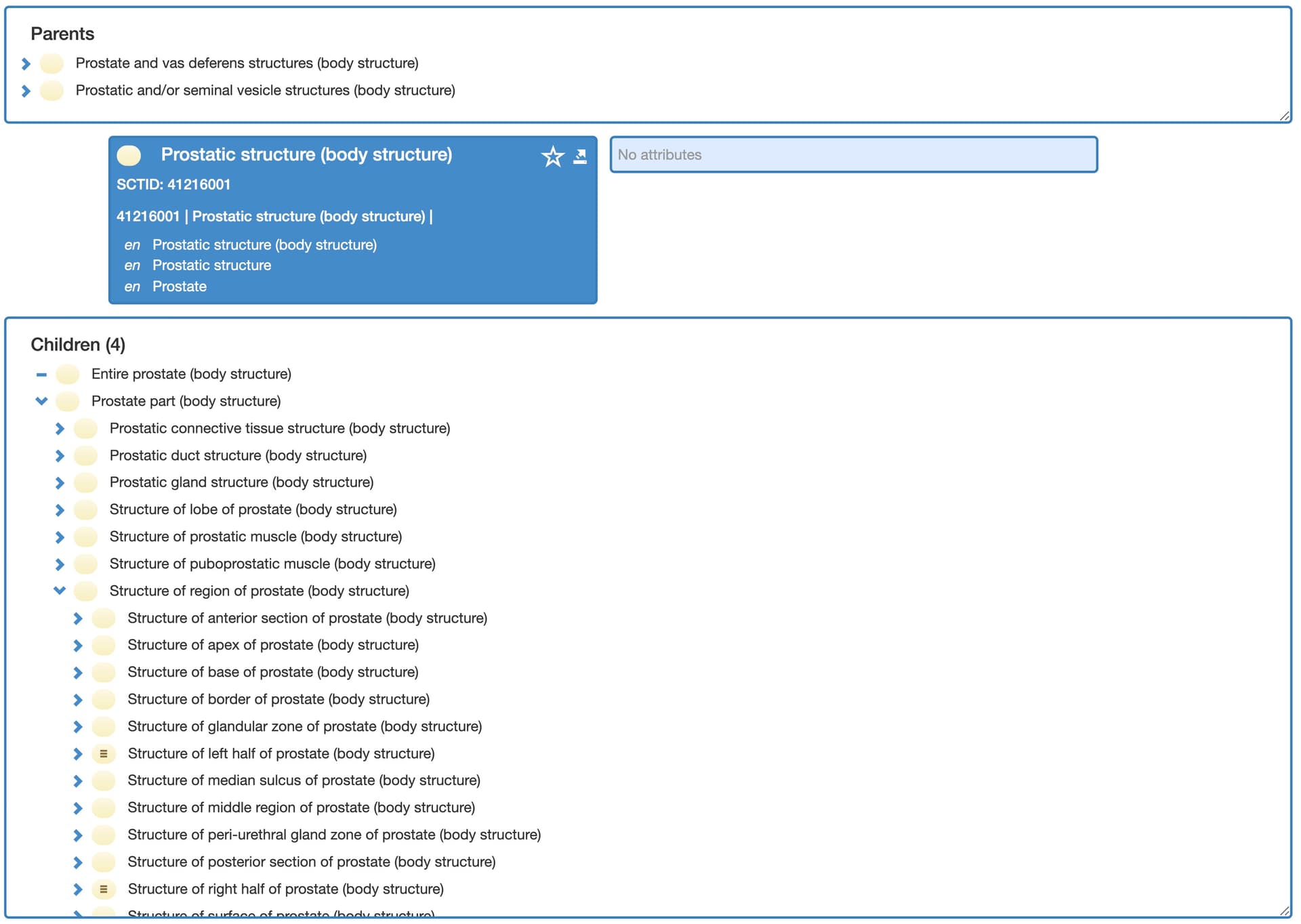
I agree with @SDubois, what we actually would need is a cancer ID since tumor can be anything. The problem is that you only know at the end if it was cancer. I think for solid tumors, the anatomical site can serve as the primary key to correctly assign findings between examinations, since it is unique. For example, a PIRADS lesion can only occur once in a zone. I also looked into archetype and SNOMED-CT, and I think if we use ‘body site name’ as a coded text and then utilize SNOMED-CT body structures. It’s granular enough even for the prostate.
For non-solid tumors, theoretically, it could be genetic changes, but we only know these at the end. Here, the specimen site would be appropriate since it is collected once and all tests can refer to it.
So far I only think I have (via mail to erik.sundvall@regionstockholm.se) been sent the Github username of @SDubois , and I believe I already know the id of @ian.mcnicoll, so others please mail your Github IDs to me (not passwords etc).
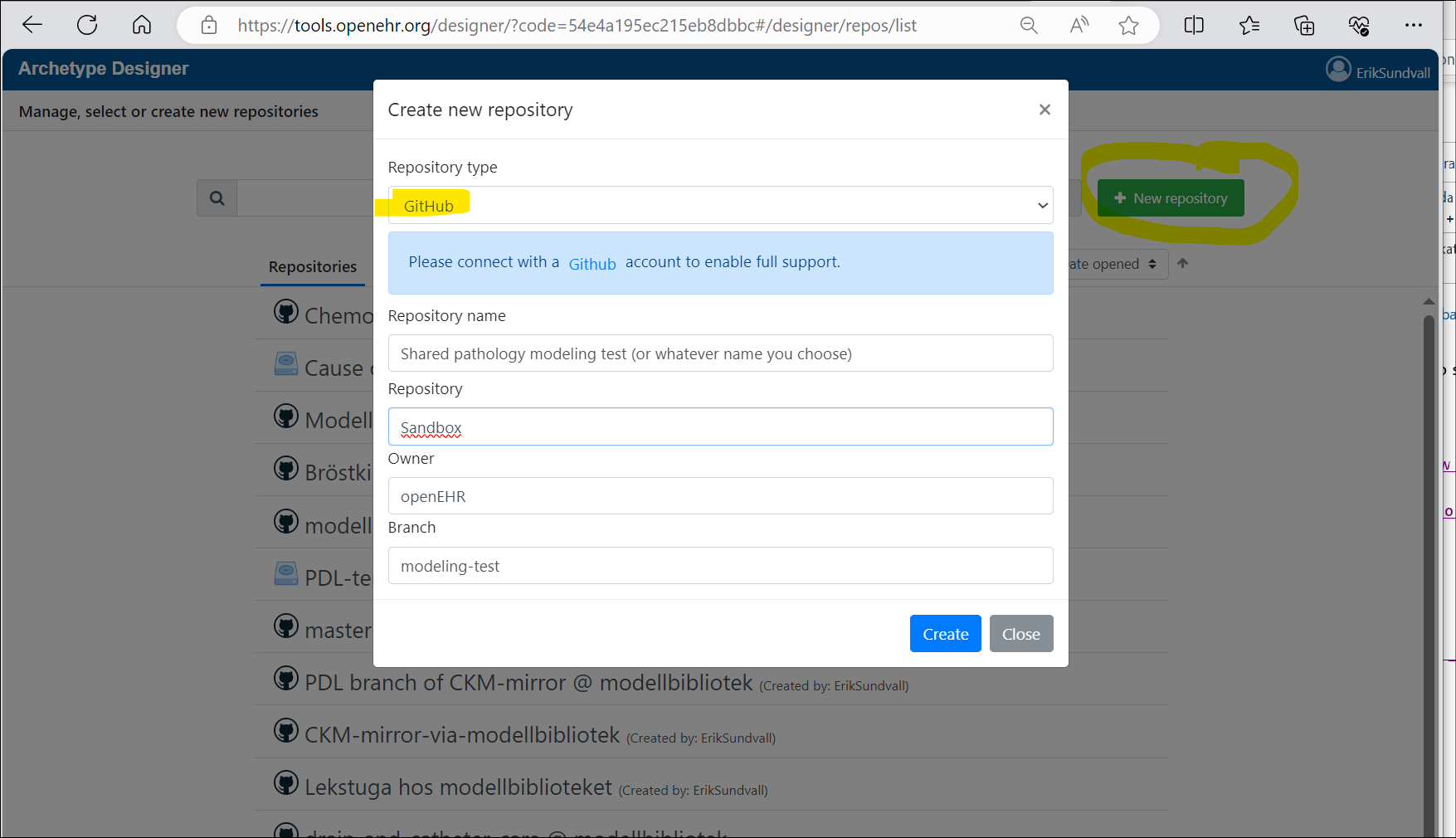
I think we could start experimenting with shared pathology modeling in a brannch and subdirectory of https://github.com/openEHR/Sandbox to figure out if that works, and then later move to a separate better named modeling project on Github.
There is now a test repository set up and, just for fun and furher testing, also the modeling-test branch to work in instead of ‘master’. You can connect Archetype Designer to this and hopefully start working:
RIght now it is pretty empty, but perhaps @siljelb or @ian.mcnicoll could import some relevant archetypes there to get us strted.
Things can get messed upp (overwritten) if several people save the same archetype /template in the same branch during overlepping timeslots. (Last save wins, but previous saves can usually be found as versions.) We may want to later workin several branches.
Anybody in the world can open/read files but as of this writing, the following have write (save) permissions:
Hi all, apologies for a very delayed reply.
Identifying the correct tumour in the correct body site and being able to associate all the documents to that specific tumour is something that we have been going over.
I think it all begins with a ‘lesion’ that at some point, with the pathology result, becomes a tumour. But in order to have the whole story it needs to be identified from when it was suspected.
There is an archetype that has been paused in its revision: Clinical Knowledge Manager (openehr.org) specific for lesion. Could that work as a glue-cluster to associate them if we added an ID?
And apologies @erik.sundvall, I thought I had sent my GitHub ID. I’ll email now