If somebody wants to create a mixed high-fidelity architecture, I’m sure they’re also willing to fund and guide the mapping efforts.
We first need to finish the basics like IPS and EHDS, unless this is done its a nice discussion.
Documentation is a thing, the data type mappings can fill 20 pages (“simple mapping guidance”), you need to manifest this things into tooling its way to much.
Also there is no single place for documentation i spend good amount of time collecting this stuff from everywhere.
This is why im pushing here for FHIRconnect also to collect these bits (@Ian_Bennett is currently working on a better integrated documentation).
I agree - all I’m suggesting is that we make it clear that the current mappings re suitable for low-fidelity scenarios and for ‘sharing out’ but highlight issues which might cause problems importing to high-fidelity envirnments. Important to get the initial work done with a realistic scope but also important that we highlight that is is not fully done (or possibly even doable) for all situations.
Agree, if you encounter this cases, please raise an issue on the FHIRconnect mapping library.
We will try to add more documentation for users, i want this “guidances” to just contain the bits that are the edge-cases.
So they get a standard set, but also the information how to deal with cases.
I will map this status.
How do we deal with the case users not having an exclusion and differential archetype in their template.
Imagine you map this against a template where people didnt think of an exclusion or differential archetype.
What should happen ? No mapping at all ?
Mapping it with a different status code ?
I enjoy your certainty, but it does have something to do with the clinical process, because the fact that something was wrongly asserted due to record keeping errors is a real fact of clinical relevance if/when it may or did lead to the wrong treatment. In such cases, the fact that it was asserted wrongly is a true fact that remains relevant to the care process.
If it was truly wrong and that was never relevant to the care process, then it would just be deleted.
This was our real process in the lab where I worked, btw.
Grahame
I agree, what tom isnt saying here we have an audit and version process to capture technical “stuff”.
The VERSIONED_OBJECT as an technical workflow, at least as far as i understand.
Which has change_types:
As part of the audit you can also provide a description:
It might be valuable to add “entered-in-error” in a more standardized way, rather than just as free text as part of a deletion.
But is deletion even the correct approach here?
As Grahame mentioned, an entry marked as entered-in-error could still have resulted in subsequent treatments that are linked to this (now “deleted”) object. I’m also wondering how to handle those treatments, they’re based on something entered in error, but they still happened and shouldn’t be considered non-existent.
Is it enough to link them to the “deleted” entered-in-error composition.
Also that would need to be made visible to the users.
and that is true but I think what Graham is saying (and I agree) is that in a disconnected message-driven system there is not necessarily a clean technical approach which can safely say - entered-in-error notification → automatically just create a DELETE/UPDATE in openEHR.
Ultimately that is where it will probably land, but I would expect some sort of clinical review in most cases, except in simple secondary uses read-only/registry.
So both perspectives are IMO correct.
-
If you want to properly redact an erroneous record reported from elsewhere, it is not as simple as just setting an Entered-in-error attribute on that record if it is going to be used for ongoing care especially if it is some sort of primary record.
-
Re-versioning the record as per openEHR is IMO a much safer way of managing this, but equally in many case re-versioning/logical delete etc is not likely to be a wholly automatic process in the context of what is essentially an external notification of error. And that will also happen in openEHR between CDRs unless they are already very tightly co-governed.
It’s not that it’s not a real thing (erroneous data entry) it’s just that ‘entered-in-error’ is not a possible value of the status of a clinical diagnosis. It is a possible reason for a new version of some data (i.e. ‘error correction’). The way it is done in the HL7 term set is mixing two completely different aspects of real world activity into the one value space.
Sorry to be late to the conversation.
’Refute’ - my local FHIRman, Brett Esler, tells me “I think refuted is, like most things, not very well defined so expect it is used in all ways including both stating a negation without a prior assertion or negating a previous assertion…”
To make an assumption of mapping our archetype values to one definition or the other seems dangerous and if we don’t clearly know the intent it should probably not be mapped from a clinical safety point of view. openEHR exclusions are only valid at the time of recording and negations of existing data has a whole lot of other implementation/workflow implications. Feels like a red flag moment to me.
’Entered in error’ is something we all need to do all the time. In openEHR systems it is usually part of the implementation ie a reason for ‘removal’ of a record ie effectively inactivated. In messages it is another important piece of information, but feels uncomfortable to conflate to a ‘Status’ as done in FHIR; it has never been modelled in any of the archetypes.
Another is to align the two approaches.
I certainly see inconsistency in our archetypes that could be improved eg Adverse reaction event CLUSTER has values of:
-
Unconfirmed [It has not been objectively verified that the ‘Manifestation’ in this reaction event was caused by exposure to the identified ‘Substance’.]
-
Confirmed [It has been objectively verified that the ‘Manifestation’ in this reaction event was caused by exposure to the identified ‘Substance’. This may include clinical evidence by testing, re-challenge or observation.]
-
Refuted [It has been disputed or disproven that the ‘Manifestation’ in this reaction event was caused by exposure to the identified ‘Substance’, with a sufficient level of clinical certainty to justify invalidating the assertion. This may include clinical evidence by testing, re-challenge or observation.]
Diagnostic certainty in EVAL.problem_diagnosis has the values of:
-
Suspected [The diagnosis has been identified with a low level of certainty.]
-
Probable [The diagnosis has been identified with a high level of certainty.]
-
Confirmed [The diagnosis has been confirmed against recognised criteria.]
There are others.
We’ve known these qualifiers are messy for a long time, and put it a lot of work already, but we can probably do even more to improve the situation. Careful documentation of each of these inconsistencies and issue provides us with more context of the problem that needs to be solved. There are many qualifiers/statuses that are used loosely and inconsistently. Here is a chance to align the FHIR/openEHR approaches and to improve future data.
I suspect if we can deconstruct these qualifiers, present them in a logical manner with each separate axis identified and defined and justify the differences, clinicians would potentially agree and use these terms more specifically and consistently. It would be a global public good! ![]()
I know we’ve tried this previously with the Problem/Diagnosis qualifier and we definitely made progress within that single archetype, but now we’re confronted with similar value sets in other archetypes and in FHIR models. Perhaps we now have the context to make better choices and definitions and offer guidance on how to use the terms better. Then building semantically consistent mappings also become easier.
It seems to me that we have a number of choices:
- Build CLUSTER archetypes that are purpose built for FHIR status integration but will create at least some level of openEHR/clinical semantic/technical debt eg for ‘entered in error’
- Long term: Work on better designing this messy data, get clinical consensus, lead by identifying best evidence clinical practice/definitions and potentially influence FHIR resources/profiles.
- Short term: Map between existing FHIR and openEHR artifacts. Some are clear mappings and clinically sound, some are not. At the moment it feels like we are dealing with a number of square peg, round hole situations and this is a red flag moment for me. Maybe it is a practical short term solution but it comes at a cost.
No, I like the way you are thinking. We can do better, I think.
I think this will give us the best long-term outcome though!
Thanks everyone, I think this discussion is really important and I hope we’ll find the time to draw some conclusions from it.
@ian.mcnicoll Just to go back on my suspicions that people may be mapping “Suspected”→ “Provisional”:
I suspected this was happening in germany so I had a ook at HL7 Germany’s base profiles:
Translated screenshot:
My point is only to illustrate that depending on the source FHIR’s “provisional” may have been “suspected” before the initial mapping, so at least in germany mapping “provisional” to “probable” is best avoided.
I would agree that “entered in error” describes another dimension/axis compared to the other items, but as @heather.leslie said it’s not the only overlap of axes in the same valueset we’re dealing with here
These elements with cardinality 0..1 frame these terms as if they are mutually exclusive, even though in reality they are not, and they partially overlap:
- Most differential diagnoses are also provisional, and also unconfirmed.
- Probable diagnosed are also usually suspected.
- Working diagnoses are usually also preliminal, (and provisional, and unconfirmed, and suspected)
Having just one element with 0…1 is a bit as if I saw an animal hush past in the night and I would then be asked “did it have four legs OR was it grey OR did it hiss at you?” and I had to pick just one.
Seems fun to try!
This is my attempt to map out the qualifiers, just aligned to openEHR’s ontology, not to any specific archetype:
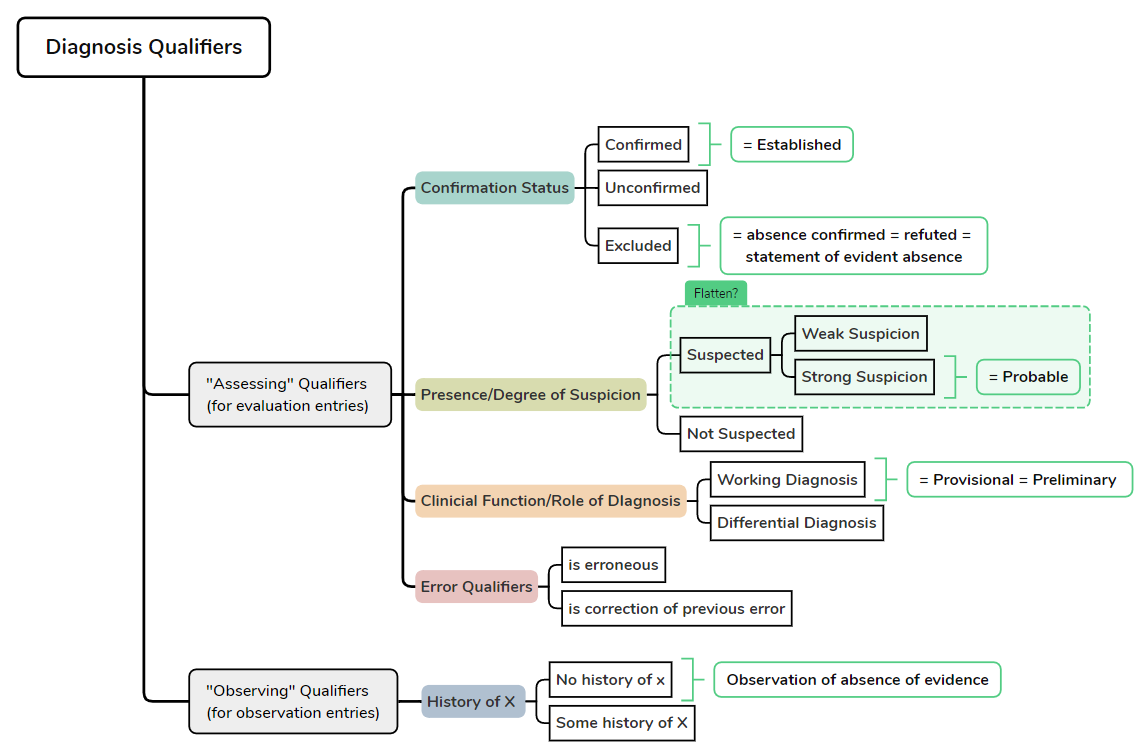
So the main axes would be:
- what has been confirmed?
- what is the degree of suspicion?
- what does this diagnosis serve as in our clinical reasoning? (working/differential)
With this perspective if someone were to tell me “our working diagnosis is Meningitis” they are really telling us about three axes:
Diagnosis Name: Meningitis
Confirmation Status: Unconfirmed
Suspicion Status: Suspected (not known if strongly or weakly)
Clinical Function: Working DIagnosis
I know it’s unusual to think of a diagnosis being “suspected” and a “working diagnosis” at the same time, but the minute I stop suspecting my working diagnosis it stops being my working diagnosis. Plus it was already confirmed I would not call it a working diagnosis.
Furthermore the above schema would keep the following concepts apart in the correct entry types:
- Opinion that Diagnosis X is not present based on available evidence = “statement of evident absence” = exclusion (strictly speaking) = OK in Evaluation Entry
- Statement by somebody or something that there is no known history of Diagnosis X = “Observation of absence of evidence” = strictly speaking not an exclusion = Observation Entry → Screening-Questionaire Type Archetype
Just to clarify I’m not disagreeing with the use of the Exclusion Evaluation Archetypes, my understanding is just that they’re not the right entry type for “no history of X”, even though currently their use statements contain multiple such examples.
I think it’s a good idea to break this problem down into different axes/dimensions to solve it.
I agree with Lars — in general. Apart form that I find the exclusion archetype problematic. It does not really align with the usual modeling approach (i feel). Typically, we want all information related to a clinical concept to be part of the same model. This allows for researchers and clinicians data being process using a single archetype (e.g., problem_diagnosis) and expect all relevant attributes to be located there (or as part of clusters).
The exclusion archetype instead introduces a terminology-based mechanism. In practice, this means I may not know whether a diagnosis (or any other clinical fact) is explicitly excluded for a patient group unless I know the exact code or unless that exclusion is attached to the exact template I am querying. Otherwise, I have to retrieve and resolve this information separately with the help of an terminology server (find all exclusions having diagnosis codes in SNOMED, ICD …).
This shifts the model toward a terminology-driven representation — similar to what is done in FHIR or OMOP — where meaning depends on code lookups rather than the structural model. In situations where the correct code is unknown, or where access to a terminology server is limited, processing such an archetype becomes difficult and, in my opinion, unreliable to some degree.
I rather would have it as an cluster that i can attach in an archetype as an example (something more generic as @Lars_Fuhrmann did, so we can use it everywhere e.g. also to exclude that a patient has a pacemaker, something you do in cardiology). That would at least provide a standardized slot in an archetype where it also resides as part of the archetype in an composition instead of apart of it.
Anyhow, this has the downside (apart from going against whats established) that if i just check for diagnosis without looking at the e.g. cluster, i will also retrieve refuted diagnosis.
But im sure im also missing something.
The minute you add some sort of ‘negating flag or structure,‘ to a diagnosis archetype, you run the risk of a negating statement being confused for a positive statement, just because the querying party does not include the negating attribute/structure in the query.
So Problem = Meningitis can easily be confused with Problem = Meningitis Negation: True. That is where I think for now, we should be using the specific exclusion archetype: rule-out diagnosis. In almost every other scenario where negation is needed, the screening questionnaire archetypes are now more appropriate. I don’t think we need specific exclusions now, apart from the rule-out diagnosis example.
However, I agree in principle that it would be better to handle ‘rule-out diagnoses’ more elegantly. I’ll post separately on an idea I had on this.
Just as a heads-up, there is ongoing work to revise the “Exclusion” archetypes. Perhaps @KBarwise could outline which changes are currently suggested?