I would like to explain more of the mentioned use case and the questions that come to us in the process of trying to chose the correct way to model.
Is it correct to use the same archetype in two Templates in the same information system? In a Template with persistent composition spirit and in a Template event ?
I understand that it is one thing to use the same template more than once in different use cases, or in different information systems. But, if two or more Templates that make up a single clinical workstation and are related to each other, do we consider it to be ONE use case?
Let’s say we are modeling a Clinic Workstation. This station would cover the need for a primary care consultation. The healthcare professional has an assigned population group. She/he regularly visits his/her patients, gets to know them and manages their health problems throughout their lives. She/he jots down notes of his/her performances at each visit in a clinical course. Associated with this clinical course, the healthcare professional manages, medication, diagnosis record and makes requests if necessary.
In the process of structuring the information of this clinical workstation, it is divided into different projects that cover the modeling of each of these areas. This results in a project that models requests, another project models the diagnosis record and another the clinical course .
This generates, in principle, a Template for each of these functionalities or modules. A Template for the course, a Template for the requests, a Template for the list of the patient’s diagnoses throughout their life.
Many of the clinical courses are associated with one or more diagnoses .Requests also require a diagnosis (or a suspected diagnosis) to be processed and of course a medication must be associated with a diagnosis.
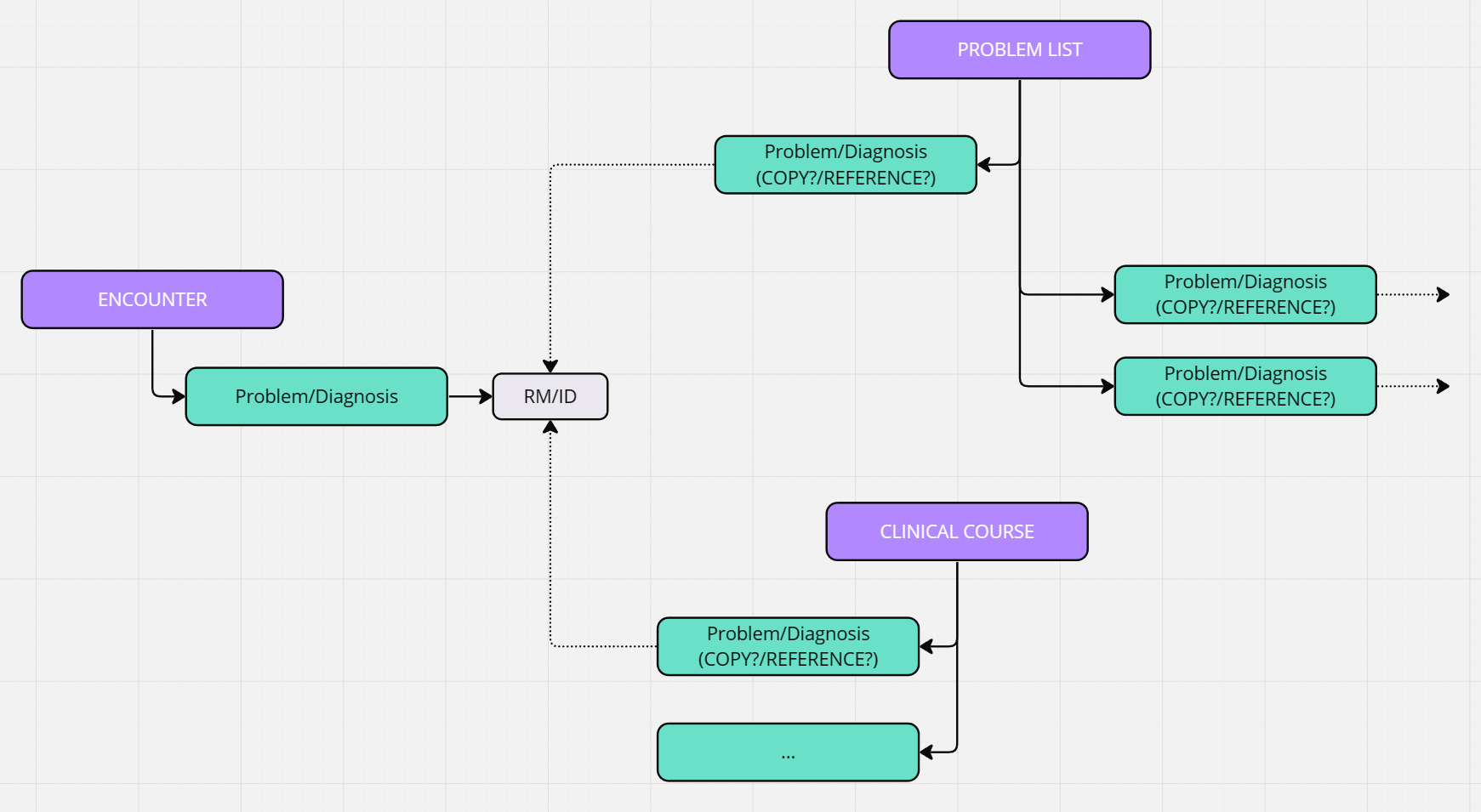
In the legacy system where we come from, (relational databases) a table with diagnoses is persisted, each with diagnosis_id. When a clinical course was carried out, that table was associated with its corresponding id, but the information was NOT saved in two tables at the same time.
But what about OpenEHR, which is a documental database? There may be inconsistency of information if in some way we persist the information twice in different places of the same information system ?
I’ll explain it in another way with an exemple:
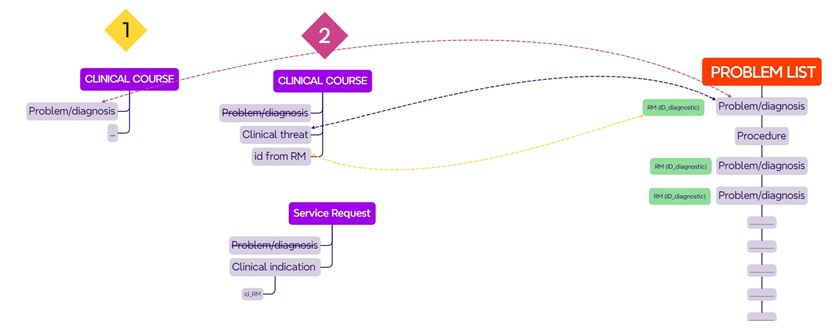
Do we have to persist a Diagnosis alongside the clinical course and also in a Problem List (with the same problem/diagnosis arquetype in both)?
See model 1 of the scheme
For the way Instruction and action Archetypes are designed, makes me doubt of it. Those are solved with a reference to this diagnosis, without the problem diagnosis archetype, instead they use an element (text) Clinical indication. So it makes me think a better approach wolud be the model 2 of the scheme.
Wich is the correct approach to model this use case ? Any other options ?
Thank you in advance for your time. I hope someone faced this situation before and can bring solutions to the puzzle.
Postscript: We consider making a runtime aql to call a list of the registered diagnosis of patient, in order to select one to fullfill the clinical threat / clinical indication, but whe guess this will be too much requirement for the system.