Some originally paper based scores or scales use mixed data types or explicit choices which evaluate to a NULL value. One example is the NANO scale, which uses this pattern for all its elements:

The first four values here would fit right into a DV_ORDINAL, but the final two do not. We’ve been discussing this pattern, and come up with a set of possible solutions, one of which modelling-wise is elegant, and four which … aren’t.
- Constrain the
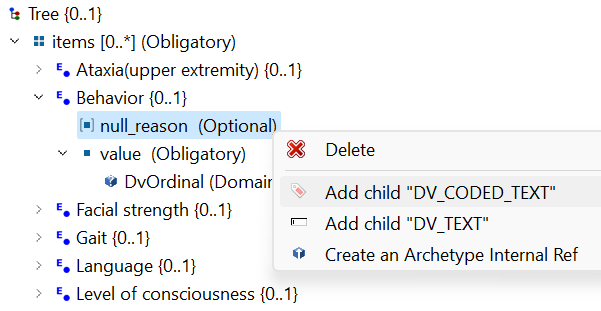
null_reasonRM element in the archetype, to be a DV_CODED_TEXT containing the two “Not assessed” and “Not evaluable” values. This looks to us to be the most elegant solution, but AFAIK it’s not supported in any modelling tools, implementations or the CKM
- Represent the final two values using a ‘0’ as the ordinal value. This would be simple to model and implement, but is wrong with regards to the data we’d end up persisting. We don’t want to risk mixing up ‘Normal’ and ‘Not evaluable’

- Separate the two outlier values into a separate data element with a DV_CODED_TEXT data type. This would require the UI to do some smarts to make sure only one of each pair of DV_ORDINAL/DV_CODED_TEXT is persisted. A variation of this is to put them both in an internal cluster with cardinality
1..1, to make sure only one is ever persisted. This solution is clunky and puts a larger workload on implementers
- Make the entire data element a DV_CODED_TEXT where the first four values have the codes 0-3, and the final two either NULL if possible, or a letter code if necessary

- Make the element a choice between DV_ORDINAL containing the first four values, and DV_CODED_TEXT containing the final two. We don’t know whether current implementations support constraining a choice data type at run-time, so this could possibly be unimplementable

Options 3-5 also adds the complexity of having to make up and insert into the archetype a small “external” terminology, since internal codes in a DV_CODED_TEXT is limited to at-codes as the code values. This also isn’t very well supported in modelling tools ![]()
So we’d really like some input from other modellers, implementers and specifications people. How do we solve this conundrum?