Strictly speaking this is an AOM discussion not RM but here goes!!
While reviewing the OBSERVATION.age archetype, I was reminded of the perennial issue around whether we should model some concepts as Entries or Clusters. We do have some god guidance on this now but it can still feel like an awkward choice at times.
I’ve toyed with the idea of ‘virtual Cluster’ archetypes e.g an Observation archetype could expose part of its structure as a Re-useable Cluster archetype, alongside the parent Observation, and the Cluster could be -re-used in templates.
I have no idea if/how this might be possible but I wondered if there is any appetite for exploring further.
One thing we are doing in Graphite is making much greater use of direct references, and less use of archetype slots. We’ve analysed the openEHR archetypes with a tool - a majority of slots just point to one archetype (possibly in more than one version). Converting those slots to use_references makes a huge difference to direct archetype re-use, and also greatly simplifies template design.
I think the “normal” way of just modeling structures as clusters and data+context(e.g. state)+protocol+time series as observations.
That idea of “exposing” parts defined on higher level archetypes as lower level archetypes could open the door for bad or lazy modeling. Why do a modeler would bother to create a cluster archetype and then an observation archetype if they can just create an observation and expose the cluster?
Also you need a virtual archetype ID for that cluster so other archetypes can use it.
Another thing is archetype dependency management can become a mess really fast, because instead of a dependency tree you end up creating a complex graph.
And a final area that I see messy is archetype search. With virtual archetypes you need to search inside current archetypes to find the exposed internal structures. This requires more resources, complicates searches, and at the end implementations would just have a copy of the exposed archetype in a cache, which is like having the original cluster archetype as an individual archetype, so why complicate things if we will end up with the cluster being materialized either way?
My criteria is:
if the concept is just a structure and doesn’t need protocol, state, time series, etc. it’s a CLUSTER.
if your concept needs any of those, then it’s an OBSERVATION.
This is true. Although for a lot of those slots the intent isn’t to constrain the slot to that archetype only. We’ve tried excluding all other clusters once, and had to change it not too long afterwards.
There are times where it can be difficult to decide whether a model should be an Entry, usually an Observation, or a Cluster.
A good example might be diagnostic grades/ staging scores where in some contexts the data is closely linked embedded within another Entry e.g diagnosis but in other circumstances it might need to be stand alone and needs to be wrapped in some sort of parent Observation, perhaps a dummy container type archetype.
Another might be Inspired Oxygen which makes perfect sense as a Cluster but sometimes e.g. in a
NEWS assessment probably lives more naturally as an Observation alongside the other components.
The idea was to be able to markup a fragment of an ENTRY as being a re-useable fragment , so could act as a CLUSTER but would be managed/published as an integral part of the ENTRY. Tooling would ‘see’ the CLUSTER but it would not actually exist as an independent artefact.
I think the original Goal archetype had a similar idea where the ‘Target’ could be expressed as an ADL fragment, so that e.g you could use the Body weight quantity constraint inside a Goal.
I suspect Pablo is correct that this might cause more problems than it solves but I’ve got it off my chest now!!
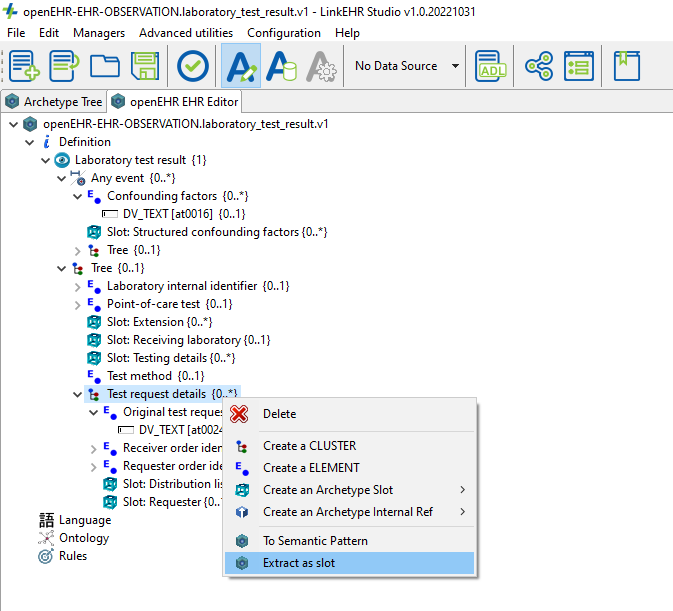
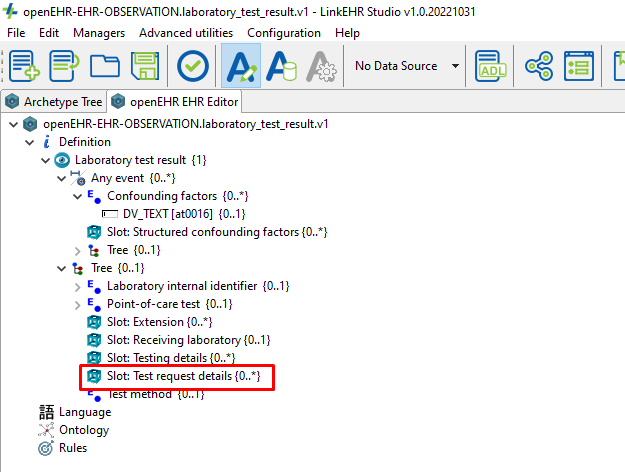
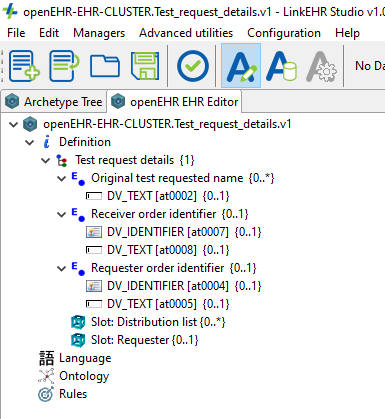
@ian.mcnicoll in a case of having an OBSERVATION and then realizing a part could be reused by another archetype, we need to have a proper archetype refactoring process that allows to extract the common part to another (CLUSTER) archetype and don’t break the original OBSERVATION archetype.
Is like what we do in code. We code the first time for a certain functionality to work, then we add functionality and realize we can reuse part of the existing code so we refactor that part to an specific method that can be reused by other parts of the code, without breaking the original code.
In the archetype world that would mean that extracting part of an archetype and then declaring a slot shouldn’t be a breaking change for the archetype so the major version shouldn’t change, though I’m not 100% if the paths of the refactored archetypes will be consistent with the original paths. Might need some extra analysis.
This I would definitely support! We have just this kind of use case for the Medication order INSTRUCTION, which has some rarely used internal clusters which could be better placed as CLUSTER archetypes. But the archetype is already at v3 and there’s no other incentive for making a breaking change.
Tooling support to refactor absolutely, but unfortunately, I don’t think we can avoid the breaking change- although the CLUSTER 'shape is identical, it’s root node in the OBSERVATION archetype will be an atCode but a proper archetypeID in the CLUSTER archetype.
My otherwise possibly stupid suggestion would fix this!! i.e the cluster could remain as internal but also be used as a separate CLUSTER
I feel your pain. The challenge is that there is no way around. I believe the only current solutions are:
extract the CLUSTER archetype and migrate the rest for any changes on paths or node IDs (I think smart modelers will not change the node IDs in the CLUSTER, reducing the impact of the migration)
duplicate the same structure in a new CLUSTER archetype, not ideal but works, and in the future the original archetype could be migrated for reusing the new CLUSTER.
You can use a direct reference (use_archetype), which is what is used to fill a slot. But you don’t need a slot to use a use_archetype - just use it where it is needed. This is what should be used in a lot of cases, and relates directly to the discussion here - the use of re-usable sub-trees of information.
Using direct references makes templating a LOT easier, because (in ADL2) a use_reference is expanded out in the template flattening process, and all those places where you have things like Device inside BP measurement just expand out with no extra effort.
This mentality corresponds pretty much with how Pablo described re-use & refactoring above.
Mmm that will break all the existing paths, would be less impactful if the original at codes could be kept in the extracted archetype. I don’t think there is a hard requirement to have the concept ID to be at0000 in archetypes, if there is, I think that should be relaxed in the AOM.
If you refer to any existing ADL path pointing to the archetype, there will be always an impact when we extract a substructure, even if we keep the node ids. As the substructure becomes a new archetype, the path would need to change the node Id of the root object to the new archetype Id. Of course, if we keep the other ids, the ‘tail’ of the path does not change and the impact is more limited.