In terms of clinical modeling (Archetype/Template design), how to return/transfer as much clinical complexity as possible to clinical terminologies/ontologies in order to reduce the complexity (therefore difficulty) of openEHR artefact modeling (Archetype/Template design) and increase reusability (therefore popularity) of openEHR Archetypes/Templates?
IMO, one of the reasons why such a question is asked is there would exists no crystal-clear borderline between openEHR Archetypes/Templates and clinical terminologies/ontologies.
There have been regular attempts to push the efforts into ‘ontology’ see TermInfo
and I have to say it has not been a great success.
Mainstream thinking is now actually the other way. Let Information models (which are just a different type of ontology) do the heavy lifting of establishing record structures and context but use ontologies to link out to real-word entities - diagnoses, procedures, symptoms etc.
Basically use ontology/terminology for the ‘is_a’ relationships but use defined information models for the ‘has_a’ relationships.
Thanks, @ian.mcnicoll. Very glad that you’re addressing this topic. I’m looking forward to further progress.
For the topic about virtual clusters, my initial thinking is that data points should be included at first as cluster members to allow for full composability/reusability. Then the others (Archetypes and Templates) are built with these data points. But what about the groupers (similar to LOINC panels) of data points?
Consider the representation of anthe daily personal running session data that is used as an example scenario for my recent template design exercises. In the international CKM, the existing published/active Archetypes are apparently not covering my model requirements. Most usable data points related to running come from an experimental project’s proposals. See @erik.sundvall’s topic on Physical activity data modeling project for details.
But if HL7 FHIR is used, maybe it would be easier although this is just my imagination for now. For example, FHIR resources such as Composition and Obsevation, and a local observation terminology similiar to LOINC could be used to author the instances.
FHIR Observations +LOINC handle very simple key observable elements pretty well but it all starts to get very messy once you add in more ‘supportive’ elements like body position, device location etc. So neither is perfect. Remember too that archetypes carry quite a bit more metadata than LOIN or plain FHIR resources - min, max limits, units etc.
One option to fill the gaps,and also help with similar integration scenarios would be to create an OBSERVATION archetype that is very generic but where the observable is identified by an external code like LOINC or SNOMED.
Both Better CDR and Ehrbase now allow queries at ELEMENT level, independent of the parent OBSERVATION, so a generic Observation could be cross queryable with ‘proper’ archetypes as long as the data was tagged with the same LOINC codes.
We might go further in the future by having a special class of OBSERVABLE ELEMENT archetypes that could be included directly in a parent. ADL2 makes this very feasible since it support direct references - kinda like pre-filled slots but without the need to specialise or create a template.
I suspect we need some way of supporting both. Simple Element ‘independent’ level definitions for observables particularly for easily consuming data from external sources, but the ability to formally define these within the context of a specific archetype, as many of the associated elements are not really Observables e.g comment, method, cuff size, body position, and they all have their own OPbservation specific constraints.
but in essence, I think you are right that we can possibly do something that is a bit more scalable and adaptable, without giving up the valuable current CKM maximal dataset approach to documenting and defining Observation components.
According to my own experience and understanding, the existing Archetypes based on this approach often haven’t reached their max levels, in terms of both data point quantity/diversity and structural flexibility/expressiveness.
Absolutely - the maximal dataset is a journey not a destination but it explicitly scopes the data model of an Observation not just in terms of actual ‘observables’ like ‘systolic’, diastolic’ and ‘MAP’ i.e key datapoints that one would query on adorectly, but along with qualifying datapoints like ‘location’ and ‘cuff size’ and long with their constraints for that specific Observation e.g. Pulse and BP both have ‘location’ but the allowed locations will be very different.
but agree - we should always be open to slightly different approaches. ADL2 does open up some interesting possibilities.
We can and do model that way. See questionairre patterns for example.
But in principle i agree there may be a case for an generic observation archetype, as long as we can figure out how to keep cross querying with proper archetypes possible we need both.
On a very general level I agree, but I really think that we sooner than later should try to create a modelling guide for the intersection between openEHR archetypes and ontologies (SNOMED CT and others).
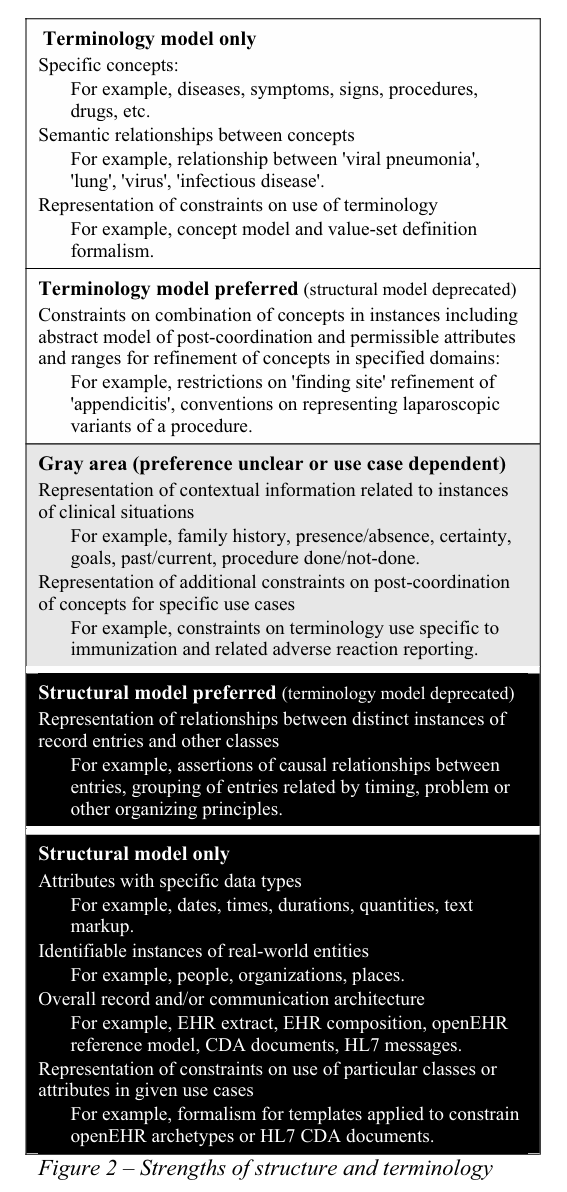
For me, this publication from 2008 provides a very good framework on how to decide between modeling information structures or using terminologies/ontologies. It is just a generic guidance but it is worth reading.
Markwell, D., Sato, L., & Cheetham, E. (2008). Representing clinical information using SNOMED clinical terms with different structural information models. En CEUR Workshop Proceedings (Vol. 410, pp. 72-79).
I should add that it is a very good paper in describing/defining the different aspects that need to be considered. Heather, Sam and I were involved in some of these discussions at that time.
However, experience has, I think, taken us much more down the road that terminology is best used to handle the is_a relationships between biomedical entities, and structural models are better placed to apply modifying context like /family history, as well as attribution against the core data points like ‘procedure approach’.
With the current available tooling for openEHR I might agree with @ian.mcnicoll. With more integrated tooling for openEHR and ontologies, like SNOMED CT, I agree with @damoca. (And I hope that we sooner than later can have the more integrated tooling.)