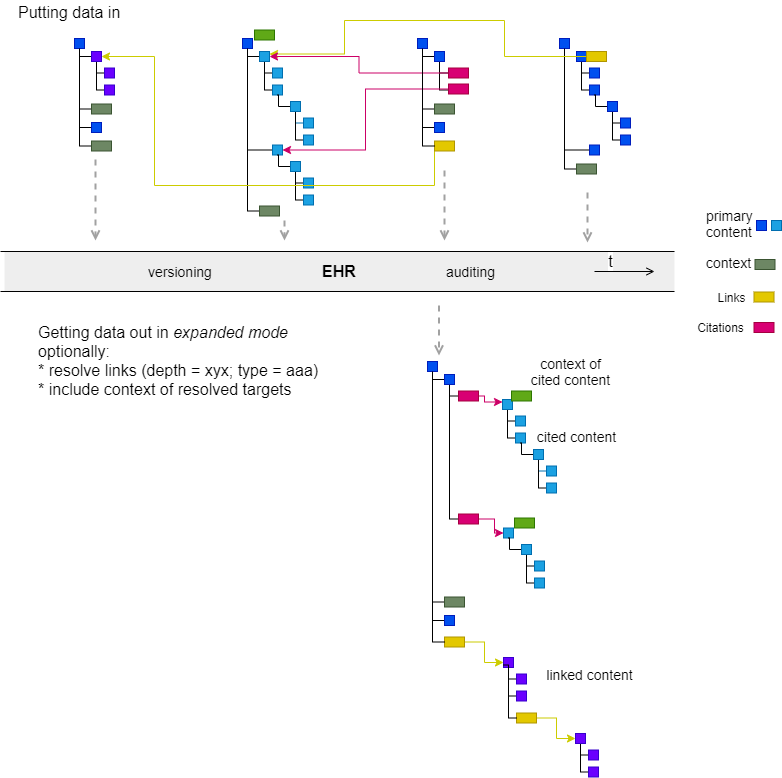
Currently in openEHR, we retrieve data in the same structures it went in, either:
as the original COMPOSITION, ENTRY etc, via a direct get from the REST API
as a list/table of pieces, within an AQL RESULT_SET
Neither of these modes performs two things that would be convenient in many circumstances:
resolving Links / Citations
attaching context of matched items
An obvious use case of when we would like this kind of behaviour is the managed list, i.e. Allergy List, Problem List etc. The most common retrieval today is a series of retrievals to out the List together, when really the app dev would like to just get the logical list in one hit. I.e. like this:
Managed Lists are not the only time when Links could usefully be resolved - you might want to materialise out a chain of Obs → Dx → Rx → Action.
We should potentially consider a general solution to this problem that works in both direct retrieve and AQL modes, and allows some control over:
how deep Links are followed
which links should be resolved and which not, based on type and meaning field
whether context should be included with resolved Link targets.
We can think of this as expanded retrieve.
If we distinguish Citation as a special kind of Link for ‘quoting’ other content, as in managed lists, then a common expanded retrieval mode would be ‘retrieve, resolving all citations’.
I’m not sure that we need to worry about depth of links (other thank perhaps as an escape from recursive links. As long as we can be explicit about wether a link should always be followed in the context of an ‘expanded mode template’, the template should define where the links should be resolved automatically, and where they are left as "it is over here if you want o it but you will have to go and get it yourself’!
For context, I still like the idea of a function associated with each entry that allows easy access to the composition context, and other key parts of the parent composition. I think this is much easier and more flexible than creating another ‘shadow’ set of context-flattened classes.
ENTRY.parent_composition().composer/name/value
You can do that with AQL directly of course but it starts to get confusing if you have multiple parent compositions. or indeed ENTRY.parent_ehr()
Not just recursive - just long chains that you might not want to follow. Ideally, a condition would be used to stop following, e.g. only follow where type=order-tracking or somesuch.
Do you mean a function literally in the Entry type? This would not work technically, because Entries don’t know anything about the APIs they are retrieved through - they’re just passive items. (Knowing such things breaks a standard IT golden rule of internal objects not knowing about the larger objects or systems that contain them, which creates fragile systems).
By the time an ENTRY has been retrieved to the client space, a function like ENTRY.parent_composition() cannot resolve anything above itself, unless that thing is already there. That can be achieved by doing a mode of ‘thin’ retrieval, which you may be thinking of (and I also like), which is:
imagine a COmposition C1 has 4 ENTRIEs in it, say 2 x OBS, 1x EVAL 1x INSTR
now, you request some other Composition C2, containing a Citation (say) pointing to C1.EVAL1.
the ‘thin’ mode of retrieval will get:
C2
Citation
C1
EVAL1
i.e. the EVAL1 wrapped in its original C1 Composition, but none of its siblings.
Then EVAL1.parent_composition() will jet get that local copy of the owning C1.
I’m thinking of this mostly in the context of AQL where I may need to extract some contextual information from the original parent composition to display or perhaps expose via an API.
I remember suggesting some sort of resolve function for aql when talking to Ian. My suggestion were based on the following reason:
I don’t think we can generalise resolving of references at the whole query execution level. It should be localised so that other parameters to resolve can fine tune the resolving behaviour and we can use different behaviours while resolving different references under entries or elsewhere
There is a whole access control dimension to resolve type of functionality that should be considered and that would probably blow away the EHR centric access control we have in place at the moment, at least from a spec perspective (since vendors do their own thing as well)
How will you stop someone adding references to other people’s data (assuming somehow they end up enough info to produce a reference) then tunnelling into that data by pushing a composition with a reference to it, then pulling it back with AQL which innocently just fetches that? Where will you define the access control mechanics (and semantics) of that ?
When a developer does individual calls to resolve references at the server side, access control kicks in for each of them, so the above risk does not exist.
Yes, I agree - my current idea is that the retrieval service (AQL or other service) has to at least look at LINK type and meaning fields, and a link depth parameter. The more general approach is just to be able to state any predicates that decide if a link is followed and/or resolved in an expanded-mode retrieve. This is what we did in the EHR Extract spec in fact.
Yes we certainly have to keep this in mind. But I think it can be solved if we had a general content-based access control approach working in the EHR (we don’t really, at the moment). Because it has to be objectively testable on the server whether a particular Entry or Composition etc should be visible to a certain caller or not.
Well any content additions are subject to the same authentication, authorisation and legitimate-relationship filtering that apply to any other content in the EHR, so I’m not sure that this is a specific danger.
That’s (conditionally ) a good point. If my understanding of what you mean is correct.
What I meant was, without a mechanism to govern resolving of links, things would be problematic. If what you mean by the comments above is we introduce a mechanism to control access control for adding and resolving links, then yes, that addresses the concern I raised.
I raised it because as things stand, adding a link into a composition does not have its own access control context. It is subject to that of Composition, which would be problematic.
Well LINK objects are normal content; they can only be added by adding a new version to a COMPOSITION, same as any other content. Is there something I am missing here?
My point is, the link represents access to a composition that my be under someone else’s EHR, while the composition under which you’re adding the link is in your own EHR.
So the link potentially extends the scope of data to > 1 EHRs and even if you have the right to create a new version of a COMPOSITION, this does not mean that you’re able to extend the scope of that COMPOSITION to other clinical data sitting in other EHRs, to which you have no access
Ah - got you. That is a very good point. I have to admit, I have always assumed LINKs would be used between items in the same EHR. But the spec doesn’t say that, and as it stands, a LINK could point out of EHR1 into EHR2. And I don’t have much knowledge on how they are being used in the wild - if implementing groups could provide more info on this, it would be helpful.
We probably need some way of marking LINKs as being limited to inside one EHR, or not. My idea of CITATIONs is that they are limited to being inside one EHR, and semantically you need this. Otherwise you could make a Problem list that somehow points into someone else’s previous Dxs, which would be wrong.
We have not done much design thinking around LINK use for many years, and I think we need to address that. So these issues are good ones to bring up. Any concrete ideas on how we should better specify them, and make other improvements (e.g. the CITATIONs proposal) are very welcome.
Cheers. Not allowing the links to other EHRs eliminates the issue and we can relax that constraint later if we introduce it now and find out that there is a need for it later.
Agree with @Seref , linking/citation beyond ‘current’ EHR is not desirable (although I would not be surprised for such requirements in relation with transplants, donors, neonatology, etc). Buth even inside an EHR you might have data ‘protected’ by various ACL policies (like forbid some data from previous episodes, or from different subdomain, etc), which has to be (or at least would be nice to be) considered while resolving links.
Another aspect which is not clear for me is if besides referring you’ll also include (inline) resolved link targets into Composition, and than persist it - will that not lead to data-duplication? Or perhaps I misunderstand the goal here ?!
No - this is the idea of expanded-mode retrieval - we are only talking about populating the resolved references in the data as it is retrieved, in ‘expanded mode’, not as it goes in. In other words, this expanded mode is a convenience mode that stitches together all the bits and pieces in a structure that is natively represented as references, such as a problem list.
I agree with @sebastian.iancu here, this is not going to be enough. We use partial access permission a lot, e.g. a nurse has acces to specific compositions in an EHR and a doctor to others. This can even change afterwards, so a nurse recording a link to a specific doctors note can be visible/authorised for her but this can be changed later so when the nurse later wants to resolve the link and view the linked doctors note it can no longer be authorised.
And I dislike excluding links to other EHRs on principal, because it limits intraoperability. But not sure if it’s the pragmatic thing to do since it will probably be used little for the foreseeable future and cost may be big.
Well this is access control, which at the moment is not concretely standardised in openEHR, i.e. systems implement their own solutions. Solving this requires representing:
consent (by info subject, stating who can access and when)
current care relationships
worker roles or other ‘types’.
Whatever we come up with for Link resolution will need (just like any mode of access) to be subject to the privacy regime; if it is not, it meas privacy isn’t working in the EHR.
Agree - I was not suggesting that Links could no longer point outside an EHR, but that we consider how to control ?specific Links (e.g. of a certain type) in that way, while allowing others. For example, LINKs with type=citation could be limited to being inside the same EHR.
yes, I think that would work. I think what we are looking at is special falvour of LINK thate.g type=citation, that is always de-referenced and from a querying point of view ‘exists’ with the parent composition as if it was in-line.
"Find any allergy Entries that ‘belong inside’ the Allergy list composition, and show me the name of the allergen, any manifestations and the start_time of the original composition in which it was recorded, regardless of whether that Entry is stored inline within the Allergy list composition, at a local reference within that composition or linked from a completely separate composition.
@sebastian.iancu - this is absolutely not about duplicating the data - it is about avoiding that, in fact!!
Just to annoy you, although I did use that example of a Link with type = citation, I still don’t think LINK is the right way to go for the purpose of citation, for reasons mentioned on the wiki page.
I do think we should do some work on LINK anyway, because LINK does get used, and we need to achieve this target-resolution idea for whatever content in a general way.
But I am pretty sure that using LINKs to effect Citations, although possible is going to be more painful than using Citations as a kind of Entry that cites another Entry (and/or other objects, maybe whole Compositions).