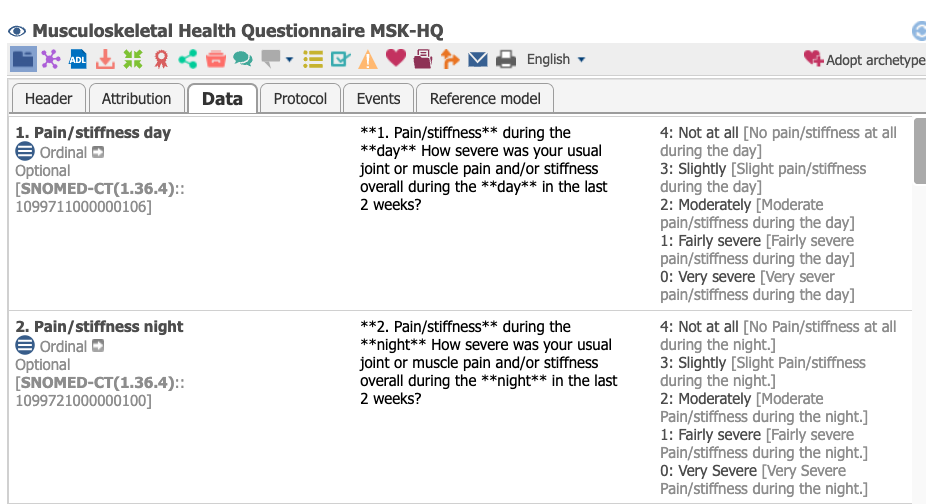
I’d like to re-open this discussion as we are in the process of reviewing a PROMS archetype which pushes the requirements to accurately represent PROMS UI directives a little further;
Ignore the ‘markdown’ in the Descriptions - that is another contentious issue/experiment Markdown use?.
The changes we have made, since the last posts, are to accept @heather.leslie 's argument that in the majority of cases, it makes sense just to put the original patient-facing long text question into the Description field for formal scales and scores.
There are some other issues though…
-
Do we need to technically flag up any exceptions to using Description for original patient questions? I think there are such exceptions on CKM. Perhaps it is not important?
-
Should we handle other ‘UI directives’ which are part of the use of the scale/ score. The open Outcomes developers certainly appreciated adding these to the archetype.
An example is a ‘Page break instruction’ where the score specifies that a piece of text must always appear at the top of any pages/tabs created by the app
“This questionnaire is about your joint, back, neck, bone and muscle symptoms such as aches, pains and/or stiffness.”
This is part of the licensing requirement for any app that deploys this score, so there is an argument that it assists some of those tricky conversations about archetypes and licensing, since we can demonstrate that we make it easier for apps developers to do the right thing.
We handled this ‘pagebreak instruction’ by placing it in a marked-up comment but this was largely due to some problem with current tooling.
e.g,
["at0000"] = <
text = <"Musculoskeletal Health Questionnaire (MSK-HQ)">
description = <"The MSK-HQ is a short self-reported questionnaire that allows people with musculoskeletal conditions (such as arthritis or back pain) to report their symptoms and quality of life in a standardised way.">
comment = <"pagebreakInstruction:
This questionnaire is about your joint, back, neck, bone and muscle symptoms such as aches, pains and/or stiffness.
Leaving aside whether this is a good thing to do, our preference would actually be to use the keyed items in the archetype ontology section, as these need to be multilingual
["at0000"] = <
text = <"Musculoskeletal Health Questionnaire (MSK-HQ)">
description = <"The MSK-HQ is a short self-reported questionnaire that allows people with musculoskeletal conditions (such as arthritis or back pain) to report their symptoms and quality of life in a standardised way.">
pagebreakInstruction =<" This questionnaire is about your joint, back, neck, bone and muscle symptoms such as aches, pains and/or stiffness.
However, we found some issues with the way that this is represented in Archetype Designer .opt generation, where it treated as a template annotation (and therefore uni-lingual), and by the web template format , which merges mutli-lingual keyed ontology items with template annotations.
I’m sure these are fixable, so our questions are…
-
Is there a place for these Scale/score UI directions in archetypes, and an agreed way of capturing them.
And if not in archetypes, is there an argument for having a set of agreed directives that can be added at
template level?
-
Are there other examples e.g. headerInstructions that might apply.
-
Do custom keyed ontology items make sense for this?
-
Are there any tech blockers to keeping these keyed items multilingual and carried correctly in .opt and .wt formats?