Well, I do like to give you all a laugh now and then, so here goes. I have started a project to build an open clinical terminology. I don’t like SNOMED-CT’s licensing, or its structure, or even its massive and stupid numeric identifiers.
I realise that proposing a project like this is at the extreme fringes of sanity, but I’m up for having the resultant discussions. I would love to collaborate with any other lunatics that think an open clinical terminology can be achieved.
Here’s the project
The idea is to crowdsource the clinical content over… well, however long it takes to do that.
Early design decisions are being made right now, so if you have views on this kind of thing then you should join in in the issues or discussing the project on Open Health Hub.
A standard language for defining terms (I guess RDF)
a strict(er) ontological approach
easy migration paths for existing terminologies
Ability to replace internal codes in ADL on a per archetype/template basis
Sets of codes (refsets) as FHIR valuesets
A permanent uri per code
A defined namespace for the terminology.
Political alignment with IHSDO
@grahamegrieve mentioned his most desired wish is to fix snomed. He probably has some ideas too.
maybe it’s not too crazy after all:p
edit: and most important of all, don’t try to solve everything! So don’t try to be an information model, so no default context, no codes for ‘family history of infected breast implant with conservative treatment after a dog bite by a chihuahua’ or whatever exotic combination snomed ct introduced in the latest release.
down with RDF. It’s where practical projects go to die
I’d go for simple mono-hierarchical tables with a strict grammar
mappings to existing terminologies
easy to deploy to FHIR terminology servers
The really hard thing to resolve is extensibility/customization aka post-coordination and/or distributed governance. It’s easy to think that you don’t need that in the early phases where you can be both nimble and methodical, but later it becomes a growing issue and if you don’t have a solid solution from the start, you’ll be doomed by the time it bites.
If I have read @grahamegrieve correctly, I would agree with the idea of seeing this as a simplification layer on top of existing terminologies, rather than ‘starting again’. There are other options like ICPC too.
The licensing issue with SNOMED does seem to be ‘going away’ albeit slower than we’d like, and building/maintaining a international terminology with all the challenges of translation etc is massive.
Thanks all for the replies and (what I’m interpreting as) encouragement.
At EHRCON25 Grahame said you have to be “naive and optimistic” to do this kind of thing. Bloodyminded is also a Yorkshire trait I will be leaning into.
Replies
I think I’m more likely to get legal letters than political alignment. The existence of an open terminology might care them into making SNOMED more open (it worked with Microsoft and .docx in the face of OpenOffice/LibreOffice and Apple iWork)
Agreed! Trying not to make this project hurt anyone’s brain too much, least of all mine.
Thanks - agree - I read this as part of my planning and made notes. I will be incorporating the bits of the Desiderata that I think are sensible and still relevant in 2025.
Definitely, although these will have to be crowd-sourced
I am listening to/reading carefully all your feedback and will bring into the project what I think makes sense. However I am determined not to make OCT some maddeningly complex superset of SNOMED
But the only way to get your views implemented in OCT is to join in, become part of the team. There are no pundits only players. The field of play is the GitHub repo.
I am hard separating the Namespace from any Hierarchy/Ontology/Expression Languages. Bundling both in the one system is what makes the dominant terminologies completely unfathomable except to about 14 people worldwide. Namespace first, then ‘linking’ layers on top of that (layers which need not all come from within the OCT project)
I will incorporate any bits of existing terminologies (eg ICPC, GPS, any parts of Read that are public domain…) IF they are license-compatible with OCT.
I think it’s quite different to that, which seek to be unification / mapping projects. This is a project to come up with a genuine open source terminology for clinical use
BTW, as much as I respect Jim Cimino and his desiderata, he is wrong in one respect:
2.4 Nonsemantic Concept Identifier
That section is incoherent. The concept identifier (= code) is not the display name. And it shouldn’t (as stated in the text) include the heirarchy in the concept identifier (I completely agree with that). But neither of those things is a defense of why the code should be non-semantic. And if you endorse concept-permanence, then the code can’t be redefined.
That’s why FHIR code systems have semantic (but not structural) codes. But it does get harder as the code system gets bigger.
This is a debate in openEHR as well. openEHR has non semantic codes (atXXXX) which in a specific implementation artefact (webtemplate) gets replaced with the default language’s name for that field. I don’t want to have that debate in this thread, just trying to understand what you’re saying because it seems relevant to that (other) debate.
So FHIR names elements but doesn’t number (‘structural codes’ element1, element2 etc, nor hieararchy element1.1, like ICD10 does ) them, right? What get’s harder, using semantic codes in bigger (than FHIR) code systems, or bigger code bases that implement structural codes? I think both are an issue/challenge, but I’m trying to understand your point and wether it’s also a recommendation?
I think you’re right @grahamegrieve but in the end I went with nonsemantic IDs because it’s more friendly to internationalisation.
However there is another way to have an ID that has meaning, but which is still non-linguistic - you could make the ID the SHA1 hash of the description (and you could probably get away with a shortened version, say the first 7 chars for convenience). So the ID would have meaning but not to humans. It would enable very simepl checking of the ID, you just hash the description. Is this feature actually valuable though, or just a bit too smartypants?
I’m working on the current namespace being something like https://openterminology.org/terms/en-GB/R9J3JQ (not working yet but not far off)
What would you want such an endpoint to return?
Don’t terminology servers just add a huge TLS overhead to everything? Can’t we make it so that the terms can just be built into software directly like a library?
I was talking about codes in code systems, not elements in resources
I would use codes linked to the definitions, yes.
can be wrong in all languages at once, instead of right in the most common language?
but you will be adjusting and clarifying the description , that is certain
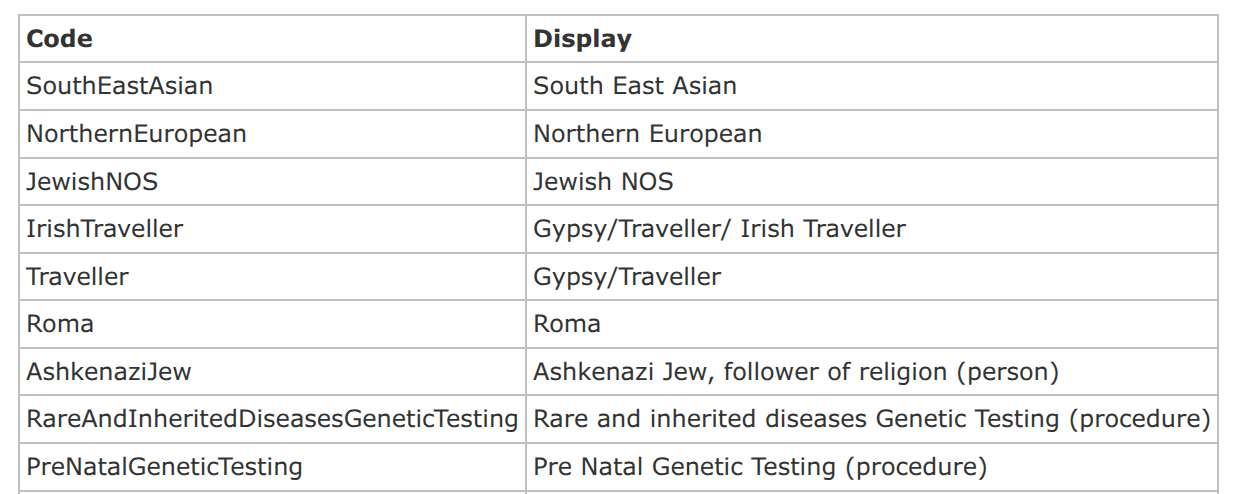
And codes as short semantic signifiers really helps people visualise the structure, which is challenging.
combined terminology service and web site (depending on accept: header)
Don’t terminology servers just add a huge TLS overhead to everything? Can’t we make it so that the terms can just be built into software directly like a library?
indeed, you want to be able to do a library, but the point of a service is to decouple between full software upgrade and changing terminology content. So the question is how you decouple UI from content. There’s two models, which should both be supported: the standard terminology server approach, and the software max approach, where only the raw tables are input.
Well, to me it’s more about a consistent identifier (so not nescessarirly locator) available to different implementations (openehr FHIR etc). It would be helpful if the url shows some basic info about the code to the user (I’m thinking modeller, not developer per se).
What snomed does in this regard with the sct.info/xxxx works well for me
The HASH value would change as the description changes.
For humans, the semantic codes within the FHIR code systems indeed appear very user-friendly and straightforward / easy to understand. However, non-semantic concept identifiers/codes are a fundamental principle, although human-readable/understandable concept identifiers/codes may seem feasible for many smaller code systems, especially when their few concepts involved have clear and unambiguous meanings. Because the linguistic expression of concepts is prone to change, especially when their meanings shift, therefore the semantic codes might have to be altered.
What do you do when the code name has to change. For example bronze_diabetes → haemochromatosis or renaming away from Nazi associations (Asperger syndrome, …)
The other problem is that words change in meaning over time. Not a great example, clinically, but easy to comprehend: “gay”
Yes, I think this is why we’ll steer clear of hashed-content IDs.
Hashing (of a random source) can still be a way to get ID (as @siljelb points out that is how UUIDv5 works)