Hi!
The value encoding in the wonderfully ingenious (now possibly deprecated?) ECISFLAT format (likely created by @chevalleyc) is described in ethercis/doc/flat json.md at master · ethercis/ethercis · GitHub
There is also a wikipage https://openehr.atlassian.net/wiki/spaces/spec/pages/624361477/Simplified+Serial+Formats+-+Data+Types by @thomas.beale documenting this as “preferred compact format” but adding [ brackets ] etc. There is also an unfinished specification draft at openEHR Serial Data Formats (SDF) that I assume is soon superseded by being partly incorporated in the combined Simplified Formats for openEHR Data
I have seen similar encodings for openEHR datatypes in key value pairs communicated to Cambio’s CDS platform by @rong.chen and his colleagues.
I myself want to use such a terse format as one of the alternatives in RM class constructors in GitHub - ErikSundvall/ehrtslib: TypeScript library for (to begin with) openEHR (in approach 1C)
My question is: Is there any authoritative source for how this should be done? If not would it be welcome to add an official draft/development specification of this, and would those of you mentioned above (and any others?) like to join such an effort?
The terse leaf node strings can be used inside many different formats and programming languages, so they are not JSON specific, but a section about recommendations for use in JSON (and thus likely JavaScript & TypeScript) might be good to have too. For example:
- Should a DV_COUNT value really be serialized as a string within “quotes” rather than as a JSON number without quotation marks
- What about datatypes only containing
true, false and null (for example DV_BOOLEAN when not containing null flavour) - I think we should we avoid quotation marks there when serialised to json
- If all the extra brackets and square brackets added in the wikipage https://openehr.atlassian.net/wiki/spaces/spec/pages/624361477/Simplified+Serial+Formats+-+Data+Types are kept in the specification (I actually hope we skip them) how should we then treat them in a JSON serialisation
I believe @erik.sundvall is the first one who published openEHR related library created using AI on this forum. Congratulations!
Well worth reading the git log to see how this project progressed since its inception (just a month ago).
@erik.sundvall Are all the classes complete? It looks like DV_CODED_TEXT is missing the setter for defining_code. The same issue is also in COMPOSITION.
Also the non-abstract class EVENT_CONTEXT (and others) does not implement inherited abstract member is_equal from class PATHABLE.
There are few more errors related to the generic classes.
Continuing sidetrack about Ehrtslib…
@borut.jures the project is very far from complete. I don’t have very much time to spend on it, so development is a bit slow. Regarding setters/getters I think most of the properties of the openEHR classes are supposed to be public and not necessarily need specific setter/getter methods in Typescript, but will check at later time, thanks. Feel free to add issues (GitHub · Where software is built) or PRs, then I’ll try to put my AI minions to work on it 
You are probably talking about the [] used on openEHR coded terms, i.e. the usual [snomed::123456789] and similar. In the Task Planning ecosystem, I removed these brackets because they interfere with JSON and other common usages of brackets (usually, to indicate an array or list of things). Instead, I changed the syntax so that coded terms start with a ‘#’ character. See here for an example. If you scroll down, you’ll start seeing things like #low, #normal, #ipi_intermediate_low_risk and so on. Each of the strings ‘low’ etc is the symbolic name of a term local to the Decision Logic Module, i.e. the equivalent of an at-code (but not an id-code) in ADL2. I have not used any external codes directly in this syntax, but they would look like this: #snomed::123456789, which is easy enough to parse.
This is of course yet another piece of custom syntax that JSON, YAML etc know nothing about - but so are other elements of the various flat syntaxes in use in openEHR. Treat it as another idea for the current discussion.
Yes i am talking about the [ ] so if we can skip them (good!) then we have at least one challenge left.
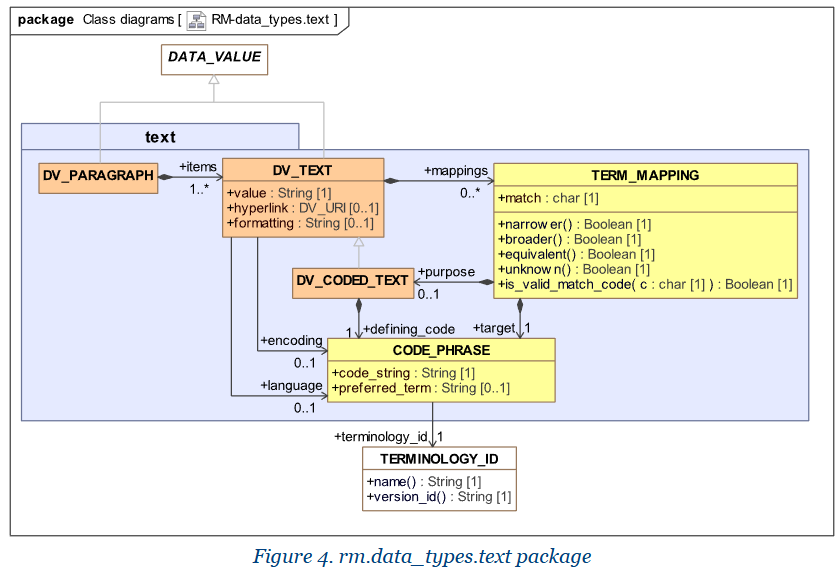
CODE_PHRASE actually does not have a value property, it is likely an error in https://openehr.atlassian.net/wiki/spaces/spec/pages/624361477/Simplified+Serial+Formats+-+Data+Types), but has recently (likely after the wikipage and the ECISFLAT format was created) gotten a preferred_term property. So the “maximal pattern” for CODE_PHRADSE in the wikipage would, if we skip the brackets be
terminology_id(ver_id)::code_string|preferred_term|. This would for a parser collide with the CODED_TEXT pattern defining_code.terminology_id::defining_code.code_string|value|
In order to separate the serialization of a CODE_PHRASE that happens to have a preferred_term from a CODED_TEXT it would be good if their serializations looked differently. The fact that CODE_PHRASE is embedded inside CODED_TEXT might complicate things leading to things like defining_code.terminology_id::defining_code.code_string|defining_code.preferred_term||value|
In an openEHR CODED_TEXT where value is mandatory and the main human readable thing perhaps the value could come first rather than the after the coding in the terse format so that the actual value is read before you might read the preferred term of the CODE_PHRASE. Like: value|defining_code.terminology_id::defining_code.code_string|defining_code.preferred_term| That might align more with the DV_TEXT serialization too - putting the value first and then attach more info as a suffix.
Or if using # as suggested by @thomas.beale above: value#defining_code.terminology_id::defining_code.code_string|defining_code.preferred_term|
To really make a comprehensive terse solution the entire text package (Data Types Information Model) with all its possible nestings would be good to consider.
At the same time the simple most common usages should be the most readable, and maybe complicated cases with
hyperlinks,
formatting,
encoding,
language and
mappings possibly containing nested
purpose and
target should be forbidden in the terse format and the full JSON or similar full object notation of selected serialization format used instead.
Possible escaping of control characters needs to be considered of course. In Snomed CT that I think has inspired the |pipe| notation in openEHR, I believe that the pipe character itself is forbidden to use in the terms since it is used as a delimiter. I think we want both | and # to be allowed inside the value of DV_TEXT and DV_CODED_TEXT since they might be typed by clinicians in UIs.