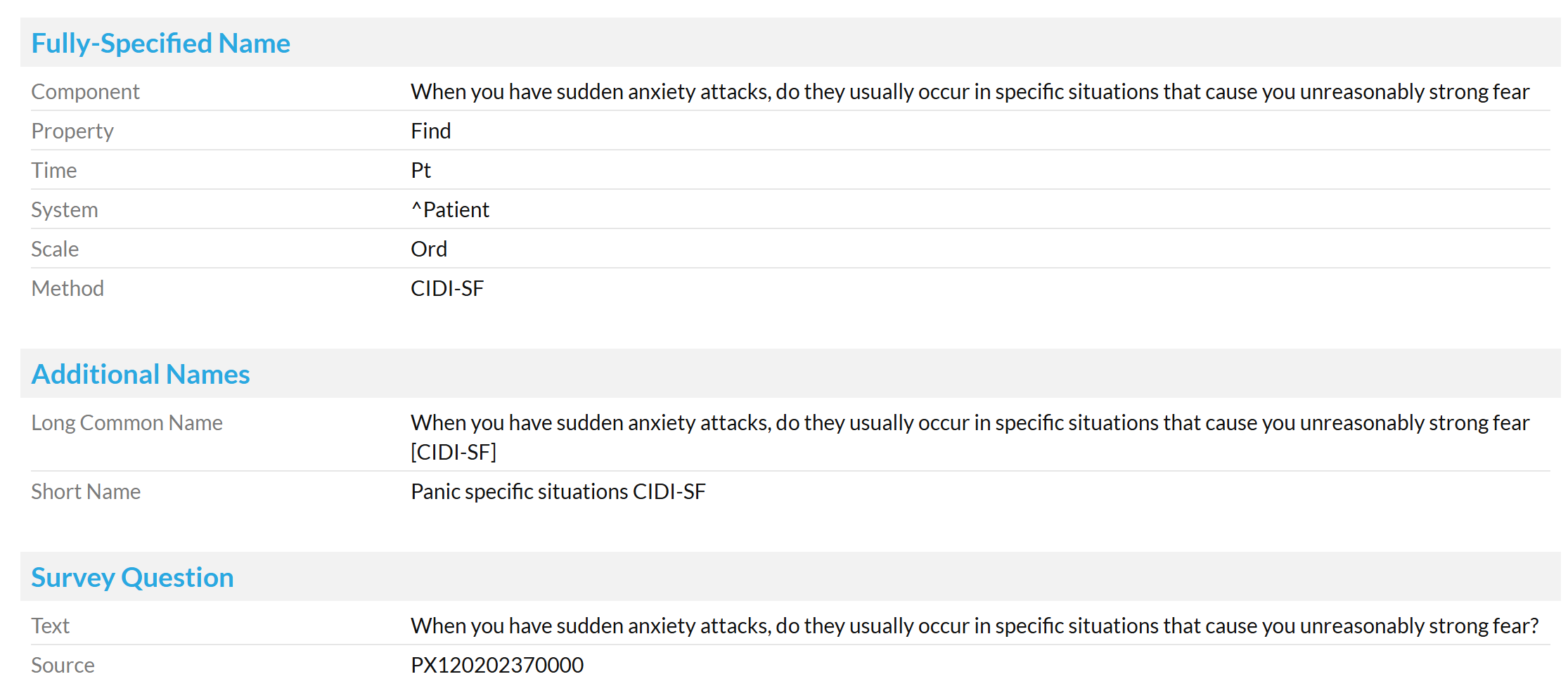
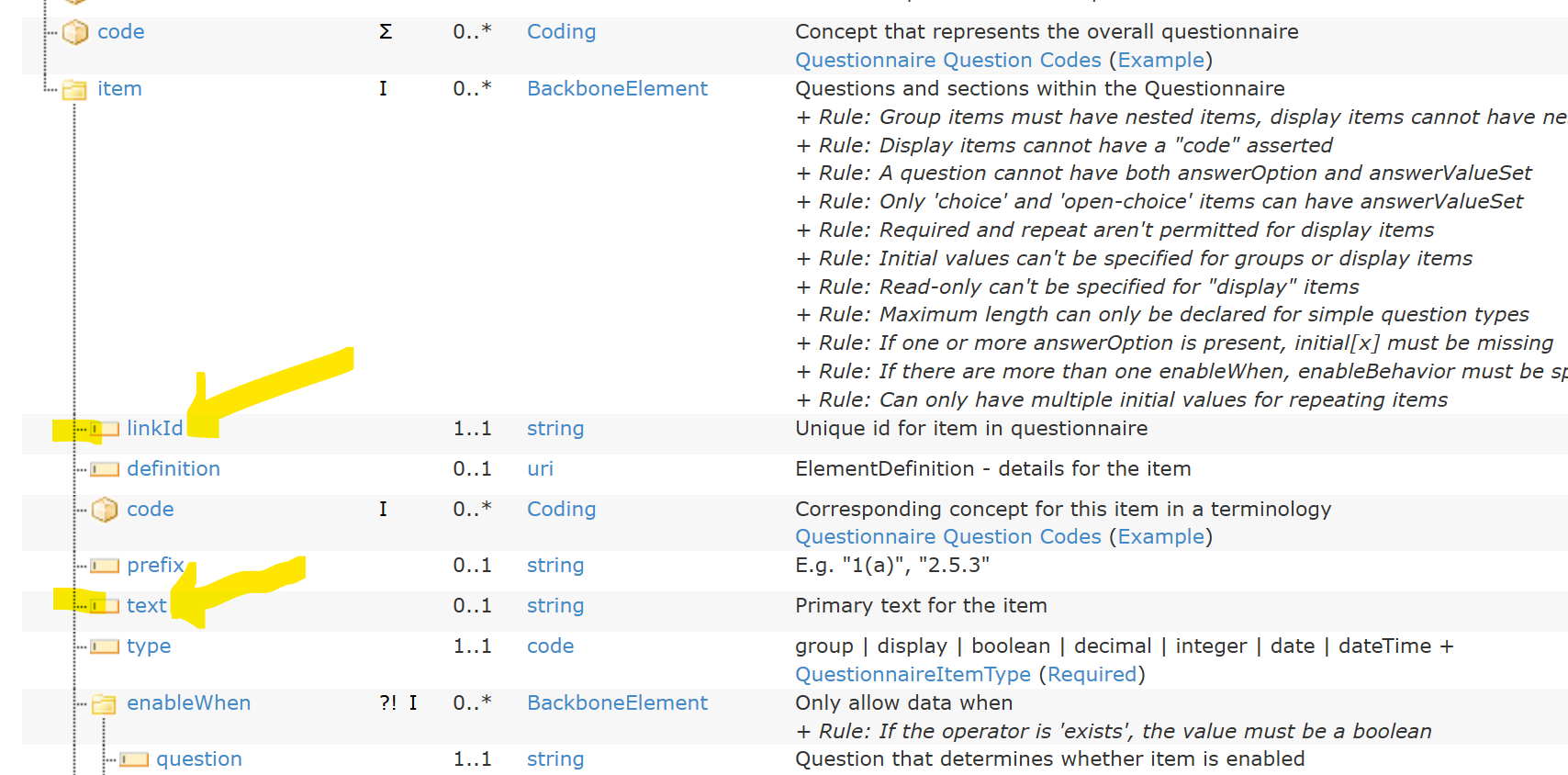
Last year we were well on our way to create a modelling style guide for patient reported outcome measure (PROM) archetypes. PROMs are usually copyrighted tools, and we will most of the time require the approval of the copyright holders to be able to publish archetypes. In addition, PROMs are really sensitive with regard to how they are worded and presented, and the questions are sometimes really long.
For these reasons, the first draft of the style guide recommended using the full and exact wording of each PROM section or question as the name of the relevant container or element. This however led to potential complications with how the natural language FLAT formats work, in that a FLAT format path generated from these long container and element names would in turn become very long.
For example, the canonical path
openEHR-EHR-openEHR-EHR-OBSERVATION.expanded_prostate_cancer_index_composite.v0/data[at0001]/events[at0313]/data[at0003]/items[at0319]/items[at0046]
would in natural language become something like
expanded_prostate_cancer_index_composite_EPIC/any_event/how_big_a_problem_if_any_had_each_of_the_following_been_for_you_during_the_last_4_weeks/need_to_urinate_frequently_during_the_day
Not a massive difference, but I’m sure we could find worse examples if we looked harder.
Since this problem popped up, it was proposed to manually shorten each container/element name. This is problematic for several reasons:
- the copyright (holder) issues mentioned above
- increased workload on modellers to create shorter names for a potentially large number of questions, while keeping the semantic nuances and ability to tell similar questions apart
- increased workload on editors to get every reviewer to agree on shortened names for a potentially large number of questions
- having to replace the container/element names with the full-length questions again when building templates, leading to even longer canonical paths
So, since this at its root is a technical issue, we thought we’d bring it back here to discuss. How can we solve it without having to create cumbersome modelling workarounds?
Could it for example be an option to truncate “too long” (whatever that might be) names when generating the FLAT paths?