Hi,
We are currently modelling archetypes for our Swedish version of Pediatric Early Warning Score (Swe-PEWS). To get some early feedback on our archetypes, I want to share them here with you so you can comment. I have also added some background information to our archetypes below.
Archetypes
https://tools.openehr.org/designer/#/viewer/shared/Pz9zaGFyZWRJZD0xJDUyMTVmMjk1YTRjNTRiY2M5YjQyMDgwOGYzOTVkNTNj
https://tools.openehr.org/designer/#/viewer/shared/Pz9zaGFyZWRJZD0xJDZjZmM1NzdhYTdmZDRmNWJhMDE4MGU1YTFmMGYzYTY0
https://tools.openehr.org/designer/#/viewer/shared/Pz9zaGFyZWRJZD0xJDlmMWIwYzlhMmI1YjQ3ZjI4YjZjMDAxNjUyMTFmNmM0
Swe-PEWS design
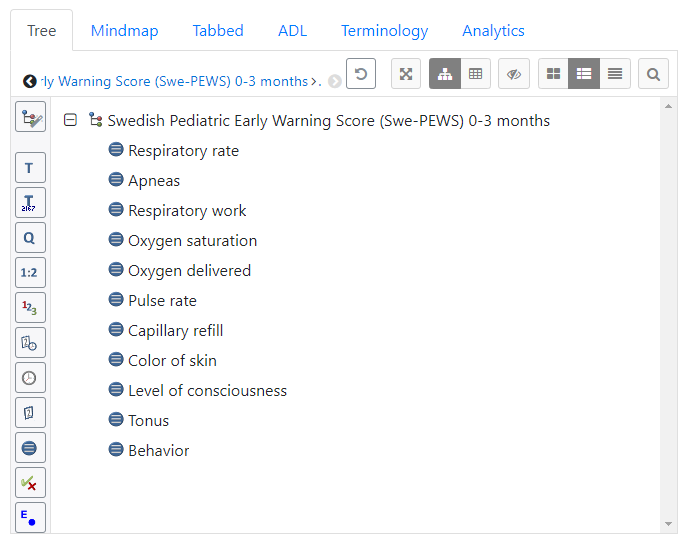
- The Swe-PEWS consists of seven quite simple score cards.
- Each score card is used for a specific age interval.
- Each score card consists of 5 respiration parameters, 3 circulation parameters and 3 neurology parameters.
- All seven score cards are identical, except for the reference ranges for one of the respiration parameters and one of the circulation parameters. These reference ranges depends on the patient’s age.
- Each parameter gives a score between 0 and 3.
- The highest score among the respiration parameters, circulation parameters and neurology parameters are summarized to a total score between 0 and 9.
Archetype design considerations
-
The used original language in these archetypes are Swedish, since the Swe-PEWS specification is written in Swedish.
-
An English translation is provided to still keep the international interoperability.
-
Since Swe-PEWS is an adaption of the international PEWS system, the designed archetypes follows the international pattern proposed by the archetypes “Paediatric Early Warning Score (PEWS)”, https://ckm.openehr.org/ckm/archetypes/1013.1.5149 , and “PEWS - simple variables”, https://ckm.openehr.org/ckm/archetypes/1013.1.5167 .
-
The designed archetypes are therefore specializations of the “PEWS - simple variables” cluster archetype.
-
To follow the pattern for the international archetypes, the parameters are modelled using the data type DV_ORDINAL.
-
When the same value in the ordinal scale are used for more than one cases, like both for “≤24” and “≥76”, the same value is used together with two different symbols, like in this example both the symbol “≤24” and the symbol “≥76”. This seems to be in line with general recommendations.
-
The trickiest part of the design is to decide how to model the two parameters that have different reference ranges depending on the patient’s age.
-
A simple solution would have been to exclude the reference ranges from the archetypes and distribute them in some other way. However, the reference ranges needs to be distributed and excluding them from the archetypes would only make them someone else problem. After some considerations it was assumed that it is most appropriate to distribute the reference ranges in the archetypes, because there is already a built in mechanism for distribution of definitions inside the archetypes. This option was therefore rejected.
-
Another alternative had been to insert seven different versions of the two parameters with different reference ranges in the archetype and use the appropriate version depending on the patient’s age. Which version of the parameters to use had been possible to specify on the template level. However, the reference ranges are assumed to mainly be interesting when writing information using the archetype to be able to use the right score based on the patient’s age. When reading information using the archetype the recorded scores are probably assumed to be correct given the patient’s age and the reference ranges are probably of lesser interest. It would therefore be very inconvenient to read and/or query different parameters based on the patient’s age to find basically the same information, which would have been the result if seven different versions of the two parameters had been used in the archetype. This option was therefore rejected.
-
Another alternative is to create one archetype that model everything in Swe-PEWS, except for the reference ranges for the two parameters that have different reference ranges depending on the patient’s age. This archetype is then specialized into one specialized archetype for each of the patients’ age ranges where the reference ranges for the two age dependent parameters are added. This alternative would distribute all reference ranges inside the archetypes and simplify reading and querying stored information. The downside is the increased number of used archetypes than with other solutions. However, tools created to use archetypes are assumed to be designed to handle many archetypes, so this is assumed to be a small issue. This option was therefore selected.
Known issues
- The Swe-PEWS specification states explicitly that the parameters always should be listed and used in the same order as in the specification. Unfortunately, I haven’t been able to specify that using the ordered ADL keyword in the Archetype Designer.
- The Archetype Designer doesn’t seem to handle specializations of the data type DV_ORDINAL correct according to the specifications. The specializations of this data type has therefore been done partly manually in the ADL code. This imply that the specializations doesn’t show up in the Archetype Designer’s graphical user interface.
Tooling experience
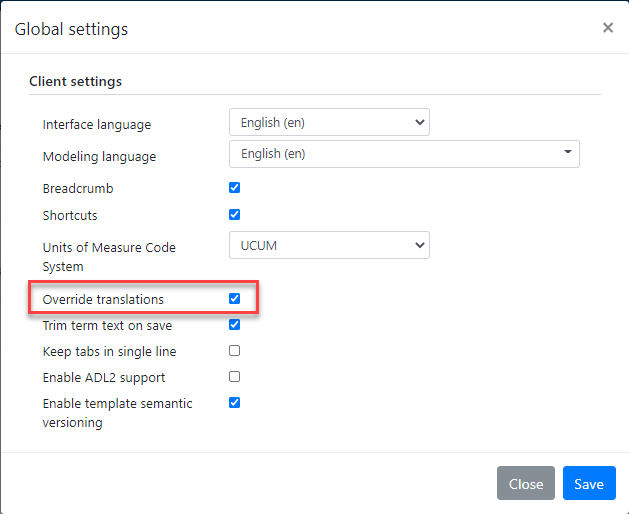
- The Archetype Designer gives the impression that the text in the other_details part of description are stored in both a Swedish and an English version. However, the tool only saves the latest entered version independent of language without any warning. This removes translations you have spent time to do.
- In the Archetype Designer, when I do a small update of a term in Swedish or English, like removing an extra space character, the tool updates the term in the other language for the translation I already had spend time to do with my recently updated term with an addition of an asterisk in the beginning and an abbreviation of the updated language in the end. This is probably a desired behavior before the translation has been done, but not after the translation has been done. Sometimes this ends up in a loop, so it seems to be impossible to do the translation in the tool, because it always updates the term in the other language. When you fix the tool’s unwanted update in one language, the tool do an unwanted update in the other language. This removes translations you have spent time to do.
- The Archetype Designer allows specialized archetypes to contain language translations that are not present in the unspecialized archetype. The Clinical Knowledge Manager seems to not allow this. I don’t know which is the correct behavior.
Regrads
Mikael