You can commit an instance of any concrete class. But Event doesn’t make sense as a concrete class; it’s incomplete - as all abstract classes are. The whole idea of an abstract class is to define common stuff needed by the exhaustively enumerated descendant types.
You can see the mess that results when this is not done by inspecting the FHIR xxxRequest resources, Admin resources and many others. This kind of modelling is now being reported as a serious headache by implementers.
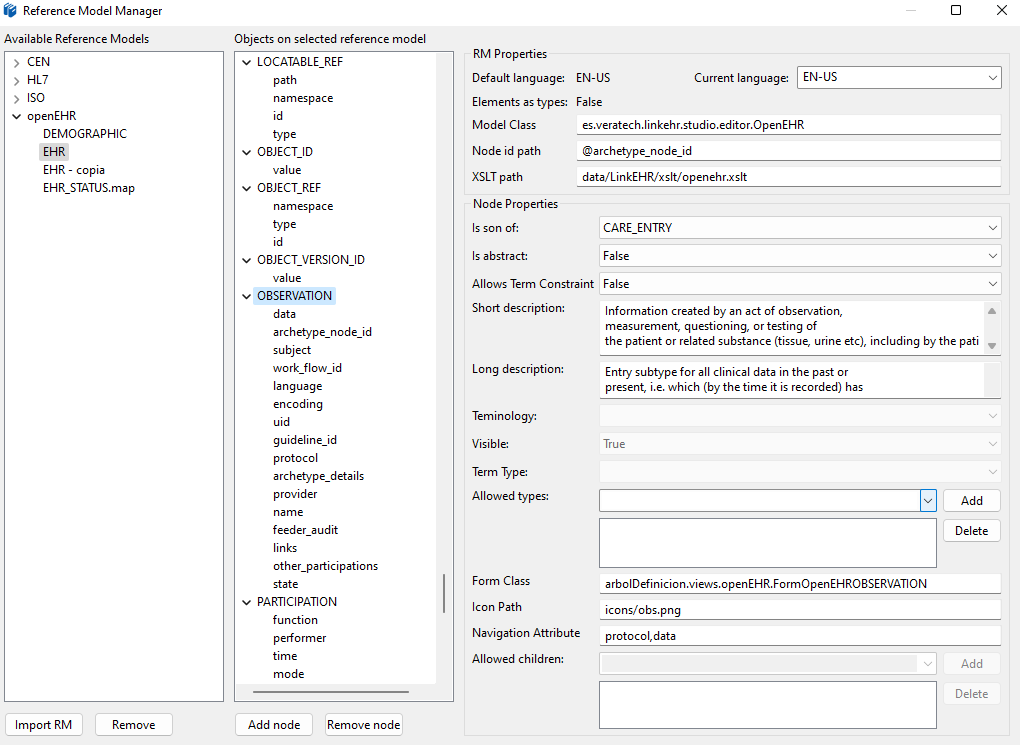
I think LinkEHR uses ADL as their source model, which is an interesting approach, though I see what you mention. I have a mixed view here: one thing is a descriptive/declarative meta-model, and another is a executable model. I know AOM/ADL lacks some constructs, like abstract classes, method definition (this is important too!), interface declarations, ownership/composition/aggregation declaration, annotations/comments, declaring final models/fields, though I think genetic types could be modeled with the descriptive/declarative approach, since it would be just a class name with a special syntax like ABC. Though in an executable meta-model, the meta-model itself should be able to verify if a submodel is valid or not, for instance if ABC is declared then a subclass is CDE and U doesn’t inherit from T, just to give an example. Considering that, I think AOM/ADL is close enough to a meta-model for object oriented models, and would be an interesting research project to investigate what’s the gap between current AOM and generic AOM as meta-model for any OOM. Having such complete meta-model we could leverage current tools and processes to use AOM as a meta-model for RM and as constraint model for RM with the same constructs, without the need of another meta-model.
Exactly, at certain level is a declarative form (additive), which is the meta-model, and at a higher level, it will be the constraining form over a model declared using the meta-model. As I see this is just a thing of identifying at which level AOM works, so systems could process it accordingly, but I don’t see an issue of using the same language to express the two forms. In fact I see a lot of potential in that approach, since less code is required to handle the meta-model and the constraint model. I don’t see an analogy with XSD here, because XSD is to define a document, not an OO model, and doesn’t have different forms, the only interesting thing is the XSD itself is a document so XSD could be used to declare itself. Same happens with JSON schema and with any other schema that is document-oriented. Object-oriented models are different in many ways, the basic one is the shape is not always a tree like in XML/JSON documents, so we are dealing with graphs not with trees.
It would be interesting to know how @damoca@yampeku used AOM as the base models for LinkEHR and what do they think about the whole OO modeling with AOM thing.
AOM is missing some things as Thomas said. We ended up adding an additional documentation file which contained information of these things, such as which are the abstract classes of the model or the real name of the attributes and types (ADL was strict in the past on what was a valid attribute name and we had to get this info to be compliant with ADL and be able to get the correct attributes in the target standard)
I have little to add to all the previous messages. I think we have never said that AOM/ADL is a mechanism to natively define and distribute a complete OO model (and many of its limitations have been mentioned). But it is possible to derive an AOM/ADL representation of that OO model that is enough to create archetypes based on it. As Diego said, it is not problem-free, we had to add some metadata in an external file to support all the information of the model, we had to work with generic identifiers such as OBSERVATIONat or ELEMENTat to always have unique archetype paths (which led to the introduction of idNNNN identifiers in AOM2/ADL2), and we had to intensively use internal references to create an efficient representation of the RM,.
Which are the benefits? We were able to have a single mechanism to edit archetypes, to edit specialized archetypes, to edit templates, or to edit archetype mapping for instance generation.
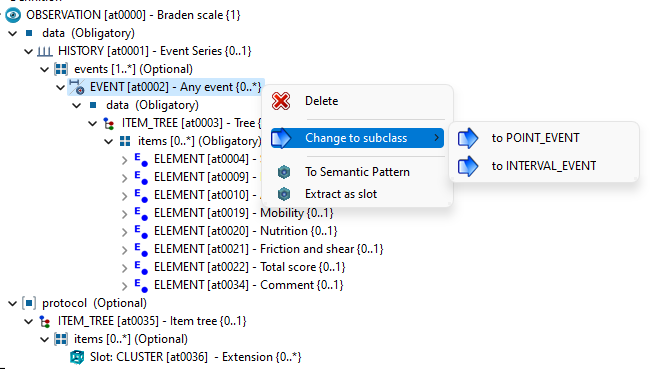
Back to the initial message of this discussion, it is worth to recall that LinkEHR Studio was created as a tool for the generation of RM+archetype compliant data instances. The edition of archetypes was a collateral functionality. I mention this with regard to the use of the abstract EVENT class. It is not that we don’t support it, it is that when you have to generate data instances, you have to define the logic to choose between an INTERVAL_EVENT or a POINT_EVENT. In LinkEHR this is done by forcing to choose the concrete class you want to use before generating the data generation program:
I’m not arguing that this is incorrect but I 'm pretty sure that at least some CDRs do not enforce this validation and allow an unconstrained EVENT to be persisted, treating it essentially as a POINT_EVENT. So whatever is suggested, that reality needs to be considered/ assessed.
If that’s at the data instance level, it’s a ‘category 1’ error! Any attempt to share information with wrong type markers in it will break any other software application or system engineered on the correct version of the reference model.
My initial exploration makes me think that Better do the same, so perhaps not so much of an issue as I had thought , and perhaps this is sensible behaviour but it would be good for us to know that it is universal.