I’m working with some complex OPTs, verifying data validation rules. From the OPT I’m generating a COMPOSITION instance and then validating the COMPOSITION against the OPT.
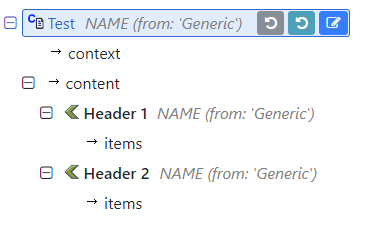
This OPT has several SECTION in COMPOSITION.content and have the same archetype openEHR-EHR-SECTION.adhoc.v1, but each SECTION has it’s own items, some have OBSERVATIONS, other ACTIONS, etc.
When I have a SECTION instance from the COMPOSITION object, need to get the defining C_OBJECT from the OPT, then finding by archetype_id doesn’t work because the COMPOSITION.content has many alternatives with the same archetype id in the OPT, and the archetype_node_id is always the archetype_id because are all ARCHETYPE_ROOTs.
So I’m wondering how other implementations deal with this case? Is there any other attribute that you use to find the correct C_OBJECT to validate a certain RM object?
As a workaround I used the C_OBJECT text from the term definitions to match the LOCATABLE.name.value, this works in TOM 1.4 since the OPT can only have one translation, so the COMPOSITION language should be the same as the OPT language. But in AOM 2 I think one OPT allows multiple languages so this workaround doesn’t work there.
Attached is the “problematic” OPT, just in case anyone want’s to check it.
the answer would be by its uid, but I’m pretty sure there is no extended support for that. I’ve seen queries by the name too, which is wrong in so many different ways
Ha, never thought of that, but non-root objects don’t have UID, I mean the compo might have an UID, but then the SECTIONs in COMPOSITION.content won’t.
With the current model I don’t think it’s possible, maybe I’m wrong. I think this would require some template-level ID, so each node in the template has it’s own unique ID independently from the archetype ID or node ID, since for sibling nodes that are ARCHETYPE_ROOTs the path would also be the same, so the path can’t be used as an ID for a unique C_OBJECT. Then in the RM instance that ID would be used as a mandatory field, so it doesn’t depend on implementation decisions (current LOCATABLE.uid is optional).
Yes but that doesn’t solve then issue: having an RM instance and for it’s nodes get the corresponding C_OBJECT from the template. The uid is optional for all locatable, but if you set it for all nodes in the RM instance, you can’t still get the C_OBJECT. A unique identifier of C_OBJECTs inside the OPT is needed, then that value should be on each node of the RM instance.
The case I described is an OPT like this:
COMPOSITION (openEHR-EHR-COMPOSITION.generic.v1)
– SECTION (openEHR-EHR-SECTION.generic.v1)
— content A
– SECTION (openEHR-EHR-SECTION.generic.v1)
— content B
Both sections are siblings, both are ARCHETYPE_ROOT, in archetype_node_id in the COMPOSITION instance both SECTIONs have the SAME archetype_id, but in the instance, the SECTION items are different. Then from the first SECTION in the instance I need the correct C_OBJECT, the one that defines content A, but there is no identifier that allows to differentiate between those SECTIONs C_OBJECTs in the OPT.
Also note since both SECTIONs are defined in COMPOSITION.content, inside a C_MULTIPLE_ATTTIBUTE, and have the SAME archetype I’d, both will have the same path, so the path is neither an ID of the C_OBJECT here.
That is the issue and it happens in the OPT attached on my first message.
I do not know about the internal structure of OPT, but if there is no other identifier to differentiate sibling nodes of the same archetype, the only way to differentiate them would using their name (the name you give to those nodes in the Archetype Designer). Fortunately, the AD does not allow that two sibling nodes have the same name, so from the editing point of view is a safe approach.
Now, the second part of the problem is where to put that name in the data instances to validate them. The only place i can think of is the name attribute, since theoretically it should take the same name as the one in the template. The problem will be if there are multiple languages, there could be a mismatch and then you will be forced to lookup for a match among those languages.
A more formal place for this information would be in archetype_details.template_id, but in that case, we would still need to have an identifier in the OPT to differentiate the sibling nodes.
This is essentially an archetype that does almost no constraining on the RM - so it’s like raw RM structures. I would have expected that specialised archetyes would be used for each distinct Section structure - that’s what you would do in ADL2 - either specialised archetypes (re-usable) or template level overlays (which still have distinct archetype ids). See here in ADL2 spec and scroll down a bit. This us another one of those ADL 1.4 problems that ADL2 solves…
In ADL2, since templates could have many languages, it requires a lookup for the translation based on the language on the RM instance (i.e. COMPOSITION), but FOLDER, EHR_STATUS or PARTY don’t have a language attribute, only the COMPOSITION has one, and this issue could happen on those types too.
In OPT 1.4 it works since the OPT supports only one language so no lookup is needed.
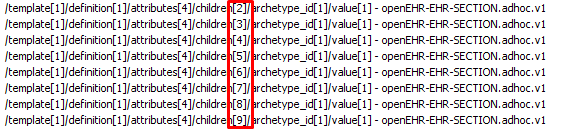
Given that OPT is an XML, and XML is ordered, and “IF” OPT regeneration respects that order, you could use the complete XPath, including the position, to each subsection as an Id. Of course this won’t work if the template is modified by adding or removing other sibling nodes, but in that case probably we should be also considering that you are creating new versions of the template.
This is really not such an issue in practice. We can put uids on any LOCATABLE but would virtually never do so, other than on ENTRYs. I would advocate putting uids at Entry level and e,g. event of activity level, to resolve this problem of distinguishing sibllings but in most cases it is not really that important (export to FHIR being an exception).
Using name is ugly, I agree but is where we are until we can use template-level internal codes to safely distinguish them - but that is generally at ELEMENT or CLUSTER level
@Thomas - I can clearly state that we virtually ‘never’ use SECTION archetypes other then ‘Ad-hoc’ and rename them for the local usage. And I don’t think I have ever specialised a SECTION. The use of headings is completely idiosyncratic and ultimately these should not carry any semantics. I can’t think of any queries in systems I have built that would require me to query on a SECTION.
@thomas.beale we can’t rely on how a modeler will create models, the key point is that the specs allow this case, even if it’s not common, it’s possible.
I don’t know how ADL2 per se solve this problem, since it’s related to how the modeler will create the archetypes and template, there are no constraints AFAIK that prevent a modeler to use these generic archetypes.
Fair enough - in that case, what you want to do logically is overlay. In ADL2, this creates distinct archetype ids for the overlays. The closest way to simulate that in ADL 1.4 is with specialised archetypes - which could be enabled by the tools.
Well we designed openEHR such that the semantics of Entries is never changed by what Sections they come under, and I believe that still holds (it should). There could still be querying for sections anyway (I am thinking more ‘standardised’ heading structures I see in US EMR data these days).
I don’t think the fact of querying being unlikely removes the technical need to be able to distinguish these sibling structures, or simulate overlays as per above.
If the modeller wants to distinguish sibling heading structures at the template, they are creating overlays (in ADL2-speak). That creates distinct archetype ids.
AD and TD enforce this at template-level by forcing a difference in name/value. Of course, that does not help where another item is created at run-time. THat’s where if unique identification is important I’d enforce recording ENTRY.uid.
In ADL2 it is automatic: you create any sort of further constraints on an included archetype, you get an overlay, and you get a new archetype id. It can’t be avoided. That’s why I say that specialising archetypes is the closest approximation possible in ADL1.4. Or better, just move to ADL2
Thanks @thomas.beale though moving to ADL2 would take a major refactoring on most 1.4 compatible apps, that is why I also try to discuss solutions for 1.4.
@thomas.beale rechecking your message, I understood the AOM2/ADL2 specs require that the archetype ID is modified when there are indistinguishable siblings in the archetype/template (e.g. two archetype slots to the same archetype ID).
So I suppose in a LOCATABLE instance that complies with that archetype/template will have the archetype_node_ids set to the modified archetype IDs, is that correct?
If so, that also implies in AQL we should use the modified archetype IDs not the original ones. So any tool that allows to edit queries should be aware of the modified archetype IDs. Doesn’t that generate issues for querying when you want/need to query by the original archetype ID?
Another design detail is that the modification on archetype IDs seems to be an actual codification of an extra field that contains some kind of numeric index, wouldn’t be clearer to have such field separated from the archetype IDs in the AOM and the RM?
That is also a solution I mentioned above for AOM/ADL 1.4:
In summary, for v1.4 the only solution to this problem is using the name to distinguish C_OBJECTs (as @damoca described on his sept 30 message), which relies on the modeler(s) to do that correctly, since no modeling tools check that, and that could generate bugs in systems that rely on this pattern without checking it, which IMO is dangerous design if not amended on v1.4.
I will actually create a validation rule on all my systems just to check this: if there are two sibling nodes in a template that have the same archetype ID and the same name (or unconstrained), then the template will not be accepted by the system. That is the only way I can provide a reliable product to my users.