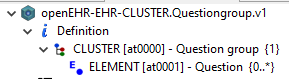
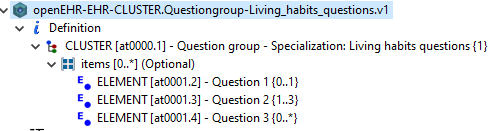
We are working on modeling questionnaires, which has been an ongoing discussion for some time now.
For short, we are reusing a generic question archetype in a way that the template (OPT) has a multiple attribute with C_OBJECTs that have the same nodeId but different names (using the name as a differentiator).
While reading the AOM 1.4 spec it says:
4.2.3.1. Node_id and Paths
The node_id attribute in the class C_OBJECT, inherited by all subtypes, is of great importance in the archetype constraint model. It has two functions:
+ it allows archetype object constraint nodes to be individually identified, and in particular, guarantees sibling node unique identification;
+ it is the main link between the archetype definition (i.e. the constraints) and the archetype ontology, because each node_id is a 'term code' in the ontology section.
REF: Archetype Object Model 1.4 (AOM1.4)
But in our case, this “rule” is broken: guarantees sibling node unique identification since siblings can’t be identified by node_id alone and need the name too.
From other sample OPTs in the CKM and the AOM itself, the way we are using the OPT seems correct, since I can’t find a rule in AOM 1.4 that says we can’t put two C_OBJECT that have the same node_id inside a the same C_MULTIPLE_ATTRIBUTE.children. Though I can’t find either a rule that says that node_id plus name should be unique, because now if we allow those two rules, then it’s impossible to know with which C_OBJECT inside the C_MULTIPLE_ATTRIBUTE.children a given RM object instance matches (important for validating RM instances against an OPT and also for querying).
I think a rule for unique node_id and name should be added to the AOM 1.4 specs, this is crucial for models that reuse the same archetype at the same level, like with questionnaire questions or with laboratory test results analytes
With that rule, we can say that an OPT that breaks it is not valid, right now we can’t, so systems implement that case in different ways, making behavior unpredictable (note this has to do with conformance).
We are actually implementing that rule, and returning an error if the OPT doesn’t comply.