There were several discussions over the last 3 years mentioning the possibility to express archetypes in a more popular format other then the ODIN-ADL and XML. One of the option considered was YAML.
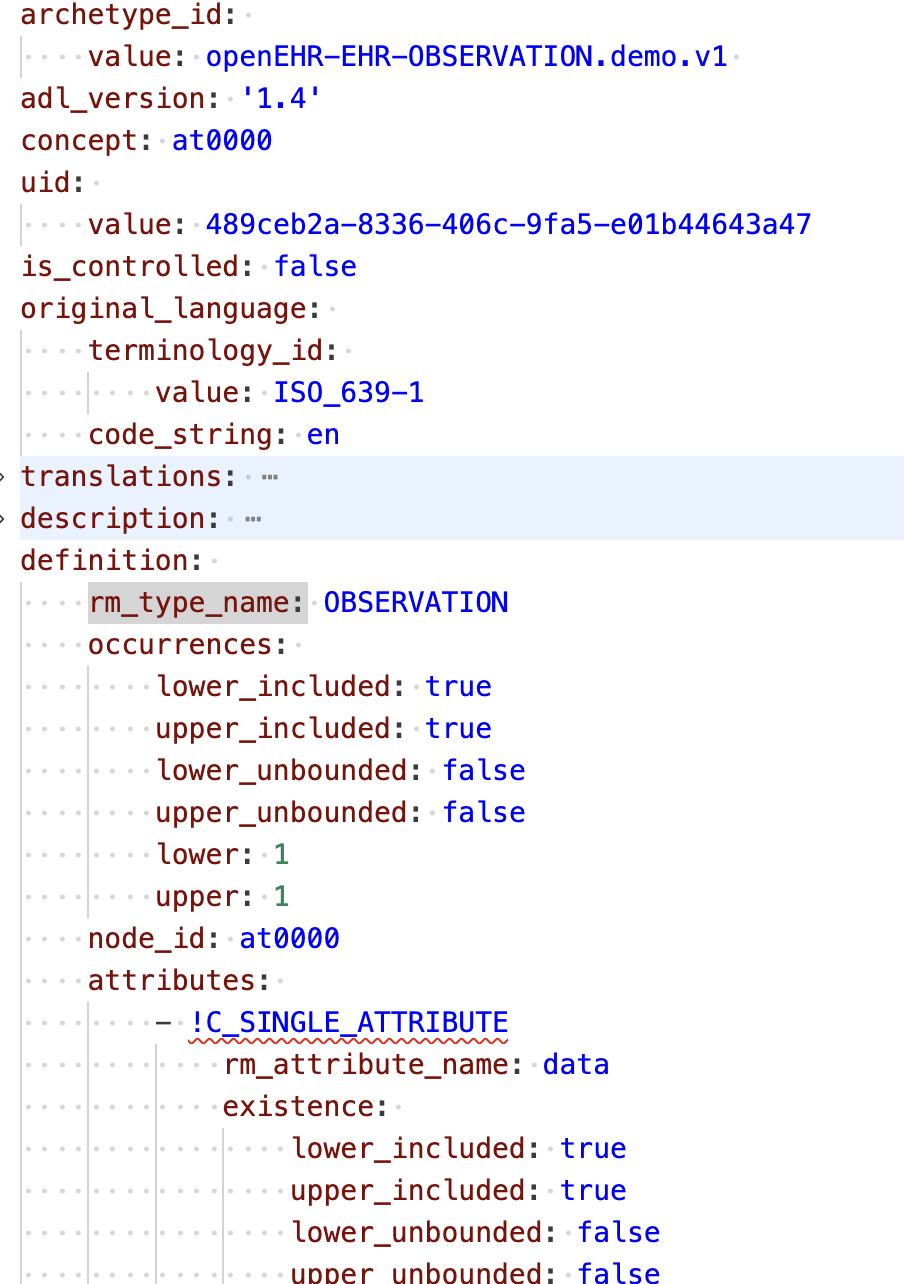
I was exploring a bit this, tried a few things and came up with following results for two of the archetypes on CKM (blood_pressure.v2 and demo.v1) - see attachments.
These are just experiments, nothing final, end result is certainly not standardized, but I’m curious for your feedback so far.
From my point of view it looks ok, readable and workable, almost as good as ODIN, but in any case it is just a plane standard YAML, with a few extra tags to indicate overloaded openEHR types.
This is interesting! I agree the description and ontology sections are more readable in YAML than in ADL, but the definition section is much less readable, especially with how it expresses numerical constraints like occurrences.
See how the DV_QUANTITY element “Systolic” from the Blood pressure archetype is expressed in ADL and YAML, respectively:
Avoiding ADL would lower a barrier to entry for new implementers but some clinical modelers like to write the archetypes in text editors. For them YAML requires more “key strokes” than ADL.
I’m always advocating for canonical JSON when serializing ADL (canonical to me means strictly following the specifications in BMM). However if we expect the clinical modelers to consider YAML as an alternative to ADL, I would expect that we use a “shorthand” variant for occurrences and existence (eg. {0..1}): (I knew Silje will be quick to comment about this )
occurrences: 0..1
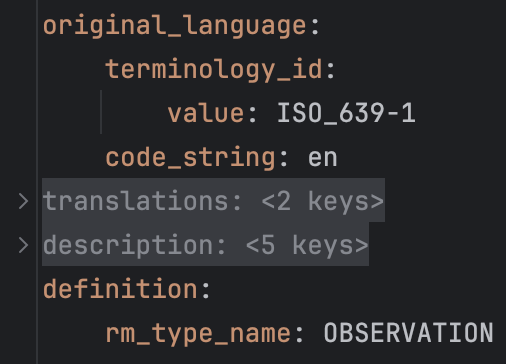
One advantage of using a well supported syntax is that text editors support things like “folding”. ADL files are looong and they require a lot of scrolling to get to a specific part of it. For YAML the editors support collapsing translations and description to quickly get to the definition section:
I had to search the YAML specifications for the use of ! reserved keyword (eg. !C_COMPLEX_OBJECT). In case others are also unfamiliar with it, it is a “node tag”: YAML Ain’t Markup Language (YAML™) Version 1.2
p.s.
I guess BMM files could be also changed to YAML and the change would have less impact
This would eliminate a need for ODIN parser everywhere.
I noticed that the json version above does handle the multipliciteos like “0…*” so that least makes the archetype muchmore readable - slots fills are a bit more probpematic but I could probably live with that extra complexity, especially if we could annotate nodeids to be human readable as this makes navigation much easier
We could use openEHR Serial Data Formats (SDF) for ADL YAML too. This would simplify occurrences, existence, interval, Terminology_code, date/time (and others).
This cannot be specified in the current version of BMM. Thomas says it could be added to BMM3.
Implementers must be careful to add those simpler formats to the serialization/deserialization code. This way it should remain computable.
For example my code generators use BMM + the previously linked specifications for Serial Data Formats to “overrule” the default behavior found in BMM files.
I thought we were going to do JSON first then other formats, since for JSON we have a canonical JSON Schema (I don’t remember if it covers the whole AOM/TOM 1.4 though).
For other formats we might need some kind of schema to be able to validate the syntax.
I don’t think writing adl by hand to produce an archetype is really done by anyone. Mostly it’s doing 99%from a gui editor. But making specific edits for edge cases or tool failure by hand in adl is a key requirement imho. So nr of key strokes is not really an issue I think. But legibility and thus nr of lines is.
Yes, this would be amazing.
I remember differently from SEC discussion at Nedap last November. but it wasn’t a final decision, so maybe I missed something.
Editing in yaml is much much easier than json, to me. Curious what the others think.
About those simplifications that flattens some value (occurrences , terminology codes etc) - we can do that for sure, but I intended to first produce a yaml that is close to AOM serializations, without any extra logic. But Like I said, this is just an experiment and a discussion point.
In that case, I prefer JSON. Not only because of what @pablo said about having a canonical JSON schema, but also for that 1% of manual edition.
An archetype is not a simple configuration file, as the examples provided show. It is a very nested structure where the use of brackets would be very welcome, instead of having to control the indentation levels by spaces. Just imagine having to add a sibling node here in a plain text editor. It is not about the number of keystrokes, but about the possibilities of introducing errors.
I get your point, but yaml comes besides readability also with some advantages over json, like comments, typing, tagging - basically json is a subset of yaml.
For experimentation, the ADL Workbench generates a 100% YAML flat form archetype for any archetype. I have not checked if the YAML is completely correct for a long time, but if people want to use it, I can fix any errors pretty easily.
Note that the above is a particular way of expressing DV_QUANTITY constraints in ADL1.4, but it’s not ADL.
I am pro using YAML for where ODIN is used in an ADL2 archetype, but for the definition part, which is normally in ADL, there are two things you can do:
serialise and read in cADL, enabling human and machine readability (and far less lines than YAML etc)
serialise and read the definition part in YAML as well, i.e. 100% YAML archetype.
The second approach is most useful for saving validated archetypes for operational use, because once an archetype or template is validated, it doesn’t need to be validated again, if unchanged.
For archetype and template-building solely using a GUI tool (like Archetype Designer) it doesn’t matter which representation is used, and the 100% YAML approach is possibly easier. However, in that approach, there is no ‘source’ level of representation - there would be no ‘look at the ADL to see what’s really going on’. If there are expressions in the ADL (as used by Nedap), then having no source level of representation might be quite problematic.
There are various people and companies who consider a source syntax view of archetypes essential, and they would want the YAML + cADL (+ EL) form of an archetype.
Either approach is reasonable - but I would say that users and tool builders need to know the consequences of their choices.
For loading validated archetypes and templates into a service of an operational system, the YAML (or any similar object meta-model format) is the most attractive.
Well I guess this is easy to add to typical modern language-server based editors for the cADL as well as the YAML that probably comes for free. Folding still doesn’t make the definition part readable if it’s in YAML (or JSON)…
I used to propound doing this as well, but ‘normal’ devs using standard tools will start screaming at you if you bury micro-syntax (which is what ‘0…1’ is) inside standard JSON. They want to see standard JSON, which is:
I don’t know if JSON-schema helps surface micro-syntaxes, if so, that might be an avenue to convincing people to handle JSON with embedded micro-syntax.
Right - it’s a general approach. But the result isn’t standard JSON (or YAML or whatever), it’s custom stuff.
Exactly - you have to have special processing. Personally, I have no problem with this, but again, normal devs using standard tools will complain, at least until there is a JSON++ standard that formalises syntax in String fields…
It’s done more frequently than you realise and it’s pretty easy as well. Not that I’m advocating it as the main method, but it’s very useful to be able to do it. Like BMM files - we write them by hand today; the thing it replaces is XMI, which no-one can write by hand.
Exactly right.
The ADL WB version just does this as well - canonical YAML.
Ok, but for the record, I don’t want to divert this post into advocating YAML vs JSON vs ODIN benefits - I only want to explore the following: “if” we would choose YAML then how should that look like.
There is so far no decision taken towards using YAML, but we just need to explore it.
@thomas.beale, if you say AWB has canonical YAML, could you export those two archetypes from CKM (bloode_pressure.v2 and demov1) in YAML and then compare results?
A combination of ADL+YAML is (to my understanding based on last two face2face SEC meetings) not what we want to investigate, as we would still be stuck with non-mainstream serialization formats.
Search “@Pablo Pazos introducing ADL3 is also an opportunity to “switch” to other serialization format…”
There are mixed opinions, I guess because of different experiences and use cases. What I remember mentioning in the meeting, that might not be in the minutes, is that for JSON there is a schema, which is more convenient for validation, though there are some adaptations to use JSON Schema to validate YAML, and there is certainly a simpler JSON ↔ YAML conversion than XML or other standard formats to JSON.
Before making any decision, we (SEC) should consider use cases, pros and cons of each format. Though my personal preference would be not to have one single “preferred” format, but instead having a standard serialization and deserialization process to/from many formats to the AOM 1.4 an 2.x, that allows then to have bidirectional format transformations like format1 → AOM → format2 (change format1 and format2 to whatever you want). That way we can support multiple use cases. For instance, if I need to display an archetype on a web app, I would prefer JSON because of the browser’s native support for JS. For storing ADL I would prefer YAML because it’s smaller. So using the best format for the job.
+1 on the comment by @sebastian.iancu I don’t want to start a discussion on which format is “better”, just wanted to point out those formats were mentioned in the NL SEC meeting.
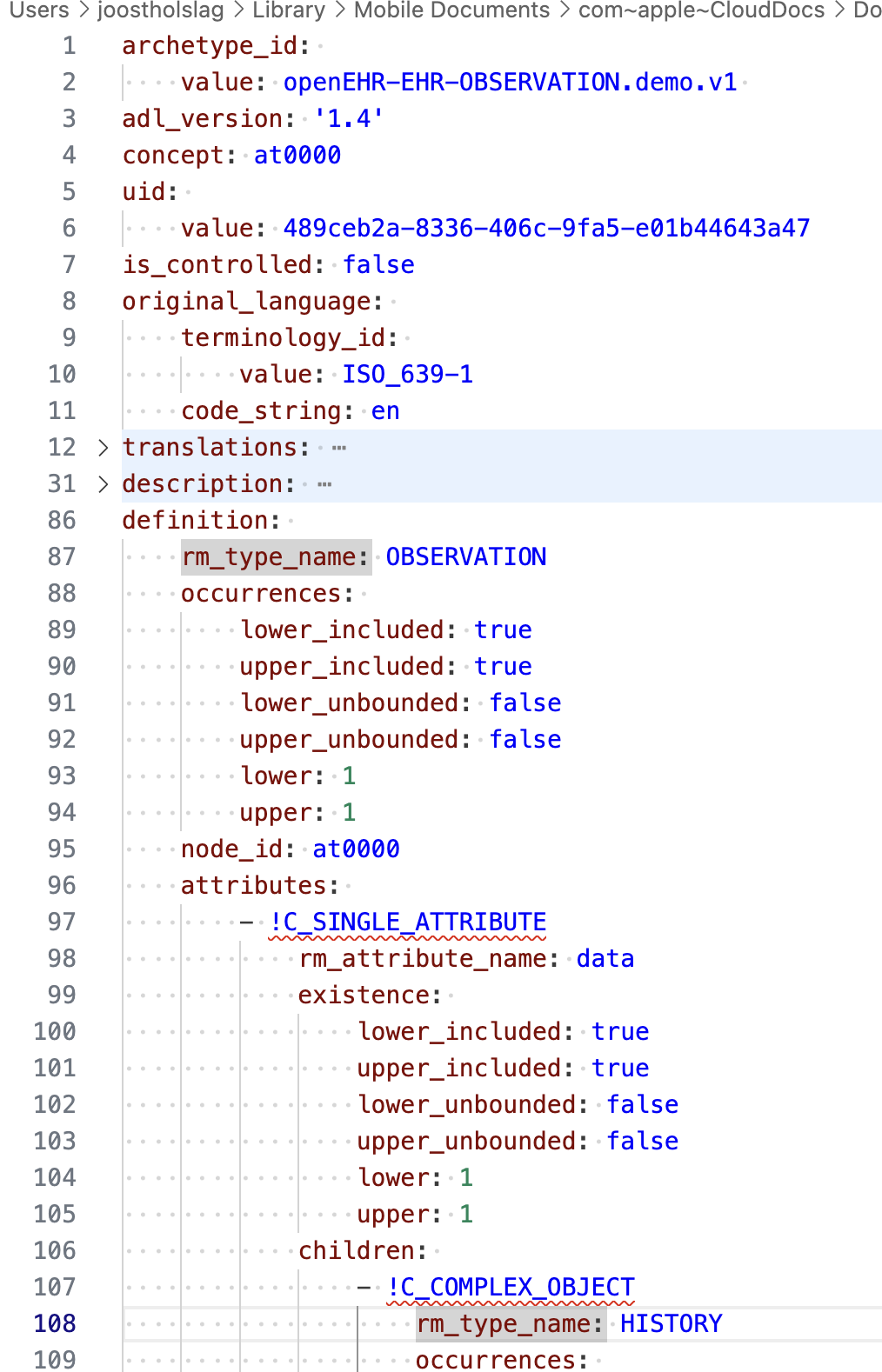
All the indentation, which is expected to occur a lot, will decrease legibility. This is on an iPad 11” so relatively small screen, and I never viewed ADL on iPad before, so definitely not the standard way of viewing archetypes. but still it’s probably an issue.