@joostholslag I should correct myself: YAML needs at least 2 spaces for indentation, but can take any number above that and will still be valid. The only thing is: all indentations should be consistent. I think having some 2 space and some 4 space indentations will break the format, since it uses the indentations as delimiters to know where a tree starts and ends.
1 Like
That’s why I said before that I see YAML problematic for manual edition.
9 Likes
I would hope that editors would help with that but I still think there is little to choose between JSON and YAML in terms of editabilty/ human readability and JSON has much more utility in terms of further processing. I’m happy to see both plus others like XML but if we had to choose one or a primary target for tooling, I would go for JSON.
But I m’m quite clear we need to have something that parses out-of-the box without any kind of custom parser. Regrettably I think that means that we need to move beyond cADL now.
3 Likes
We already have that. JSON. An in-memory archetype can be saved and read in today from JSON. But it only works for validated artefacts. It’s perfect for post-validation computational use. For the entire post-authoring / post-validation sphere of activity, this is exactly what tool environments should do.
But we are mixing that up with upstream authoring and validation, i.e. the production of artefacts in the first place.
It is very difficult to represent a partially written or draft artefact of any kind, containing formal errors (which may be intended for draft purposes for some reason) in the post-parse meta-model form. And as I noted above, it’s close to incomprehensible for human editing.
There’s a reason we have ‘programming languages’ that are human comprehensible syntaxes… They are also indispensable for educating people in the first place, to understand the semantics of the meta-model.
In sum, if you want to go solely with meta-model representation, and have no ability to edit source by humans, you still have to solve the problem of partial / draft / error-containing artefacts - probably with some private syntax / markup. This is certainly doable, but it’s limiting.
Aside from all that, what’s the problem with using a ‘language’? There must be 50 languages targetting the JVM. No-one suggests we stop using them and just write in bytecode (which is the kind of thing we wrote in in the 70s…)
Other attempts to do what ADL does are layers of language / syntax over the top of any possible generic representation:
Here’s a bit of Shacl:
ex:ClassExampleShape
a sh:NodeShape ;
sh:targetNode ex:Bob, ex:Alice, ex:Carol ;
sh:property [
sh:path ex:address ;
sh:class ex:PostalAddress ;
] .
Here’s a bit of SysML2 (p 643 of the spec):
individual a:VehicleRoadContext_1 {
timeslice t0_t2_a {
snapshot t0_a {
attribute t0 redefines time=0 [s];
snapshot t0_r:Road_1 {
:>>incline=0;
:>>friction=.1;
}
snapshot t0_v:Vehicle_1 {
:>>position=0 [m];
:>>velocity=0 [m];
:>>acceleration=1.96 [m/s**2];
snapshot t0_fa:FrontAxleAssembly_1{
snapshot t0_leftFront:Wheel_1;
snapshot t0_rightFront:Wheel_2;
}
}
}
snapshot t1_a {
attribute t1 redefines time=1 [s];
snapshot t1_r:Road_1 {
:>>incline=0;
:>>friction=.1;
}
snapshot t1_v:Vehicle_1 {
:>>position=.98 [m];
:>>velocity=1.96 [m/s];
:>>acceleration=1.96 [m/s**2];
snapshot t1_fa:FrontAxleAssembly_1 {
snapshot t1_leftFront:Wheel_1;
snapshot t1_rightFront:Wheel_2;
1 Like
If I understand Ian, the wish is to simplify entry of new openEHR implementers. For them, using a validated JSON representation of archetypes and OPT2s, would simplify things a lot. But as you mentioned, this can be done even if ADL is one of the supported formats.
I initially thought that even non-valid archetypes could be saved as JSON, but the JSON would at least have to be valid enough that the editing tools would be able to import it if exported. This can be done by skipping the JSON schema validation step, but it could be tricky. However non-valid ADL cannot be read by the tools either (but as you mention it can be easier to edit by humans to fix the errors).
I came to openEHR from another ANTLR project so it was exciting to use it again. However things turned less exciting after realizing there are multiple “official” grammars for ADL. I ended up making my ADL parser “compatible” with the grammars Archie is using.
Even with my experience with ANTLR, I wouldn’t mind using JSON instead of ADL. Especially since my tools can generate all the code required to deserialize JSON to AOM in 5 programming languages so far (my Kotlin version of the tools use no BMM and ADL parsers and only rely on JSON version of the archetypes/OPT2s).
However my initial experience with the JSON version of the archetypes/OPT2s was also problematic since Archie, ADL WB and my tools serialized them differently. All these differences are fixed now (thanks to strictly following the BMM for AM by all the mentioned tools).
Replacing ADL for archetypes is probably possible if all the editing is done with GUI editors (by serializing AOM into JSON and other formats).
I learned that many implementers will shy away from openEHR because of the DSLs used.
I’m sure there will be beautiful new BMM3, ADL3 and EL grammars at least in the “US version” so I might be able to experience both approaches ![]()
3 Likes
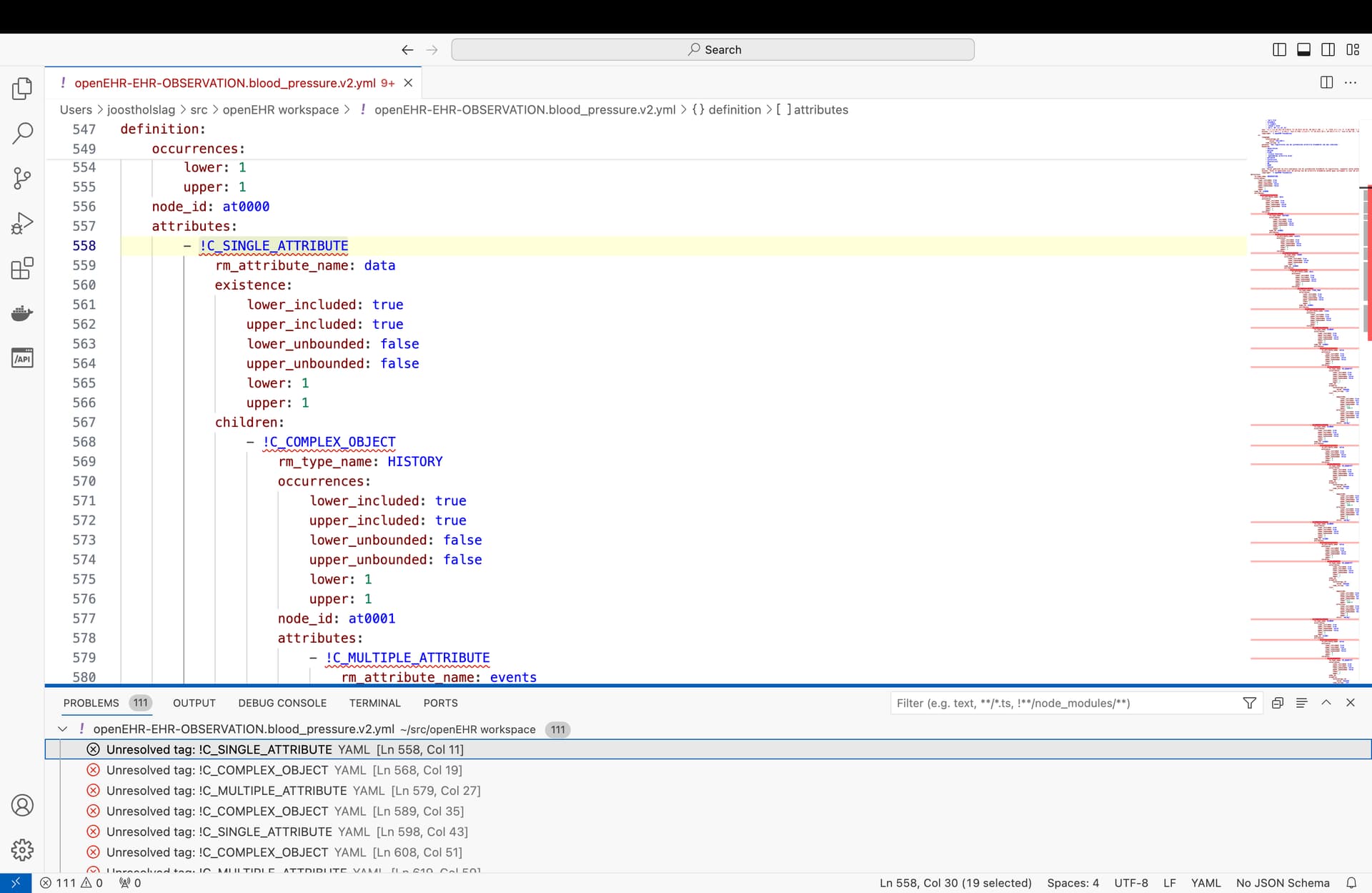
I’m trying to open this file in VSCode and associate it with the json-schema, so it supports validation and code completion.
I cloned the schemas to “/Users/joostholslag/src/specifications-ITS-JSON/components/AM”. I put the .yml file in ~/src/openEHR workspace and edited ~/src/.vscode/settings.json to exclusively contain:
{
"json.schemas": [{
"fileMatch": [
"*.yml"
],
"url": "/Users/joostholslag/src/specifications-ITS-JSON/components/AM/Release-1.4/Archetype/all.json"
}]
}
based on JSON editing in Visual Studio Code this should be enough. But it’s not recognised:
any pointers?