This is exactly why I was looking at GraphQL in the first place. Apollo Client has already implemented this in most frameworks (including Svelte, React, Angular, Vue) for GraphQL interfaces. And it’s not an easy task to redo all that work. And I believe Apollo Client will also start supporting REST in the future.
As for this,
I completely agree. The network topology does matter in most cases. Takes these scenarios:
Scenario 1:
Multiple services are hosted across different data centres and cloud providers. The client has to make a request to all of these providers to get the data they need. Having a GraphQL aggregator server in the cloud is may not guarantee that it can aggregate the results faster than the client. However, consider these factors:
- The bandwidth and latency of the cloud GraphQL instance is probably always going to better than the client device which will probably be on WiFi, or 4G data connectivity.
- The client device has to make 2x the times of requests owing to CORS policy of the browser that hits the OPTIONS endpoint and makes the request only AFTER the results arrive.
Is see GraphQL as the winner here. Unless the client is using the application on a very stable broadband connection.
And even then, consider this example:
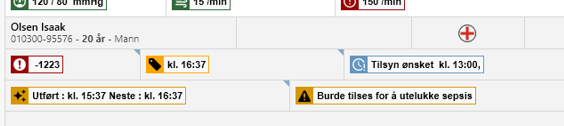
I was working on this dashboard that has to show the latest covid result for every patient. The covid results are in an openEHR server. The patient information is in a FHIR server.
I want to make the minimum number of requests and render this UI for 50 patients.
FHIR GET Patient List - 1 request.
AQL for the Covid results for all patients. I don’t know any way to get the latest covid result only for each patient. And most patients have multiple test results. Currently, I’m doing this however, I just want to get the latest result for all patients.
So best case - 1 request (get all results and filter on the client), worst case - 50 requests (1 AQL for each patient)
And I can’t help but think, for the server, doing 50 such queries is not a big deal, but sending that data across the wire is where the problem lies. If we have GraphQL, I don’t have to be limited by this limit. I can just as easily generate 50 queries and send it over as a single request and get back the response in an instant.
This is where I think GraphQL’s biggest benefit will be. Getting exactly the data needed, in the shape requested. Take FHIR’s Bundle requests for example, multiple requests can be Bunded into in 1 request, and I don’t know what I’d do without them.
With tools like Apollo Client (as mentioned above) GraphQL just makes more sense when building real-time reactive applications for mobile devices. (Think Firebase, but open-source)
Scenario 2:
The services are on the same data center/cloud provider in the same region.
The GraphQL aggregator will definitely be faster in this scenario.