Here is a little something for aql implementers that I know of (where Ian counts for EhrBase) @bna@matijap@ian.mcnicoll
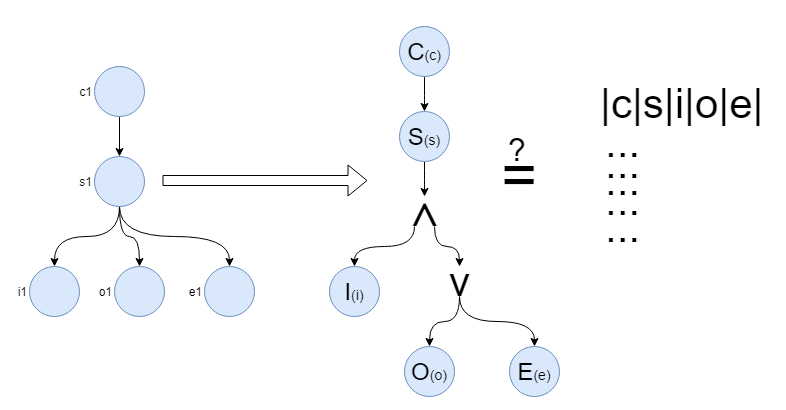
Given the composition on the left, and the AQL query after that, what should the result set for the select clause on the right be? Take this as a tease between me and you in a light hearted way please think on it whenever you have some free time.
So if we assume that the second CONTAINS is distributed over the Boolean operators in the usual fashion, the query will indeed return everything, since the logical condition is satisfied. However, the CONTAINS semantics over logical operators is not defined in the current spec (other than ‘by example’)…
Naively - because I do not ‘get’ resultset rows at all, if there were a single candidate composition in the EHR, I would be saying 5 rows for each object in the Select.
One for the composition, one for the section, one for each entry.
Ah I see, the Q is about the return row structure. In that case, the SELECT part is arguably invalid, because it cannot be satisfied by some possible FROM structures, which can be C/S/i+o and C/S/i+e. It can only be satisfied by a FROM part as follows:
FROM
COMPOSITION C c
CONTAINS
SECTION s
CONTAINS
INSTRUCTION i AND OBSERVATION o AND EVALUATION e
Now, if there happen to be any C/S/i+o+e instances in the data, the SELECT part can be seen as valid, and will return a row with {C, S, i, o, e} in it for each distinct instance in the EHR. Otherwise it should return nothing.
So the main questions here is:
how to validate the SELECT part if it implies a different FROM part (equivalently, the FROM part does not guarantee a base data set that can always satisfy the SELECT projection)?
Right now, AQL does not specify these validity criteria, but it should. I would argue that the original query is invalid on the grounds that the FROM part specifies possible structures that make the SELECT projection impossible to obtain. If we took the opposite stance, we would have to say that a SELECT projection only has to be possible w.r.t. the FROM data, not guaranteed. I think this doesn’t make sense, because it ignores the fact that the FROM part is just wrongly specified.
Additional remark: the C/S/i/e/o SELECT part doesn’t really make sense anyway, since it is returning the outer containers (the C and S) and the things they contain. If we really want to allow that, then it also has to be stated whether you are getting separate clones of the S, i, e and o, or else if the contained items are just refs into the outer containing C structure.
I have discussed with my developers, and we stand by my previous statement with two rows.
The reason is that you have two possible leaf branches with the OR between observation and evaluation.
We agree that the problem presented is problematic. There is no existing shared rules on how to interpret such functionality. The presented problem is similar to the use-cases we presented a few years ago on the permutation problem.
I guess of we have “SELECT a, b” a validity rule could be “b should not be included on a” and vice versa, since that will clearly maps a tree structure into the plain row/column structure, like:
a1 | b1
a1 | b2
(if the a1 instance contains b1 and b2 instances)
That might work if returning structures, but the same happens if we return any attributes of “a” and “b” and “a contains b”. So if we have: “SELECT a/path, b/path”, “a shouldn’t contain b an vice versa” (I guess is the same rule at the object level, but now considering paths).
Okay, finally had the time to try this out on our server and it returns one row.
I see no reason for there to be two rows. I see how it could be 3 (i.e. returning all possible combinations: with just instruction, with just evaluation, and with both), but that would make no practical sense. I haven’t studied the AQL spec, but logically there is an OR operator in containment, not XOR, so why exclude one or the other in each row?
@matijap many thanks for taking the time to respond. I appreciate, same goes to @bna
To clarify, I am certainly not advocating any particular behaviour, but I want to find out how you see some particular semantics and have a discussion between vendors. I chose these teasers based on some questions I’d like to bounce of you all.
Now, given your perfectly sensible response and question, may I kindly ask you to take a look at teaser 4, which I just posted? The interpretation/behaviour which doesn’t make sense (initially) here, becomes important in teaser 4, or else, two implementations can return the single instruction instance under column i_1 or i_2. I’ll stop talking about that teaser here now, but I’d love to get your feedback on that one, keeping your reasoning on this one in mind.
I’ll then extend the discussion to others (maybe I should just put all together in a single post?)
Before even looking at Teaser 4 (and I’ll probably progress through 2 and 3 first, although I think I have an idea of what #4 might be like), I’d like to add that actually we interpret disjunction just like SQL RDBMs interpret outer joins, so in case of multiple occurrences we return a cartesian product (by default; we have more proprietary tricks up our sleeves). And if multiple variables can match the same object (i.e. two INSTRUCTION variables with identical archetype predicate), we’ll return them in all possible orderings, unfortunately. (And if that’s the question in teaser #4, I’ll congratulate myself for the guess with a beer in the evening.)
Edit: as explained in teaser #2, there is an added condition in this join that the two variables cannot represent exactly the same object, so if you require containment of two instructions with the same archetype, a composition that has only one will not be selected, and for a composition with 2 matching instructions (call them i1 and i2) you will get 2 rows (for permutations (i1,i2) and (i2,i1)), not 4 (you will not get (i1,i1) nor (i2,i2)).
The beer certainly is on me @matijap and a well deserved one.
I was curious about the behaviour of your implementation in different cases, since that’s where differences in resultsets will come from among vendors.
My understanding is your interpretation of disjunction changes based on the number of matches.
Would you say that if a pre-defined simplification is applied to the permutative interpretation, where possible, that would describe the behaviour of your implementation?
Well, not exactly, I thought there would be a conjunction in #4, but there is disjunction, and it makes a lot of difference. If there was conjunction, and if we accept the fact that two variables cannot represent the same object, there are clearly no rows. But for the disjunction case I’ll answer in teaser #4 thread.
Actually, based on your answer, it doesn’t Well, at least one aspect of your answer I was referring to. You’re clearly thinking in terms of permutative behaviuor, i.e. all possible rows the query can generate given the composition, then you’re removing some of those, which is what I referred to as simplification.
Your verbal definition may be removing duplicate rows as much as possible, but the end result is the same. You have a starting, maximal set or rows, then you remove as much as you can, for the purposes of convenience.
My point and the reason I gave an example based on disjunction, is the consistency argument. If you apply the logic above to conjunction, it would make sense to apply to disjunction, wouldn’t it?
And your answer actually does that, both here and there. So you still deserve the beer
I disagree we want to have that rule. The user may select whatever they want and they have to consider the consequences. And there definitely is use for “select c/uid/value, instr from composition c contains instruction instr[…]”. Our implementation does support packing into arrays instead of producing cartesian products, but I do not think that should be default, at least not in this version of AQL when we have so many successfully working production queries out there in the wild.
While this can have the same end result, it is not the terms I like to think in. I prefer to say we are binding objects to variables, recursively over all variables, but only objects that have not been bound to other variables are considered for the next variable. If there are no unbound candidate objects left and the variable is part of a disjunction (OR), we can leave that variable empty. Now, this means that in the teaser #4 we would actually only have one row (i_1 would never be empty because we could bind it and then there would not be any objects left for i_2). Well…
 think on it whenever you have some free time.
think on it whenever you have some free time.