Ocean agrees. I won’t go into details, because I really want to keep these posts to discussions specific.
And this would be a case where your way of formalising the execution of a query breaks. I’ve been in this situation many times and this is actually where I’m coming from.
I’m not claiming that you’re doing anything wrong, you have a way of thinking, which allows you to explain the result set for this teaser, and the output contains all the bindings we’d consider as the minimum set to return.
Now when you apply the same thinking to teaser 4, it does not deliver the output that your implementation is already delivering, so your way of thinking is not suitable for generalisation to disjunction and conjunction, regardless of the number of data items in the input.
It is OK to think in terms of different ‘cases’ as long as we’re sure that our set of cases is exhaustive, but the way of thinking I suggested could deliver the minimum required results in both cases. Except, we’d then have to define case specific ‘trimmings’, to make things easier for consumer of result set, so there is still a trade off.
The important point is, if we identify and define cases in an exhaustive manner, we can guarantee all implementations would return the same results in all uses of logical operators with CONTAINS. These teasers are serving that purpose ![]()
Thanks a lot for your time and responses, this is very valuable.
I could probably argue a case that as a potential query creator, that if I ask for 3 objects in the SELECT, I should get 3 objects back … BUT!! … I would be very happy if the implementers got t together and said, no this is dumb, and you can’t have it. At least I know the rules and can adapt my ideas accordingly.
You hit the hammer on the head. As I said before, I’m very happy to make things easier for you, as long as we do it in a safe way, in the same way across all vendors. Sometimes it won’t be possible (to make it easy for you) but that’s a balance every query lang has to set.
1 Like
As an application developer, I would sometimes like to hit more than one fly with one slap (and would not like to select the entire composition and extract things from it when the EHR server can already do it for me).
I will point out that giving application developer so much freedom can sometimes lead to errors though; the following example from the fluid balance module of one of our end-user applications only works because the cartesian product problem is irrelevant if all templates limit cardinality of all those observations to at most 1:
SELECT c/context/start_time, c/context/other_context/items, ofo, ofov, ofof, ofou, cbss, c/uid
FROM EHR[ehr_id/value='$ehrId']
CONTAINS Composition c[openEHR-EHR-COMPOSITION.encounter.v1]
CONTAINS (
(
Observation ofo[openEHR-EHR-OBSERVATION.fluid_output.v1]
CONTAINS (
Cluster cbs[openEHR-EHR-CLUSTER.bodily_substance.v1] OR
Cluster bsa[openEHR-EHR-CLUSTER.bodily_substance-ascites.v1] OR
Cluster bss[openEHR-EHR-CLUSTER.bodily_substance-saliva.v1] OR
Cluster bsbc[openEHR-EHR-CLUSTER.bodily_substance-bile_content.v1] OR
Cluster bssemen[openEHR-EHR-CLUSTER.bodily_substance-semen.v1] OR
Cluster bsother[openEHR-EHR-CLUSTER.bodily_substance-mnd.v1] OR
Cluster bscsf[openEHR-EHR-CLUSTER.bodily_substance-csf.v1] OR
Cluster bslv[openEHR-EHR-CLUSTER.bodily_substance-lavages_vagina.v1] OR
Cluster bsblood[openEHR-EHR-CLUSTER.bodily_substance-blood.v1] OR
Cluster cbssweat[openEHR-EHR-CLUSTER.bodily_substance-sweat.v1] OR
Cluster bse[openEHR-EHR-CLUSTER.bodily_substance-exudate.v1]
)
) OR (
Observation ofov[openEHR-EHR-OBSERVATION.fluid_output-vomiting.v1]
CONTAINS Cluster cbsv[openEHR-EHR-CLUSTER.bodily_substance-vomit.v1]
) OR (
Observation ofof[openEHR-EHR-OBSERVATION.fluid_output-faeces.v1]
CONTAINS Cluster cbsf[openEHR-EHR-CLUSTER.bodily_substance-faeces.v1]
) OR (
Observation ofou[openEHR-EHR-OBSERVATION.fluid_output-urine.v1]
CONTAINS Cluster cbsu[openEHR-EHR-CLUSTER.bodily_substance-urine.v1]
) OR (
Observation ogz[openEHR-EHR-OBSERVATION.global_zn.v1]
CONTAINS Cluster cbss[openEHR-EHR-CLUSTER.bodily_substance-sweat.v1]
)
)
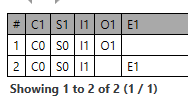
Based on the following AQL:
SELECT
c/name/value as C1,
s/name/value as S1,
i/name/value as I1,
o/name/value as O1,
e/name/value as E1
FROM
COMPOSITION c
CONTAINS SECTION s
CONTAINS (INSTRUCTION i
AND (OBSERVATION o
OR EVALUATION e))
The example data is given here: openehr-conformance/aql/case5-seref at master · bjornna/openehr-conformance · GitHub in the composition c0.xml|json
And if we change to an OR we get:
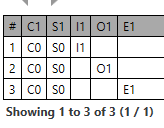
Based on the following AQL:
SELECT
c/name/value as C1,
s/name/value as S1,
i/name/value as I1,
o/name/value as O1,
e/name/value as E1
FROM
COMPOSITION c
CONTAINS SECTION s
CONTAINS (INSTRUCTION i
OR (OBSERVATION o
OR EVALUATION e))
And the data is located here: https://github.com/bjornna/openehr-conformance/tree/master/aql/case5-seref in the composition c0.xml|json
If the user or query designer don’t know the internal rules, they can’t handle the consequences because they don’t know what those are until the query is executed, and also will depend on the data set they are querying. I disagree on delegating the consequences of querying to users, when the rules are not explicitly stated. They don’t know what they don’t know, and they are not the developers implementing the rules. We have a gap there.
I think the current discussions should focus on AQL2 since we will introduce breaking changes, but IMO we will get a more solid spec that way, and quicker, instead of fixing all the issues AQL1 has now, and trying to harmonize different implementations along the way.
No disagreement here, we need to define processing rules. You were kind of suggesting we can avoid that by hampering the AQL somewhat. What I disagree with is both the conclusion (that doing this will simplify processing rules definition or even remove the need for it) and the general direction of the idea (hampering the query language).
2 Likes
Based on slack debate, I’m commenting on this one more time at the risk of repeating myself. This renders us unable to do one of the probably most common type of query: “give me all observations of some kind, and let me know the UID of the composition they’re found in”, so “select o, c/uid/value from composition c contains observation o[some_archetype]”.
2 Likes
I agree @Matija. I don’t think we should be breaking things that for the most part work extremely well. It is only when the CONTAINS clauses get complex and nested that the confusion arises.
1 Like
Completely agree.
and many more. As you said another thread, this makes AQL almost completely useless.