@borut.jures Awesome!
And how to deal with Observation.referenceRange with Cardinality 0..* and its various subelements? For example, lab-specific reference ranges rather than generic ones.
Thank you @linforest !
The US project had some 3000 lab archetypes. Synthetic data was generated using relevant reference ranges (see interpretation_intervals below):
# Formulas
rules:
# LOINC based formulas
loinc:
# Body temperature
8310-5:
uri: http://loinc.org/8310-5
name: Body temperature
set:
- attribute: value
element:
value_intervals:
deg_C_snomed: 35.0..38.9
deg_F_snomed: 90.0..102.0
interpretation_intervals:
deg_C_snomed:
low: 36.1
high: 38.0
deg_F_snomed:
low: 96.98
high: 100.4
BTW, this yaml syntax reminds me of the FSH language for FHIR.
The “is-about” mappings per leaf node as mentioned by @thomas.beale and exemplified by @borut.jures make a lot of sense, and I agree they could help future-proof some AQL queries where the full intra-template context isn’t relevant. But there’s also the risk of making modelling completely untenable, if it’s dependent on some external terminology over which modellers have little or no direct control.
I’ve taken part in some efforts to map archetype nodes to SNOMED CT terms. Even when you’d think mapping should be easy, such as the main quantity nodes of vital signs, there are nuances between the intended semantics of the archetype nodes and the semantics of the SNOMED terms. This leads to year long discussions and endless processes to introduce new terms, and it’s a complete and utter nightmare.
I completely agree about the nightmare part, but it would make the data truly interoperable.
Imagine openEHR archetypes with “is-about”. Archetypes would be a gold standard even if openEHR is not used.
Maybe? But I’m not sure anyone would want to model them? I certainly wouldn’t, after my previous experiences.
I share your views on this @siljelb There is most certainly added value in adding external reference bindings to key archetype nodes, but there are indeed real challenges in selecting/agreeing the correct terminology, especially when the context can change subtly depending on both the parent archetype and the template. Trying to invest all of that complexity in terminology (post-coordination) ends up being impossible to manage.
So yes, let’s take advantage of the developments in LOINC/SNOMED but it is absolutely not a panacea - path-based querying remains very, very helpful IMO.
For various observations, IMO, LOINC codes would be better than SNOMED CT codes.
The practice/approach of fully controlling semantics might be an impossible task for our openEHR community (esp. Clinical community ), and it would be also not very welcoming/friendly to adopters and implementers, even though it may seem perfect.
Absolutely. This is not about choosing one approach or the other, it is about finding the right balance between creating meaningful information structures and defining their semantics. Both are important things to address.
I understand that I’m wishing for (almost?) impossible to have the archetypes “is-about” coded, but it just doesn’t seem right that systolic is at0004 instead of http://loinc.org/8480-6 ![]()
Another issue is that any external terminologies like LOINC and SNOMED CT are unlikely always to meet the standard code requirements of openEHR in real-time or very promptly, for various reasons.
It’s not at0004, it’s “Peak systemic arterial blood pressure - measured in systolic or contraction phase of the heart cycle”. And that LOINC code (like its corresponding SNOMED CT term) isn’t specific enough: according to its name and definition “System: Arterial system” it could just as well be the systolic pulmonary blood pressure.

![]() this is exactly why it’s a nightmare to base archetype element semantics on standardised terminologies.
this is exactly why it’s a nightmare to base archetype element semantics on standardised terminologies.
I understand that working with the standardizing committees is no fun and in practice (almost) impossible. It is sad that this is a reason for not coding the archetypes (this is a critique of the committees not modelers).
However, without the coded archetypes, aren’t the same discussions just postponed until somebody wants to figure out what an element represents (e.g. data mapping between systems)? The decision is then made by a technical person who usually doesn’t know about the subtle differences in healthcare data/concepts (even systolic can be many different things). And they are tasked to produce results “immediately”.
I still hope one day all the knowledgeable humans will be able to work together to produce “The Models”. openEHR models are an important part of this effort and I ![]() to the modelers.
to the modelers.
Some answers to that here. Needless to say, if we went to openEHRv2, it would be for the next 20y, not an endless rollout of breakages each 2 years…
That would work in an openEHRv2 system of course. Data migration from openEHRv1 to v2 would be needed for those systems and vendors that wanted to do it. But the improvements (having build quite a few of them) are definitely worth it. And it would be one of the easiest data migrations ever. People get worried about breaking changes to openEHR (and that’s reasonable, don’t get me wrong), but routinely don’t think twice about endless data conversion in and out of openEHR, HL7v2, FHIR, OMOP, IHE, X12, and more - and these are not the same RM with breaking changes, but different paradigms, generally with difficult to reconcile semantics. Those conversions are creating errors and omissions in data all the time. So we need to be realistic.
We should definitely take note of this. However there are some changes so central that they change everything. So it’s worth considering whether we hang on to openEHRv1 longer and keep grafting non-breaking improvements, and bite the bullet later (more data, larger models deployed) or do it sooner. Both paths are possible, and probably both are reasonable, but the costs and consequences need to be understood.
Breaking changes can be managed well, or badly. We need to do it well. We have coherent architectures and a good community approach to change management.
@damoca as an aside, you and your pro team should think about what actual coding could be used. In our experiments at Graphite, we used LOINC, because Stan Huff was able to get an agreement for them to add new codes. But (as we all know), LOINC is not naturally a taxonomy-based terminology - it’s a multi-axial one identifying vectors in an N-space. Theoretically Snomed might work, but it’s full of precoordinated junk and too many errors (despite best efforts) for my taste. I’d rather build a terminology that covers the space properly, and parsimoniously (I once asked Alan Rector: if he had the chance, would he ditch Snomed and start again? He said yes, you only need about 100k terms and relationships to do it cleanly).
There are two kinds of terms needed to do is-about coding:
- terms to code epistemic elements, e.g. data points in the medication order archetype
- we have to build this, it doesn’t really exist properly
- terms to code ontic elements, e.g. anatomy, heart rate/rhythm and so on
- we need to consider re-use, adaptation, development of things like OGMS, FMA, other OBO ontologies etc.
If we do this again, I don’t want to use LOINC, let’s do it properly. You expert input will be essential in that exercise ![]()
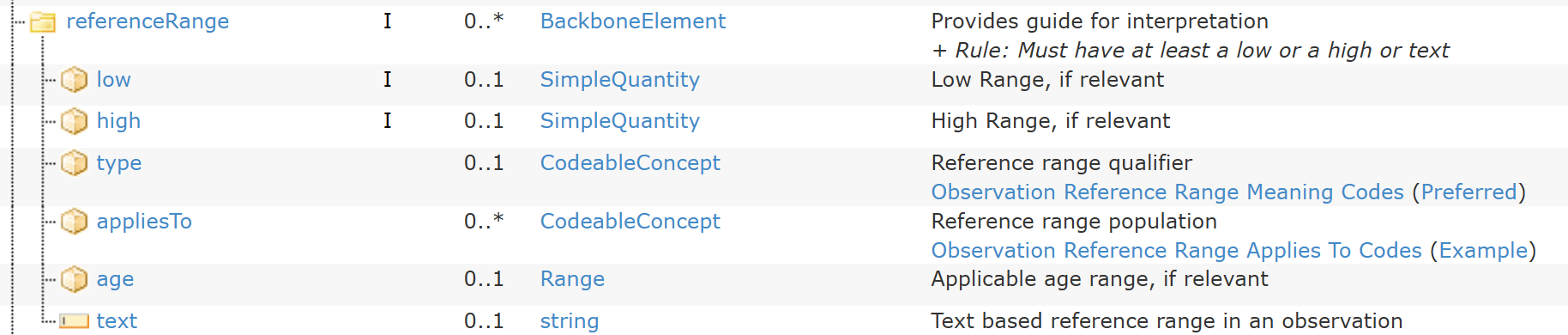
We also had an improved model of Reference range, which included some of those other meta-data items.
Not if we take control and build our own (as well as use applicable existing resources like BFO, FMA etc). People wildly under-estimate the difficulty of continually compensating for all the errors and pre-coord terms in SNOMED (and I’m not trying to be critical here, it’s just an objective fact, and the result of endless organic growth on a foundation built by people who knew nothing about ontology), and they wildly over-estimate the difficulty of building good detailed ontologies.
It’s because SNOMED doesn’t distinguish between epistemic entities (observed x, measured x, predicted x) and ontic entities (x). And openEHR doesn’t distinguish that cleanly either, although it is intended as a fully epistemic information ecosystem, i.e. openEHR is a ‘recording’ concept, not a describing-reality concept (that’s the business of things like FMA).
I think we could show some things that would make this look less daunting. Avoiding Snomed as the primary terminology would be one. We’d provide secondary mappings into it, but for reliable computation, we wouldn’t use it. I know, total heresy, but we need to be much more objective about how things are really going to work for the next 50+ years. We are going to need much better semantic architectures than we have today.
One of the other things we did was significantly flatter paths (the subtyped Observation helps a lot with this). The paths we ended up with were much more comprehensible. Query evolution with such paths would be easier than it is today.
But the gold standard of interop in the future will be ontology codes (which might be human comprehensible, like they used in OBO-land) not model paths. That has to be the case, because many / most of the paths we use correspond to ad hoc epistemic structures that help our human minds understand the data more easily (e.g. separating ‘data’ from ‘state’), but which don’t really exist in reality.
It’s one reason we used it in the US experiment, LOINC is oriented to naming observations. But it has no taxonomic hierarchy, i.e. no IS-A relation. The recent LOINC/SNOMED agreement allows the IS-A relation in SNOMED to be used to assert IS-A relationships between LOINC terms. But it’s very clunky in my view.
Exactly ![]()
It’s why we need our own. We can stand on the decades of learning from those and other terminologies, but just like with openEHR itself, sometimes you need to start clean.
Far from a nightmare, even with LOINC. We actually obtained close to 1000 net new codes over a 18 month period. They were very cooperative. People really want this to happen. People like Stan have been thinking about this forever. It was very useful to actually do a trial run.
Indeed.
I totally get the point, though for systems to deal with concepts you will end up with some type of code. You can pick X or Y, but at the end you need to pick one. The alternative to codes is to have a full dictionary entry as the definition of the concept, which can include a code, but is more complete. On the other side, you might need to have complex concepts, which have different attributes and data structures. So at the end, you might have a whole archetype as the concept definition, and IMHO paths are just codes to reference subconcepts inside the parent concept. So if you don’t filter by archetypes and paths, you will filter by codes or something that is like an archetype and path.
Then the discussion about the codes is if the codes are expressive enough to represent the concepts that you have as archetypes and the subconcepts/elements inside them. If you can’t find the same granularity inside the terminology/code system, then the alternative is to construct one yourself. At the end you will end up with a huge terminology that is just a representation in a different model of what you already have in archetypes with paths. I think this is just doing the same thing with a different representation. (as we say in Spanish: same dog, different collar).
Under the microscope, what you need is enough bits to represent a unique concept in detail, and how you organize the bits might not be so important: codes vs. archetype+path vs. … you always need those bits.
Though my view might be biased by my own experience. If there is a way of storing, managing and querying that really that is more semantic-based and has advantages over archetype+path, please show me ![]()
When we say ‘code’ that’s just shorthand for an identifier that is a key to such an entry, although it will be in an ontology with at least IS-A relationships asserted, and potentially other relationships as well (e.g. relationships from BFO / RO ontologies). So there’s no alternatives here - we’re talking full ontology.
Not if it’s done correctly; the ontology establishes what each data item ‘is about’, i.e. it establishes the description of what things in the real world any information can report on. It doesn’t need to replicate informational structures of archetypes. It may be that there are different archetypes, e.g. in obstetrics, that refer to the same thing (e.g. in detailed and non-detailed summaries). THe ontology will include this entity only once, and all using archetypes will use that one code to connect the archetype data point to the same ontology entity.