The Norwegian archetype governance is working with the Norwegian SNOMED CT NRC to bind a set of vital signs archetypes to SNOMED CT. Initially we were both thinking the same way with regard to how this should be done, with Observable entitiy and Attribute SNOMED terms beng bound to data elements, and other concept types such as Finding, Physical object, Body structure for value sets. We didn’t have an agreement on how or if the archetype top level nodes should be bound.
Lately though, they’ve pivoted into a new approach, where they want to bind the top level node of the archetype (at0000) to an Observable entity (for example 75367002 | Blood pressure (observable entity) | for the Blood pressure archetype), and data elements in the archetype to an attribute of the Observable entity or one of its children (for example 723228002 | Systolic phase (qualifier value) | for the Systolic blood pressure data element).
We think this is a misrepresentation of the semantics of the archetypes’ data elements. It feels like trying to recreate the SNOMED CT ontological structure within the archetypes, which isn’t the intent of archetypes, or indeed any other information models.
We’re struggling to argue why this is a bad idea though. Does anyone else have any thoughts about this?
To answer this one need to have good clinical-cardiac understanding and know quite a bit of SNOMED-CT and openEHR archetypes. I will try to give my cents anyway:
It contains a wide range of concepts that provide attribute values used in the definitions of other concepts. These values can also be used in expressions to refine the meaning of a concept or in the appropriate fields of a health record to add additional information.
The qualifier value is IMHO more an SNOMED-CT way to express attributes to make complex concepts. With openEHR (and also other information models) we don’t need this. This is already taken care of by the reference model (RM) and the arhcetype/information model (IM).
I also think that Systolic phase (qualifier value) is another concept than the Systolic blood pressure. IMHO the systolic phase is an attribute related to the cardio vascular process phase. The systolic blood pressure is a subset of information related to the outcome of this phase. As a non-cardiac expert I think they are not the same.
I look forward to hear more views on this very interesting topic!
I think you are right about this, the archetypes should not recreate SNOMED CT structure.
But there is a need to have term binding in archetypes, and unfortunately sometimes the requests are different. See for instance your requirements from Norway, vs current term bindings of the archetype vs dutch gov requirements of BloodPressure-v3.2(2019EN) - Zorginformatiebouwstenen (see their tables). I guess these are strong requirements per usecase, wheres the archetype intent is a bit more generic. Is there a solution that facilitates this, even tough the requirements might not be (completely) correct from openEHR perspective?
Other than that, @bna proposal seems right to me, but I don’t have terminology related background.
I think the approach being suggested by NRC is not correct. I took the opportunity to discuss with a UK SNOMED-CT terminologist and he agrees.
THe SNOMED-CT concept models are primarily arranged around models of biomedical entities - a systolic blood pressure reading is a kind-of blood pressure is a kind of pressure etc.
That is not what we are doing in openEHR (or indeed FHIR) - we are representing parts of the patient record, not the patient’s physiology/biology etc at least not directly.
These worlds intersect but I would be saying that archetypes are generally record artifacts in SNOMED terms with something like systolic being an Observable. This pretty well lines up with what has happened in any work I have done in the UK and I am pretty sure is what is happening with comparable FHIR bindings. If that Observable (inside SNOMED CT) is fully defined using the systolic qualifier, that is absolutely fine - I asm not sure of the value but that’s not my problem!!
It is an important discussion which should probably go back to SNOMED International - certainly a wider view.
@sebastian.iancu - Interestingly from what I can see of the Zibs model, they use SNOMED valuesets but not to bind to the node names (which is the issue we are discussing here). The FHIR models look as if they actually use LOINC codes as per US Argonaut standards.
These are the UK bindings which I am pretty sure are identical to those recommended by SNOMED International.
“<<271649006|Systolic blood pressure (observable entity)|
MINUS (<<716579001|Baseline systolic blood pressure (observable entity)|
OR <<814101000000107|Systolic blood pressure centile (observable entity)|
OR <<315612005|Target systolic blood pressure (observable entity)|)”
This is the big problem with trying to apply SNOMED bindings to node names (whether openEHR / FHIR or any other model of a ‘record’- there is not a 1:1 correspondence between the biomedical categories that SNOMED uses and the record structures that we need. There are places (like Labs) where use of terminology is really helpful, indeed mandatory but this ends up being very hard work.
Hi All
I remember when I first had a go at this about 13 years ago with the BP archetype (it was new then) and had a room full of SNOMED experts advising me. They thought I used the wrong codes, debated it for 45 mins, took it off line and got back to me 3 months later and said they thought the codes I used were the most appropriate.
The hierarchical approach to use of codes is not appropriate in the openEHR frame - and probably wont work for FHIR either. Using the term blood pressure as a subsumptive term for all these measurements is also a major mistake. We had some good slides with Alan Rector in the old days to show the layout of the semantics. Ian - do you have those?
I were preparing to write an answer, but then realized that Bjørn and Ian already had written what I plan to write.
I therefore only add a simple illustration: If I would like to retrieve all blood pressure measurements in a patient’s health record (independent of if it is recorded using the blood pressure archetype or not) I would search for all observations that are concept bound to the concept 75367002 | Blood pressure (observable entity) | or any of its descendants. If the usual concept binding strategy (supported by at least Silje, Bjørn and Ian) had been used I would succeed.
If the other concept binding strategy (proposed by the Norwegian SNOMED CT NRC?) would be implemented I had to list all possible qualifier values that might be relevant for a blood pressure observation, including 723228002 | Systolic phase (qualifier value) |, 723229005 | Diastolic phase (qualifier value) |, 723241003 | v wave (qualifier value) |, in my query. The query would then retrieve blood pressure measurements but also all other kinds of measurements done during an explicitly stated cardiac cycle process phase. This is not how blood pressure measurement retrieval should work in a health record.
(I also believe that modelling 315612005 | Target systolic blood pressure (observable entity) | as a child to 315612005 | Target systolic blood pressure (observable entity) | is a modelling error. If the same apply to 716579001 | Baseline systolic blood pressure (observable entity) | I don’t have enough clinical knowledge to assess.)
Thanks everyone for your answers, I feel more confident we can clear this up now! Especially @mikael’s example makes it very clear how the different strategies would work in an actual health record.
I also noticed @ian.mcnicoll’s suggestion that archetypes generally are record artifacts in SNOMED terms. I interpret this as if you bind archetype top level nodes (at0000) to SNOMED CT terms, they should generally be bound to terms from the Record artifact subtree. I agree with this, because to my mind archetypes are groups of data elements constructed for recording information about a clinical concept, and not the clinical concept itself. Do anyone else have any opinions on this?
A few comments on this interesting topic …
I personally think that the first challenge here is to understand the key use cases for node-level terminology bindings, and from this determine the types of binding that would be most useful in these use cases. Possible use cases include:
Data capture - This use case primarily requires value set bindings to restrict the valid values recorded.
Retrieval and querying - Similarly, this primarily requires value set bindings. However, there are a few situations in which node-level bindings can be useful - e.g. using the SNOMED hierarchy to query using more general concepts, such as “Find me all the data in my patient’s record that is a type of |Cardiovascular measure|” (e.g. a |Blood pressure|, |Heart rate|, …) . The other type of terminology binding that is useful for this use case is an expression-template binding - these allow you to transform semantically-similar data stored in different ways into a consistent representation for querying (e.g. Problem=|Hip fracture|, Body site=NULL / Problem=|Fracture|, Body site=|Hip|) - (see http://snomed.org/sts)
Archetype library management - This primarily requires model meaning (i.e. node-level) bindings, and is in some ways similar to the ‘retrieval and querying’ use case. These bindings allow you to do things like - (a) Find me all the archetypes in my archetype library that are a type of |Cardiovascular measure|, (b) Find me all the archetypes in my archetype library that are semantically similar to this archetype (with ranking), (c ) Validate the specialized archetypes against their parent (with respect to their meaning)
Semantic interoperability - Message conformance testing requires value set bindings; Sharing data recorded using different models (and different ways of populating the same model) may require expression-template and/or model meaning (i.e. node-level) bindings.
In terms of node-level binding to data elements:
I agree with the suggestions that SNOMED CT attributes (e.g. 363698007 |Finding site (attribute)|) and SNOMED CT |Observable entity|s (e.g. 72313002 |Systolic arterial pressure (observable entity)|) are generally the most appropriate, with respect to the use cases above. Depending on the level of precoordination allowed in the ‘focus’ data element (e.g. the condition_code), it may also be useful to accompany any SNOMED CT attribute node-bindings with an expression-template binding to demonstrate how data can be transformed into a canonical format for querying.
I do not agree with node-level binding to the |Qualifier value| hierarchy (e.g. |Systolic phase (qualifier value)|). I can’t think of any examples for which this would be a good idea.
In terms of node-level binding to archetypes:
While I agree with the comment made above that these could be considered a type of |Record artifact| (e.g. a subtype of |Record entry|, |Record organizer| or |Record type|), I’ve only ever found this useful at the Composition/Template level. For example, binding a ‘Discharge summary’ composition to the concept 373942005 |Discharge summary (record artifact)| allows you to query your archetype/template library (or patient records) using the record artifact hierarchy. It has been argued that there is no point in replicating the archetype hierarchy as a record-artifact hierarchy - and while I agree with this for most entry and section-level archeyptes, I can see the benefit in doing this just for compositions/templates because (a) It allows you to query using abstract ‘grouper concepts’ that are in your SNOMED hierarchy, which don’t necessarily correspond to a single archetype/template (e.g. |Clinical report| or |Summary report|), (b) It enables you to use an approach that is consistent with querying archetypes for entries and sections.
For node-level bindings to entries, I think it’s unnecessary to create a new |Record artifact| for each of these. Instead, I think it’s more helpful to the use cases above to consider the node-level binding as indicating the ‘focus’ of the data it records - i.e. a node-level binding to X says that the entry “records data about X”. In the example given, the focus of the ‘Blood pressure’ archetype is a 75367002 |Blood pressure (observable entity)|. This is the clinical concept about which data is being recorded in the archetype … and knowing this can be really useful for querying (using the hierarchy and defining relationships of |Blood pressure|).
I would propose that, in general, an ‘Observation’ Entry archetype should have a node-level binding to (i.e. it ‘records data about’) an < |Observable entity| OR < |Assessment scale|; an ‘Action’ or ‘Instruction’ Entry archetype should have a node-level binding to a < |Procedure| MINUS < |Administrative procedure|; and an ‘Admin Entry’ should have a node level binding to a < |Administrative procedure|. ‘Evaluation’ Entries may be a bit more difficult to restrict to a single hierarchy … but I would suggest that < |Clinical finding| may be a good start. Note 1: “<” refers to the ‘descendants of’ (or subtypes of) the given concept. Note 2: Binding to explicit context (e.g. for family history) is also very important to consider, |Finding with explicit context| and |Procedure with explicit context| may also be required above. There is an argument to keep the context binding separate … but that’s a discussion for another day.
The more complex NHS binding mentioned above (as Ian suggests) looks like a value set binding rather than a node-level binding - based on the use of ECL and the fact that FHIR represents this in the Observation.code. While this could arguably also be used as the node-level binding, this level of semantic specificity is probably not needed in most of the node-level use cases above.
I haven’t seen anyone here mention node-level binding to clusters (or data groups) within an archetype - where these hold no significant clinical semantics, node-level bindings may not be required.
Apologies for the long post. I hope that some of this was helpful.
Kind regards,
Linda.
I think the SNOMED grammar (I’m not an expert) suggested that these should be *excluded *from the parent termset. I agree with the decisions there for now but I think I would rather have seen a set of agreed inclusions .
As you may know, there is a joint SInt+HL7 “SNOMED on FHIR” project which has produced a number of FHIR profiles, BP among them. NHS has participated in this work hence the similarity between the NHS and the SNOMED on FHIR bindings. http://build.fhir.org/ig/IHTSDO/snomed-ig/artifacts.html
While appearing in the systolic phase is a differentia of a systolic BP, choosing one such differentia for node binding seems odd and it is hard to see how that could be done reproducibly over time and over different use cases. Which differentia is to be chosen next time? What will be the binding for (core) body temperatures?
If the node in question is a “question”-like data element or a panel/battery of such nodes, a better practice would be mapping it to a LOINC code rather than a SCT code. One of the reasons is that there is a agreement between LOINC and SCT. And SCT codes are just like “answers” to those “questions”.
That would only make sense if the BP archetype was a formal description of the ontic Blood pressure entity, i.e. it was an ontological artefact. However, it is quite different; ontologically, it represents ‘recorded observation of (systemic arterial) blood pressure’, which is an epistemological artefact, quite a different thing. You already know this of course, but a clear, simple explanation of these two types might help you in putting people straight:
ontological artefact: an artefact describing a universal, or type of thing in the real world, e.g. blood pressure, diabetic person, etc; real-world individuals are instances of these types;
epistemological artefact: an artefact describing the information (philosophers would say ‘knowledge’, but this tends to get confused in the biosciences with research-generated knowledge) obtained as the result of some interaction with the real world, such as observation, inspection; and/or some internal reflection on already gained information, such as assessment, request, etc.
Indeed, this is an interesting post. And more two years ago, I seriously read it by fully translating it into Chinese. Without your mention above, I barely remember all this. And I’m reviewing it and my translation now. So highly recommended for those interested.
Digging up this quite old topic. As a result of this discussion were there any rules set in Norway on what archetype nodes would get a SNOMED-CT (or other) term-binding?
I am asking this because the Terminology Center within NICTIZ is reviewing there strategy for when term-bindings should be done and in the discussion they were leaning towards perhaps in some Cases (for instance a SYMPTOM zib: Symptom-v1.0(2024EN) - Zorginformatiebouwstenen one binding the root node and not binding the SymptomName. Which to me reading this discussion seems like a bad idea. Any documentation (from any country) on rules would be appriciated.
Also is it correct that we also don’t have any guidance for term-binding in the international CKM (couldn’t find it in the style guide)?
There is no clear-cut and absolute borderline between OWL and UML according to Harold Solbrig and other authors.
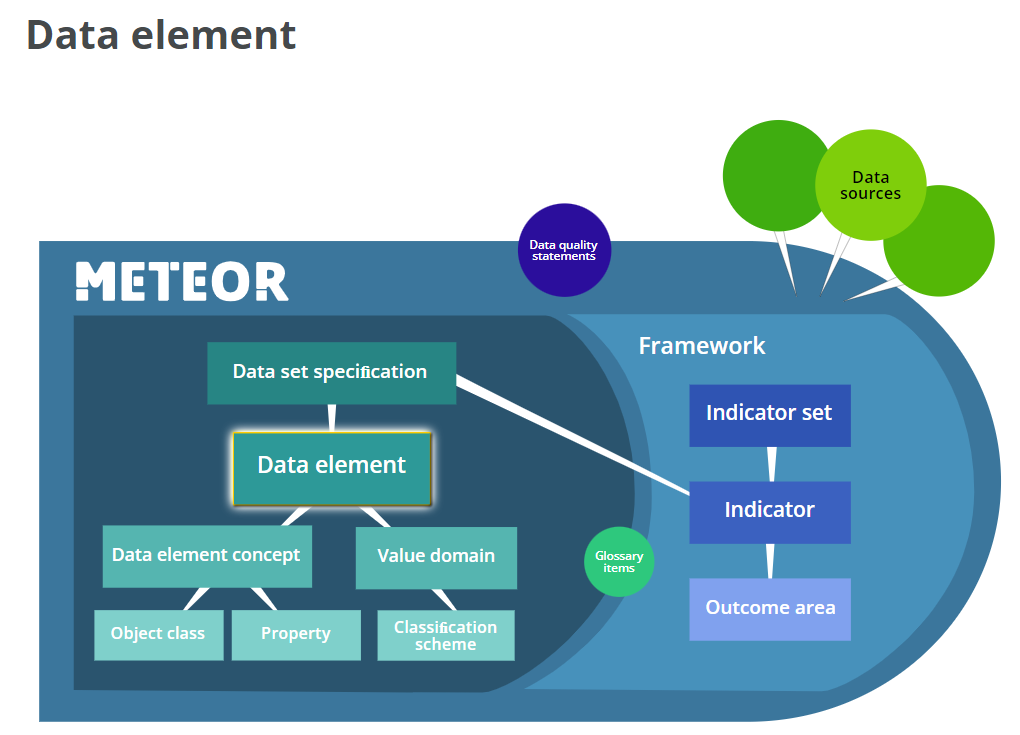
OpenEHR Archetypes as a kind of dataset (ISO 11179) mainly include a structured collection of data elements; Ontologies such as SCT include various concepts, including components of data elements (object class+property + value domains).
Although OWL can be used to datasets compatible with ISO 11179 metamodel, most of SCT hierarchies doesn’t include any proper ISO 11179 data elements.
In my current work at Graphite Health, we are now using LOINC as the universal terminology for marking model elements to indicate what they ‘are about’, i.e. to indicate the real world thing the information describes.
This is done by every id-code that is defined in the terminology (remember, many are not) having a LOINC binding. This is necessitating the creation of hundreds of new LOINC codes, which we are doing with LOINC.org.
Then we are binding value-sets to coded items, where we defined the value set, and its contents are terms from SNOMED, RxNorm, or another suitable terminology. This is done by binding value-set ids (URIs) to ac-codes from the archetypes.
That means that for every coded element, there is a logical structure of the form
name = LOINC code 1111
value = some code from value-set 2222, based on (say) Snomed
EDIT: I meant to mention that these models will be published later in the year. The LOINC code bindings could be applied to the openEHR archetypes - machine processing to do this should be possible.
For any org such as Nictiz thinking of doing this, let’s have a conversation on how to coordinate on the LOINC and value set binding approach - the world only needs to do the LOINC part once; and the value sets should also be eminently shareable.
The root node could be considered as a ISO 11179 Object Class (i.e., Concept) ; the names of its Data Nodes/Points could be considered as ISO 11179 Properties; actually, such Data Nodes/Points are ISO 11179 Data Elements.
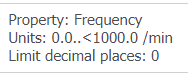
For example, the fully specified name of the Data Point “Rate” should be “Pulse Rate/Heart Beat Rate” and this Data Element has a non-enumerated Value Domain as followings:
It’s my current understanding related to this topic.
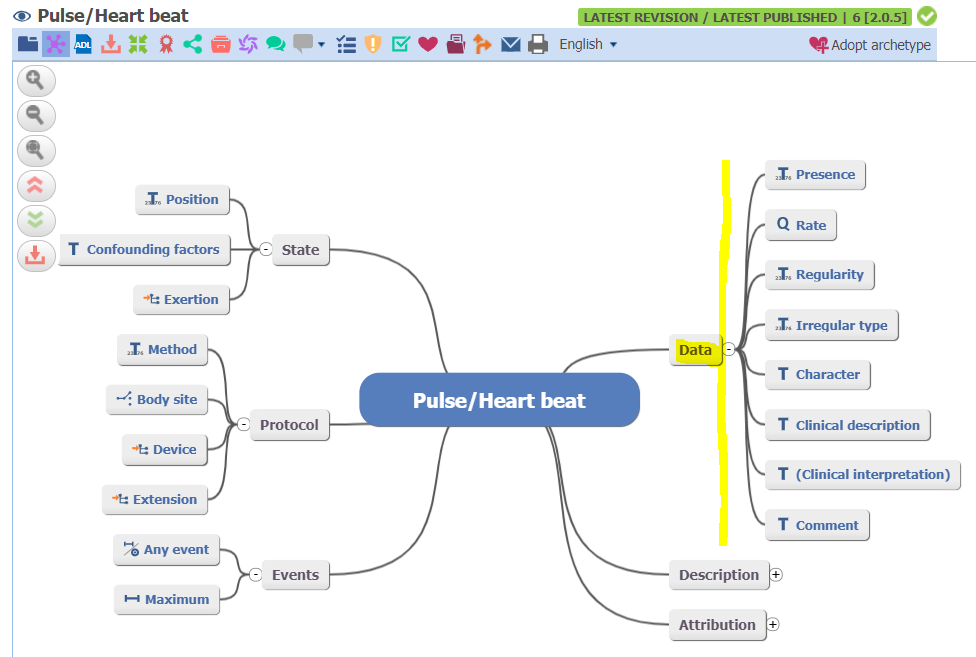
However, the Archetype Pulse/Heart beat per se looks like a Data Set Specification (a structured set of Data Elements) other than an Object Class. Here, consider Pulse Rate. The Object Classes should be Its Concept Name “Pulse/Heart beat” and the Property should be its Data Point name “Rate”…
Note: Illustration of Data Element and Dataset Specifications taken from AIHW’s METEOR
But when searching LOINC codes with keywords “pulse rate NRat”, there are 64 codes for potential matches returned. As we know, for the sake of generality, the Archetype is not designed with fixed values for some LOINC Axes such as Timing, System and Method, so it is impossible to map an openEHR Archetype Data Point to the exact matching LOINC code at the Archetype level but a set of potentially matching LOINC codes (i.e., a Value Domain or FHIR ValueSet). So, we may need to defer the exact LOINC mapping to the template level.