I have several times found (and reported) references to no-longer-existing archetypes in different archetypes. Perhaps the CKM should be enhanced with a function to scan and detect these things as they happen.
(An analogy: Programmers would hate to refactor a codebase without automated tooling for renaming a class that also changes references to the class they are renaming.)
Such obsolete references in archetypes are sometimes found in descriptive text (e.g. the use/misuse metadata field) and sometimes in archetype slot definitions. At least for the slots an automated reference renaming function should be possible. For descriptive text perhaps just a warning list/report poiniting to probable errors would be safe.
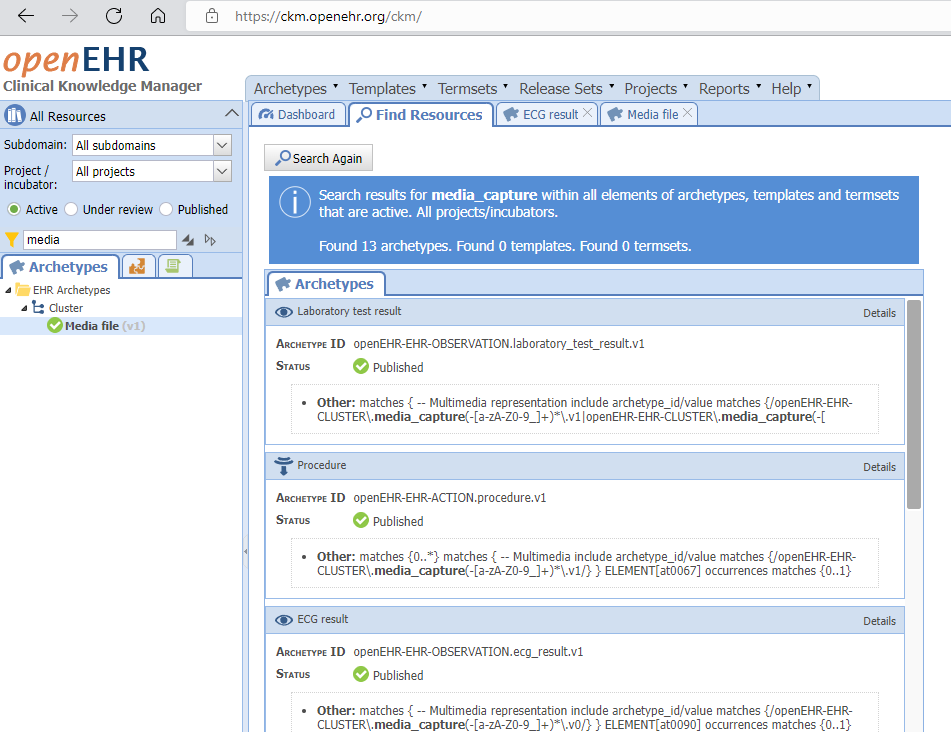
Example: 13 archetypes with broken references to the media_capture archetype
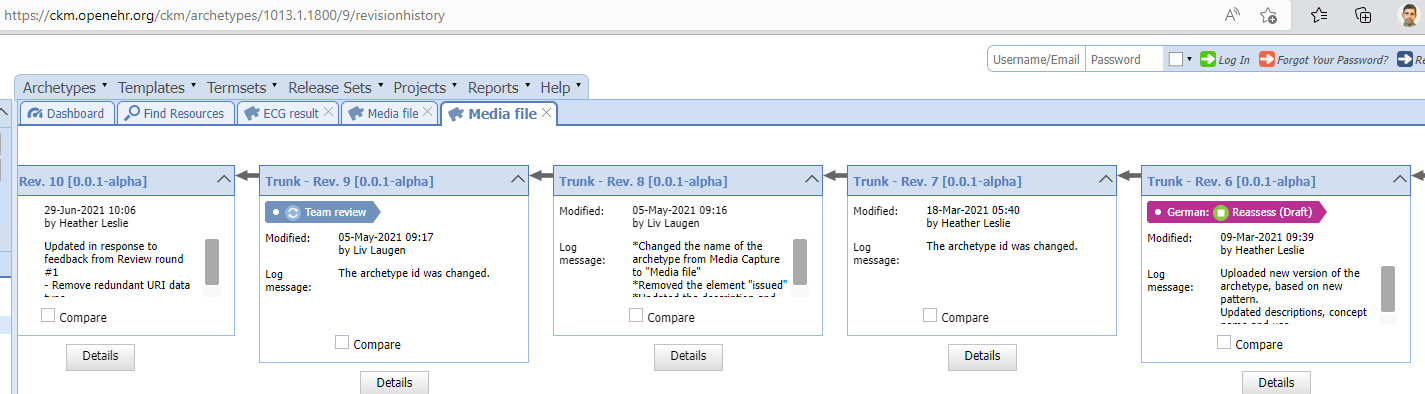
The cause seems to be the (very reasonable/sensible) decision to change the archetype’s id from media_capture to media_file, see image below. When renaming is done, then all references (at least in published v1+ archetypes) also need to be changed. Can we add this to some ediotorial process guideline or similar while awaiting possible future CKM/AD-tooling reminder support?
You can have all the best tooling and alerts and processes but without a human or two to maintain the CKM and its’ models. We currently don’t have any. We need at least one person who is tasked and resourced to do this on behalf of the openEHR community, including supporting the translation work of your team and others. I used to have that role…
There are so many aspects of CKM and the program that are not being managed because there are no program leads or, in the absence of leads, resourcing for others with CKA skills to do it.
Any current activity in CKM is funded by external sources and focused on reviews and publication, not unreasonably because that is the priority of the external funders. It is a workaround to keep the modelling work going, but not sustainable or viable in the long term
Have this same conversation with the Board, please.
I intended to have a conversation with anybody in the community interested in the issue, since it is of general interest, it was not directed to you personally. I believe several members of the board are already reading these forums, and also CKM developers like @sebastian.garde
Anyway, where are the current editorial process guidelines or similar documents - is there anything besides the page https://openehr.atlassian.net/wiki/spaces/healthmod/pages/304742407/Archetype+content+style+guide or is that the place to put a warning (once the clinical program is up to speed again)? (I can suggest an additional reminder sentence regarding renamings, but I guess I am not supposed to edit that page myself without some kind of consensus process.)
P.S.
Regarding external funding for practical work (rather than everything funded via a foundation), that is pretty much standard in Open Source projects, like https://www.apache.org/foundation/ for example. Most things done in Apache projects are funded and preformed by other organisations/companies that have the direct need and use cases for the projects - and that is not necessarily only a bad thing.
Just commenting from a CKM tooling perspective here and what you can do now (possible improvements e.g. to the Change Archetype Id process within CKM notwithstanding):
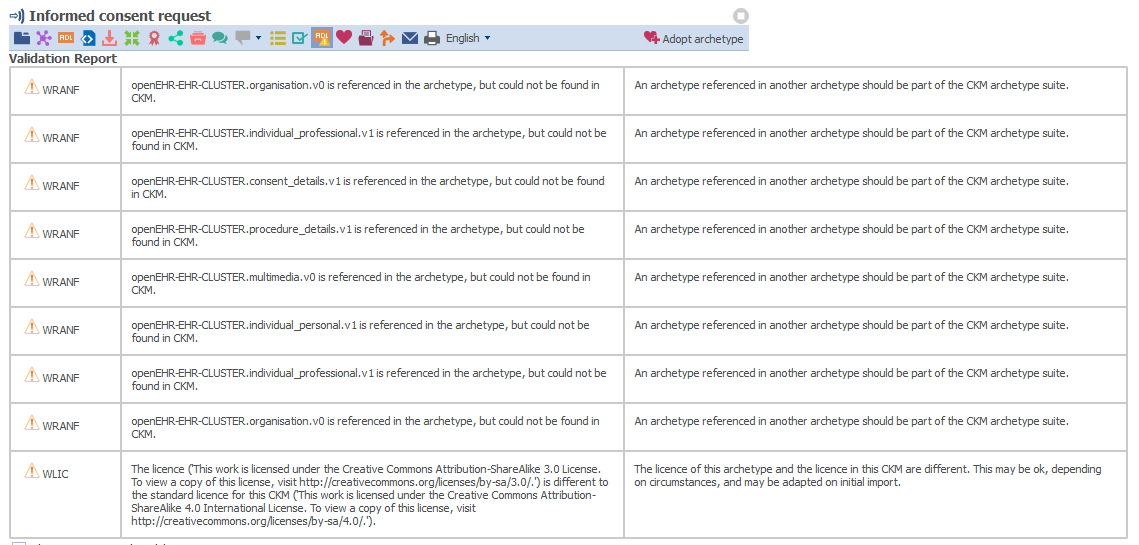
For the SLOTs, you can run a CKM Validation Report for all archetypes or just one and look for WRANF warnings, e.g.
These warning would also be displayed as part of the process for publishing the archetype with the SLOT referencing the (now) unknown archetype.
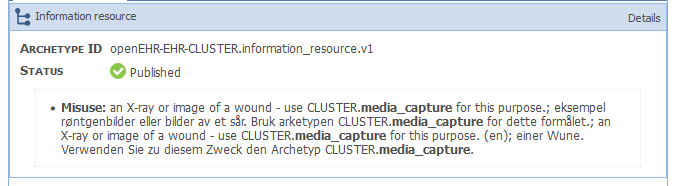
The free text is of course more difficult, but the comprehensive search would pick this up as well as - in your first screenshot, if you scroll to the bottom, the last entry identifies the text in the misuse field:
Ideally, the archetypes used in SLOTs are published first, then the archetypes using them.
The Editors update the names of new/edited archetypes and included versions every time they edit an archetype as a matter of process, in exactly the same way they fix a typo. If it has been missed inadvertently, it is just the same as missing a typo - unfortunate, but that’s life and one of the reasons why we have change requests. This is the way the Editorial process has worked for over 10 years and will continue to do so, whether you document it somewhere or not.
That said, the problem you have identified is a symptom of a much bigger problem with a growing number of out-of-date references in the archetypes that are not being worked on. The size of this problem will only be amplified as each new archetype is added unless there is a strategic change to the resourcing of CKM to ensure appropriate governance. There are 500+ archetypes that need to be coordinated and maintained and this involves many more tasks/activities than the one you have identified.
We have had this CKM for 12 years now and it is being used as an international resource supporting implementations by large vendors and national programs. It is a critical piece of infrastructure, and its’ influence spreads way beyond the openEHR sphere.
The modelling program has operated all this time on volunteer resources/funding for >95% of the effort, to date - effectively operating on a shoestring. We can’t keep running what is rapidly becoming a critical program as if it is a part-time community hobby - it needs to be properly resourced and managed.
Personally, I have contributed many hundreds of unpaid hours to this modelling effort, so to school me on how open source projects work is quite inappropriate. After 12 years I’m tired of trying to hold the Program together with not enough resources and minimal support, battling with the Board to be heard, much less valued as a leader.
If the openEHR community is serious about the modelling work, something needs to change or else the Clinical Modelling Program is at real risk of failing. It is simply not sustainable as it is, and we need to urgently make changes. As I’ve said many times before, openEHR’s greatest asset is also its’ greatest vulnerability. It doesn’t need more layers of governance, but to be adequately resourced to operate effectively to support the implementations.
The time for the ‘be patient, be adaptive, it is just a standard part of an open-source process’ message is long gone. Been there, done that. We urgently need allies with influence in the community to speak out and advocate for change - maybe someone just like you.
This is being actively worked on. The governance we have now is artefact-level governance, and it is world class. But a different kind of governance is needed, to address precisely the main problem: planning, resourcing and scaling.
The problem isn’t initially money/funding. It’s that there is no clear roadmap or sustainable project approach to scale into the future. External organisations with funding and/or available human resources don’t have a clear organisational structure to work with, as they would have with various organisations such as Apache, also (in our area) HL7, OMG, ONC etc.
With a new Program structure that enables project-based work with transparent management and resourcing, external organisations (including organisations in which some of the new Board members work) are much more likely to supply the needed human resource (and maybe even funding). But they need to have something to work with. This is how Apache is able to scale and undertake enormous amounts of work - they have a project- and roadmap-oriented governance structure with which such organisations engage. Corporations regularly assign their own workers full-time to such projects. This is what @erik.sundvall is referring to - it’s not about about the open source per se (although that is a pre-requisite), it’s about transparent, scalable project governance.
We can do the same thing in openEHR, but it requires that extra level of organisation and governance. With that in place, we will be able to finally maintain and scale the world-beating pioneering work you and a few others have done over past years.
I tried to initiate a discussion with the Board in January 2021 to start this journey - specifically planning, resourcing and scaling and potentially making the Clinical Modelling Program self-sustaining. The Board’s extraordinary response resulted in my resignation as Program Lead in August.
It is abundantly clear that the technophile Board does not understand the asset that it has in the Clinical Modelling Program - it is so much more than a library of governed artefacts and it is demeaning to belittle it as such. Project-based work with transparent management and resourcing, as you describe it, has been happening for years - the resourcing & the labour has been external but the governance central. The process could have been formalised ages ago but the Chair of the Board refused to hear what we do despite my multiple requests.
I’ve said this to you many times, imposing this theoretical new program ‘structure’ on what is left of the Program rather than enhancing and growing what is currently in place collaboratively, collegially and respectfully can only undermine it further.
I don’t know how many of the board would consider themselves technophiles - but we are in a highly technology-based domain - we are probably all partly technophiles. Might be worth considering the current board composition as well - there are many kinds of stakeholder there, including some major provider organisations.
I think they understand it reasonably well at a functional level, because they are mostly involved in organisations that are either already dependent or becoming so. Concretely, CKM is a governed library of world-class models. There’s nothing belittling in that - quite the reverse. There’s nothing else like it. That’s why there is such interest in making the kind of work done to achieve it sustainable and scalable.
it has in some form, but not in a transparent (i.e. publicly visible) or scalable way. Have a look at the projects view in Apache.org. You can drill into any project and find its definition, team, issue tracker. Here’s the issue tracker for the Cocoon project for example. Every Apache project has one.
If someone wants to get more people onto Cocoon (say) they go along to (typically) big companies they think might be interested and say, how about giving as 2 FTE to work on Cocoon? The company says, well maybe - what would they be doing? The Cocoon team points to the project definition, code-base, issue tracker (which is effectively the project management view), and say - well as you can see - we have 6 FTE of work for the next 2 years; if you give us 2, it will get x,y,z done, and we will also be asking Amazon, SAP, … you get the idea. And as often as not, the company says, well ok, we’re already using Cocoon, we might as well get a better handle on it - here’s two people for you, starting next month.
But if there’s nothing you can show that describes the backlog and planned work for the future, it’s virtually impossible to get this kind of resource in kind. All of this has to be outside CKM, which is regarded as a black box by user orgs.
It’s far from theoretical - it’s a well-proven methodology for making large open source projects long-term sustainable, and providing resource for them. We need to create something like that for openEHR.
Modelling is not the only kind of work we need to enable either - there are many other related activities, as you know better than most.
This is in no way to criticise the governance and work effort that has got us to here - it is recognised world class work. Everyone knows that. But it’s a modelling effort with artefact-centric governance (a bit like a single software project), and as we all know, it is not sustainable. The sector’s main concern right now is resourcing and sustainability.
I hope you will see the use of a proven approach for routinely creating and running clinical knowledge-related projects transparently, so as to attract human resource and funding, as a path to unlock the expertise you and others have developed to date and scaling it into the future. It will also allow us to bring new experience and ideas in, e.g. related to particular areas of interest for providers in the openEHR community.
Indeed we are listening, to a great many people. If you disagree with the entire approach of having a proper governed Program for clinical knowledge, what is the alternative proposal?
Addendum:
there is another, very basic reason we need to establish the Clinical Modelling Program within openEHR: because it doesn’t exist - the clinical modelling activity has no formal standing within openEHR. There is no organisational unit operating under any formal terms of reference that ‘owns’ the activity as there is with Specifications (the Specifications Editorial Committee) and more recently, Education (the Education Program Board).
That means any external or internal party that wants to connect to the clinical modelling activity only has specific individuals to talk to, nothing formal.
This has been tolerable in the past because the artefacts have been formally governed, but will not work going forward.
Establishing a formal organisational unit for Clinical modelling is thus a basic necessity.
I actually don’t expect unpaid work and did not intend to “school” anybody. I intended to say that organisations that use open source often channel resources in other ways than sending general “non-ear-marked” money to the coordinating organisation and expecting the organisation to hire somebody to do the work. (That would be more of the non-open source business model.) Instead they may pay a consultant (like you) or staff of their own, or a combination, to do work that contributes to the features they currently need - and if they are wise they also sponsor refactoring of some things that will help the new feature to be more sustainable. (I believe some Norwegian organisations are doing exactly this regarding some openEHR modeling.)
Example: Right now I would very much like to be able to buy consultancy hours from you and/or other archetyping experts to speed up archetype efforts for pathology reporting - due to local needs breast cancer and some other things would be prioritized. It would be easier to convince the people with budget here to sponsor a consultant like you to do that than to send a “general” monetary contribution to the foundation and hope it gets done. (Sadly, right now nobody at the hospital is allowed to hire any consultants, but those restrictions are temporary.)
There are similar problems with the example templates in the CKM, they are not always updated to using new major versions of included archetypes when the archetype update happens. Recently Archetype Designer has started detecting and error-reporting this upon loading of CKM-mirror from Github. I have placed four change requests to point out the failing templates:
In this case, this archetype was published and thus changing its archetype id to v1. The v0 revision currently used by the template is still available from CKM though. For example, by downloading the template file set of the template available from the same link above.
Just from a GitHub mirror it will be hard to work this out of course, but there is also functionality around this built into CKM’s REST API, such as
In any case, updating the templates to use the latest published v1 version of the archetype is naturally the best way to make this work smoothly across tools.