All,
I have been looking at the question of organising the _resources area more systematically for the openEHR copy of the EhrBase test framework.
Today it looks like this:
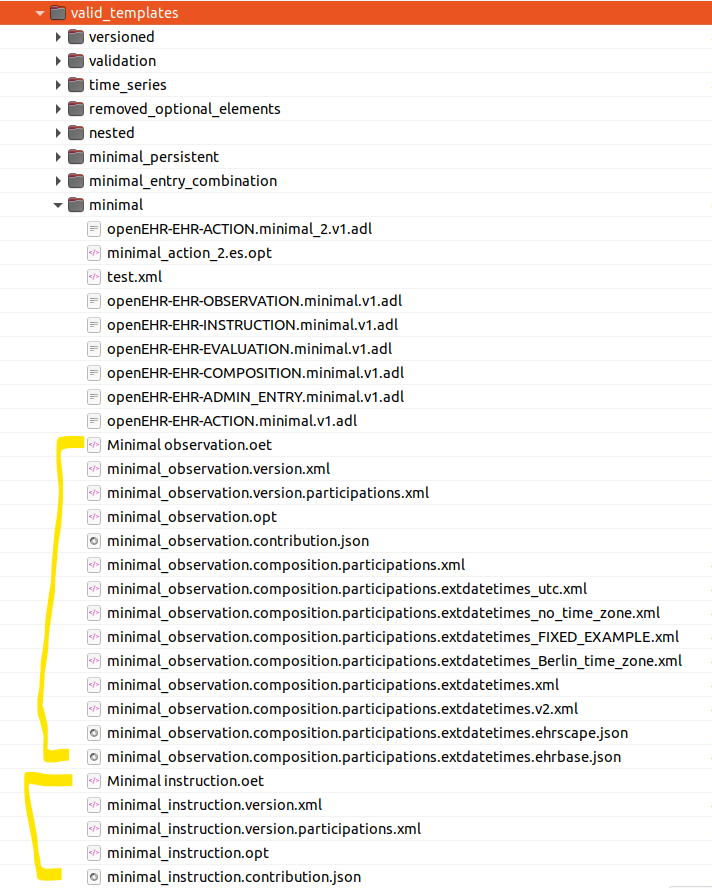
So all those files in the first group really belong under the template Minimal_observation. I thought about making a directory called that, and pushing all the files down into it. In some cases we might want to improve the name, but a name like Minimal_observation seems ok to me, unless we want more than one kind of ‘minimal observation’.
Anyway, elsewhere there are just data files whose name makes it obvious (we hope) which templates they are based on. E.g.
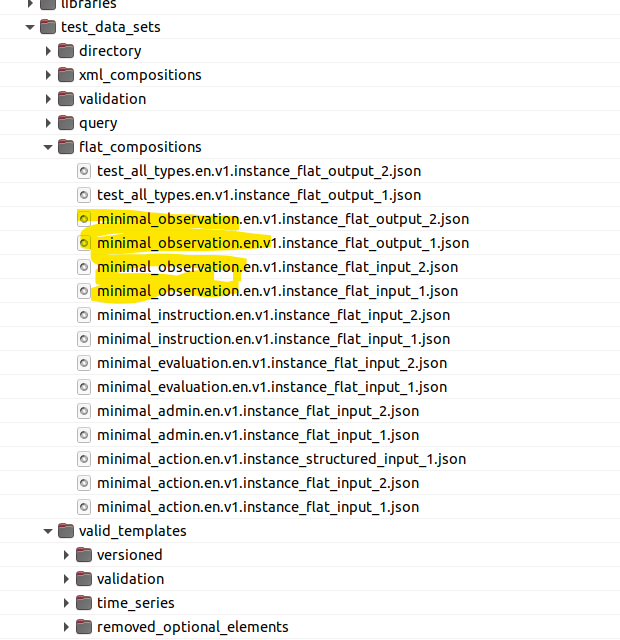
So good names for templates are important. One thing we could do here is to use ADL2 style names, i.e. openEHR-EHR-COMPOSITION.minimal_observation.v1 and similar - which makes it a bit clearer that the RM structure is in fact a COMPOSITION (nearly always) but the design intent is a ‘minimal composition’. This might be a step too far, and maybe current tools will choke on it.
I have asked @pablo if he has better ideas.
The big picture problem: we now have diverging code bases of the openEHR and EhrBase versions of the Test (robot) files. I have checked in Git and there are many small changes on the EhrBase _resources area from @wlad . @birger.haarbrandt - I think we need to consider the consequences of this more seriously!