I decided to have a look at the robot test case files, e.g. here. I discovered the directories have names like ‘B.1_CREATE_EHR’ and the files have names like ‘B.1__a)_New_EHR.robot’.
In the meta-data documentation I see:
*** Settings ***
Metadata Version 0.1.0
Metadata Authors *Wladislaw Wagner*, *Pablo Pazos*
Metadata Created 2019.03.10
Documentation B.1.a) Main flow: Create new EHR
Metadata TOP_TEST_SUITE EHR_SERVICE
i.e. the id ‘B.1.a)’ id appears again here.
The actual test cases have ids like MF-019 - Create new EHR (valid ehr_status with other_details).
Ids like B.1.a) come from this documentation, and are just a side-effect of the header structure of the document. If the document were to have a new section added between A.General Requirements and B.EHR Service Test cases, all those B.x.y would be come C.x.y.
I started migrating this documentation (after a discussion with Pablo) to the Conformance spec, to rebuild the main test schedule. Since this is driven from a hierarhcy of Service/call/testcase path (or maybe even Service/component/call/path as per Pablo’s schema), I have used ids like ‘TC-EHR-create_ehr-main’, ‘TC-EHR-create_ehr-alt1’ and so on. These could potentially be ‘TC-EHR-create_ehr-new_ehr’, ‘TC-EHR-create_ehr-same_ehr_twice’ (maybe dots are nicer - TC-EHR.create_ehr.same_ehr_twice, but you get the idea) if we want to be more descriptive, but either way, I think such ids are going to be more dependable, not to mention easier to understand.
The specification now looks something like this:

I would guess these kinds of ids (in whatever final form we could agree on) are going to be generally easier to work withm and also easier to process in scripts etc, than things like ‘B.1__a)’.
A second thing I realised is that the documentation is in both the .md files in the documentation directory, like this:

and also in the robot files:
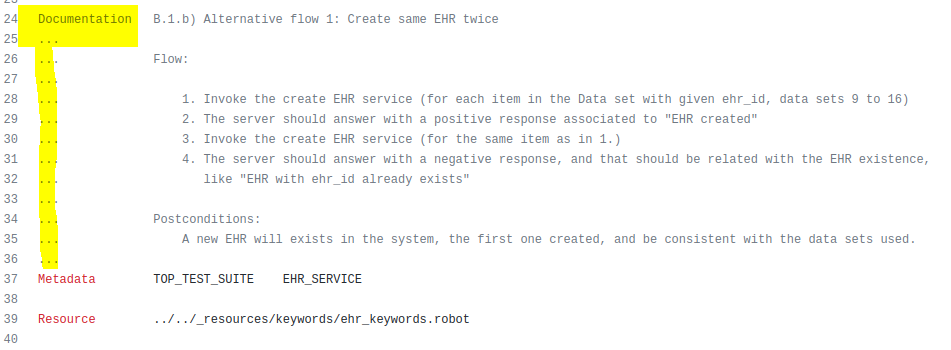
If changes are required to any of these test cases, we have two places to make the change. I would have expected that the Robot file would carry a URL or other ref to the documentation, or it could be the other way round - the description of the test is in the robot file and extracted somehow to produce documentation (indeed, the latter is doable with smart tagging in Asciidoctor).
Thoughts on these issues?
If we thought we might change such things, we should do so early, before any repo forking … (but not before the experiment Birger has proposed for the coming weeks).