TL;DR: Would adding a new element for the simplest presence checklists to the Screening questionnaire archetypes work?
The long explanation:
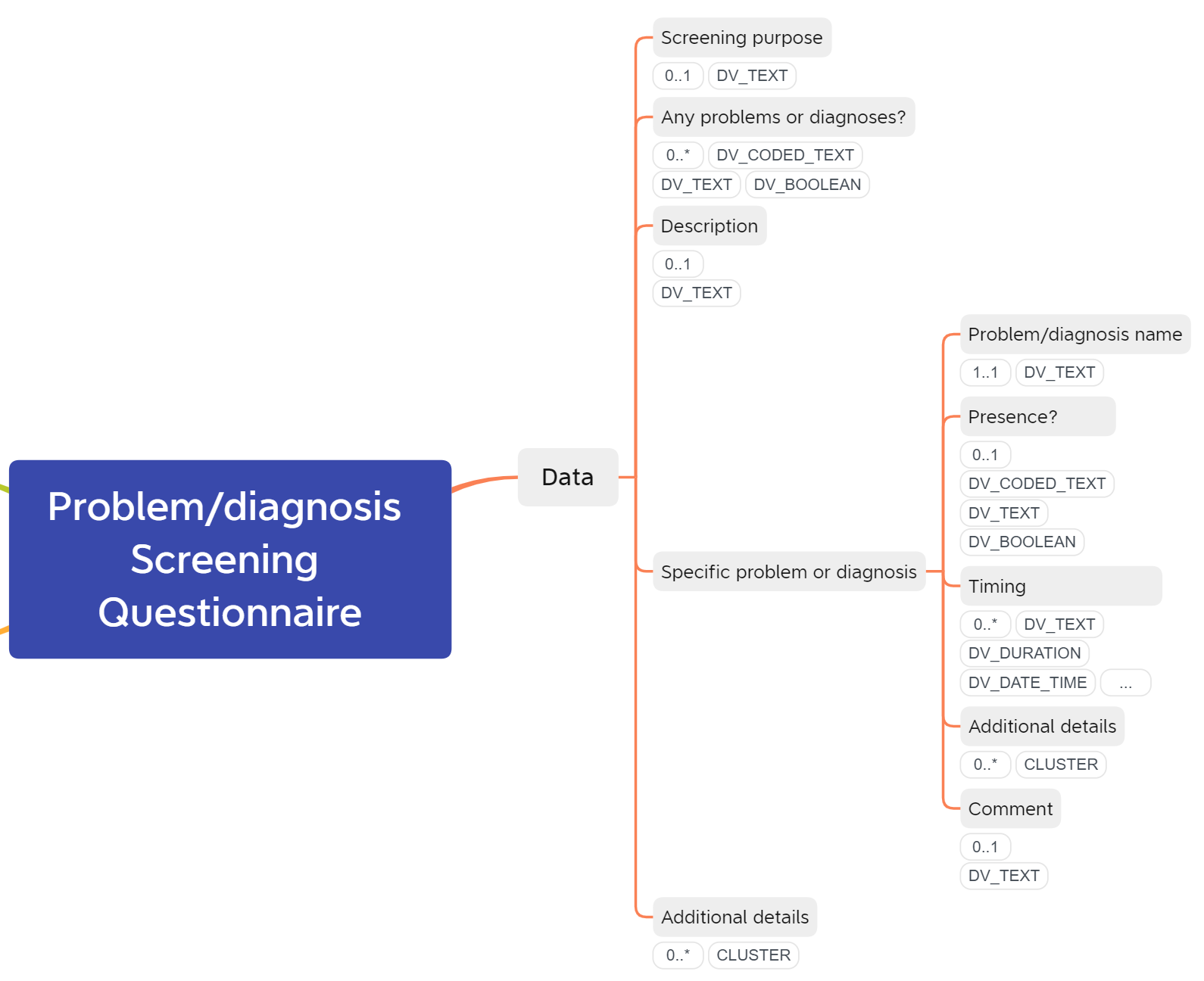
The “Screening questionnaire” family of archetypes, here exemplified by Problem/Diagnosis screening questionnaire, enables a template modeller to create a wide variety of questionnaires based on a fairly small base structure. It allows heaps of flexibility for expressing presence/non-presence statements, timing, and any additional information required for each questionnaire item.
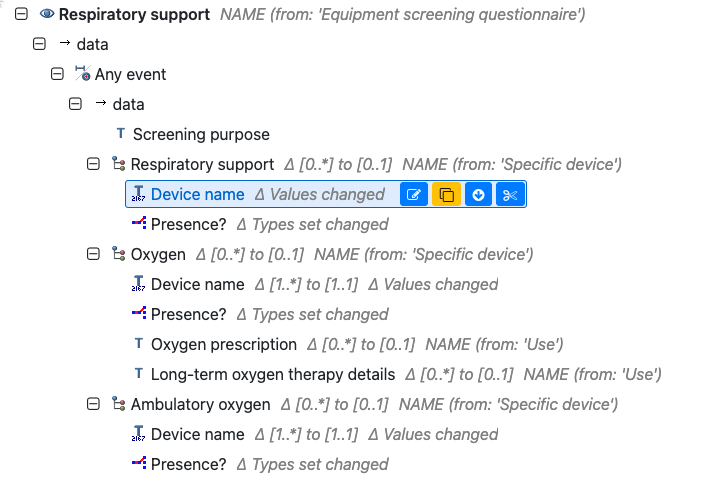
However, this flexibility comes with the price of increased clunkiness when using the archetype for its simplest use cases:
Simple checkbox lists of items, where a checked box implies “present”.
Here’s a pretty standard example, from a blood donation form:
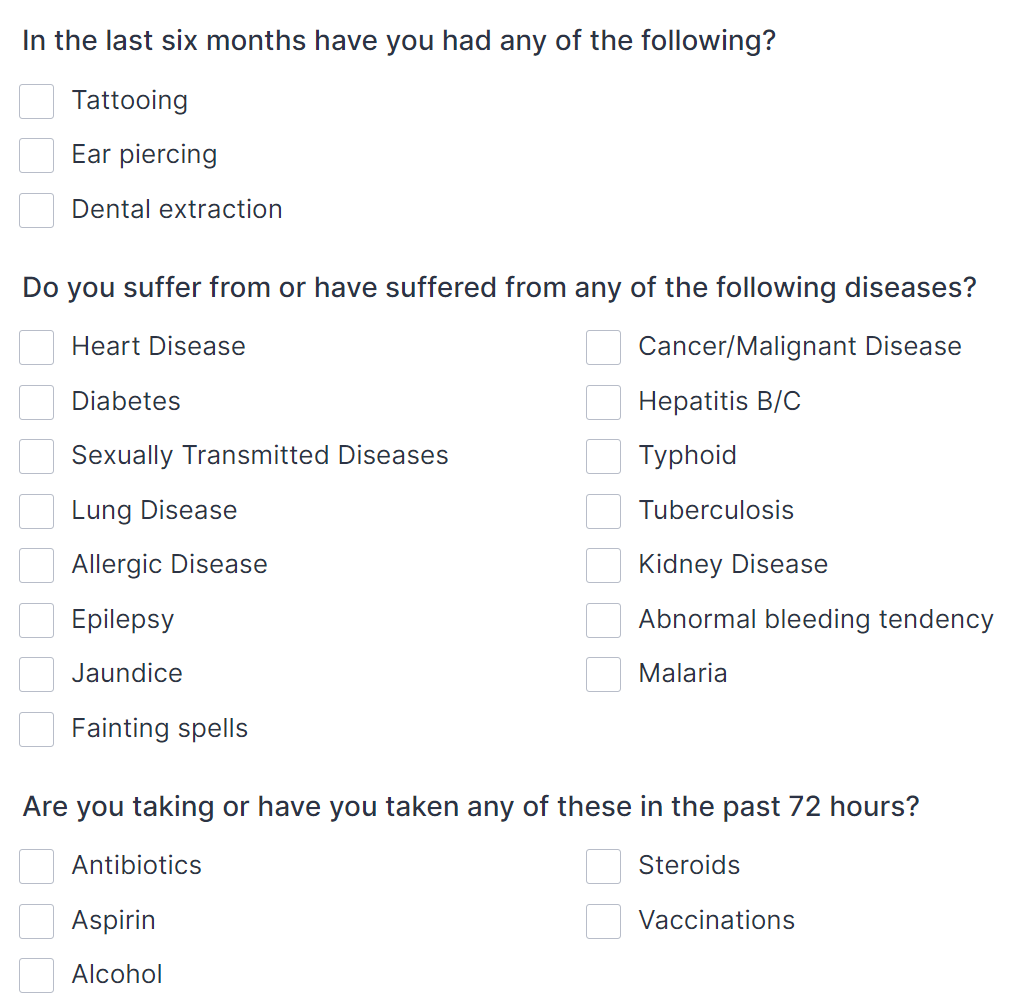
For each of the procedures, problems/diagnoses or medications listed, there’s no need for additional information, and each checked box implies that the checked item is present.
To create a template for this kind of form using the current Screening questionnaire archetypes, we have to instantiate the “Specific [concept]” internal cluster for each item in the checklist (for this example 23 times), and assign the “[concept] name” element within each of those instances with an item from the checklist. The “Presence?” element would also need to be constrained to “yes”, and set to be mandatory. Then there’d need to be extra UI work to make the elements of the repeating clusters appear as a consistent checklist.
To try and mitigate this clunkiness, I created a change request for the Problem/diagnosis screening questionnaire archetype, suggesting to change the occurrences of the “Problem/diagnosis name” element from 1…1 to 0…*. This proposed would enable a template modeller to create a checklist such as the “Do you suffer from or have suffered from any of the following diseases?” section in the image above by inserting the whole value set into the “Problem/diagnosis name” element of a single instance of the “Specific problem or diagnosis” cluster, and constraining the “Presence?” element of that instance to “Yes”. The change request was supported by @johnmeredith, and a similar change was recently proposed by @ian.mcnicoll in the ongoing review of the Family history screening questionnaire archetype.
During editorial discussions there have been some concerns that this proposed change will make the data contained within the “Specific [concept]” cluster unpredictable, and would make the semantics of the “Timing” element and “Additional details” SLOT unclear. On this basis we’re suggesting the alternative of adding a new root level element to the screening archetypes, for the simplest presence checklists only. We’re envisioning something like this (element name and description totally up for discussion):

This solves the requirements of the Norwegian team without potentially blurring the semantics of the current “Specific problem or diagnosis” cluster, but we’d like to get input about whether it solves the requirements of the other parties who’ve been involved in these discussions as well. If the addition of this element breaks anything else, we’d really like to know that too ![]()