Hi Silje,
See this post Revisiting symptom/sign - #15 by ian.mcnicoll for some examples.
Hi Silje,
See this post Revisiting symptom/sign - #15 by ian.mcnicoll for some examples.
Okay, reading the British Pain Society document, I can find the numerical representation of VAS (p 9), where the distance between the “no pain” end of the line and the patient’s mark is measured in mm, leading to a total of 100 mm. Do we have any others?
I see 0-20 referenced a lot regarding NRS (although not in this document), but I haven’t found any actual examples of use.
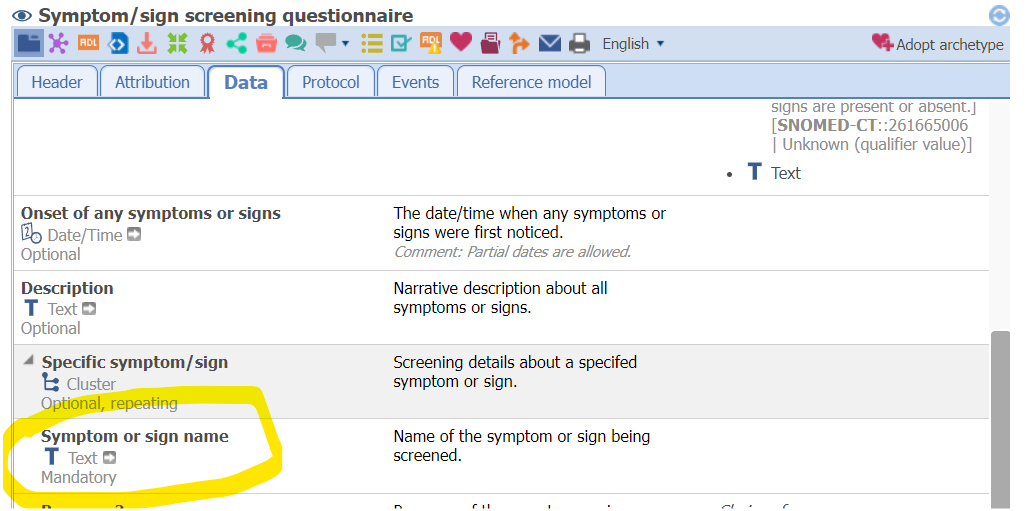
Regarding the combined use of Symptom/sign and Symptom/sign screening questionnaire could it be a good idea to encourage reusing exactly the same content (use the same text or coded text) in the symptom name fields when the two archetypes are used together? (See images below.)
If so an AQL query for any of those fields in an EHR would give a hit. In a GUI/form the good thing to do would then be to hide one of the fields from the user and automatically “under the hood” fill it with a copy of the content from the other.
Perhaps such advice is best placed as a comment in the Symptom/sign screening questionnaire archetype (by the “Symptom or sign name” field).
and
Definitely. Could you add change requests about this?
That’s cunning!! Yup it would work for the Zibs example. TBH I’m not all that bothered about proportion for now - if someone does come up with a 0 … 95.6 range then it can be added later!!
The trouble is if someone tries to use the 0…100 mm Quantity, which is intended for a 100 mm visual analog scale, for a 0…20 numerical rating scale. I’ve read about the 0…20 NRS in several places, but I haven’t seen an actual use case presented.
The element description reads “numeric rating scale”.
The zib has 3 potential valuesets for the equivalent element
0-10 (integers I assume) NRS
0-10 (cm I assume) VAS
0-100 (mm I assume) VAS
So the concepts don’t match currently. I’m also unsure about the effect of having 0-10 without units and 0-100 with mm units. What are your thoughts here?
I’m leaning towards making the element unconstrained. And make specialised archetypes/templates for pain score.
That would indeed break computability across observations. But I think the concept of symptom severity is currently too broad to allow for that anyways. But maybe I’m missing the usefulness of that computability?
My idea was to allow the 0-10 without units for “normal” NRS recording, but on second thought I guess that would be better as a DV_COUNT. I’d be happy to make it a choice of
I’m still not clear we have an actual use case for Proportion, or is it only theoretical? If theoretical, it could be added when a concrete use case is identified. It feels quite uncomfortable in principle.
Can DV_COUNT be left with max unconstrained?
To my knowledge it’s theoretical. I’m happy to leave it out for now.
Sure, but why?
We have a definite use case for an integer-based score, without units, usually 0…10. Leaving it unconstrained would enable anyone to make any integer score and while we know that many are 0…10, a lot of this thread is about there possibly being other scores that will exceed 10. If we leave it open, even open at both min and max, then we support maximal reuse, even (as yet imaginary) scores of -10 to +10. At the moment we have it modelled for the majority use case that we know about, which is 0…10 and is what you possibly should expect in a template.
Agreed.
My thinking was that this would be covered by the DV_PROPORTION data type. Otherwise, you’ll never know what what you find in the DV_COUNT means. What does this ‘9’ which is recorded represent? 9/10? 9/20? 9/100?
You can have more than one DV_COUNT alternative; showing what the range was would rely on tools at runtime displaying the archetype interval (i.e. the 0…10 or whatever) on the form, or using it somehow to visualise a form control. If data are being committed via forms not driven by the archetype (i.e. the OPT) then there can be problems. Clearly, it must be the case that the data enterer knows that ‘2’ is in a range of ‘10’ or ‘100’, since it is valid in both.
Not in ADL1.4 AFAIK
They are alternatives - see here in spec.
This doesn’t work for DV_COUNT in tools, only for DV_QUANTITY…
Edit: It doesn’t work for DV_QUANTITY either. Adding units work, but it ends up as a single DV_QUANTITY with a set of units, not a single AT code with a set of DV_QUANTITYs.
Thank you Heather (belatedly) I had misunderstood.
So the proposal for a 10-point, single-digit scale looks good. Is that intended to replace, or would it co-exist with the 5-point text scale suggested previously to align with 5 x SCT codes, with the intermediate values intended to be interpolated?
If so, I’d suggest that “interpolation” is troublesome for ordinal values, and we should craft text statements for the intermediate ranks too.
I think there is a problem with ordinal ranks being marked by number, as if integers: they are not rational numbers so arithmetic is not valid. For instance, a rank of 2 is not half as bad as a rank of 4, nor is 3 halfway between them.
We “know” this, but the use of numbers traps people into thinking like this.
Textbooks state that ordinal numbers always need statistical processing, not arithmetic.
The Statistical Evaluation of Medical Tests for Classification and Predicti…
I have researched this cognitive risk e.g. see The ABC of cardinal and ordinal number representations: Trends in Cognitive Sciences (cell.com)
and real-world misuse of ordinal numbers e.g. at Use of the Palliative Performance Scale (PPS) … .
I suggest that other serial symbols such as alphabetic should be used: if the above 3 ranks were denoted as a/b/c there would be no quantitative inference of meaning from the different symbols.
However this does not seem compatible with the discussion at Clinical scales - ordinal or coded text? - Clinical - openEHR . Sorry to say further confused by Text, descriptions and comments for value set items - mandatory or optional? - Clinical - openEHR
Is it that this is not our problem, but that of all those clinical scale authors that have (mis)used numbers as ordinals, which openEHR can only seek to represent. Or should openEHR at least alert developers that ordinal numbers are trouble?
As a beginner in openEHR please excuse if this is off-point , but would be grateful for your advice and corrections
Hi Colin,
This is a tricky space indeed. There is no absolutely right answer. In reality, we are all bumbling along as best we can in the circumstances, and trying to model these concepts faithful to the original, often well-validated, scores & scales, but most of all ensuring that each archetype is as clinically safe for implementation as possible. All contributions are welcome, especially ideas that come from a slightly different direction to provide checks and balances to our assumptions.
The notion of a generic representation of severity scale (outside of the formal Score/Scale territory) is tricky. My advice when modelling severity and using a SNOMED as a drop-down list (not an ordinal for reasons that you outline quite rightly) is to keep it to 3 values - mild/moderate/severe. Back in the day, I saw lists that included trivial/mild/mild-to-moderate/moderate/moderate-to-severe/severe/very severe/fatal. Yes, a fatal symptom! And with a list like that, it is absolutely not possible to get any inter-rater consistency because everyone’s definitions of/criteria for each term will be different. My severe could well be someone else’s mild-to-moderate. So with the KISS principle in mind, we usually strip down this kind of subjective severity assessment towards the 3 values, hoping that clinicians can reasonably differentiate between them - unless there is good reason and explicit definitions to justify otherwise.
In the past, we have dabbled in interpolation for some models but it felt quite unsafe, and now avoid it as a CKM modelling approach nowadays, again for the reasons that you outline.
You may well be right that the authors are designing scores without a correct understanding of how they should be used in statistics. I’m certainly no expert on that and you’ve clearly explored this area more than I. However, it is a CKM Editor responsibility to represent the Score/Scale faithfully, according to copyright etc. If an existing, validated, frequently used score or scale represents values with a score, which are often used as part of a calculation for a total score or for graphing trends etc, it will often be modelled as a DV_ORDINAL BUT if it is not clinically safe to use (which is why clinical informaticians should be modelling archetypes) then I’d advise a different data type be used, usually DV_CODED_TEXT to supply the list of options alone. Ordering a value set, without numeric ranking - hmmm, not sure we’ve seen a use case yet.
So we do try to model ordinals where ordinals are appropriate - otherwise, we run the risk of inappropriate implementation. Is there a use case/archetype you think we have modelled incorrectly or inappropriately?
This thread is a natural follow on to content but not aligned with the topic. Perhaps we should look at creating another thread for the purpose if this conversation continues.
I don’t see incompatibility with the other threads that you mention, but curious to understand more of what you are thinking. Perhaps we should continue discussions in each of those respective threads if you are seeking further clarity?
Cheers
Heather
ok so this means the tools don’t implement that part of the spec.
the reason they are numbers isn’t based on the assumption that their values accurately reflect comparable magnitudes of real things (or maybe natural log or other transform…) but just to treat them as being ‘ordered’, which is the whole point of using ordinal scales - they are a ranking mechanism for a cohort, which is then usually sliced up into a few groups for the purpose of triage. That slicing up is almost always done on the basis of the ‘>’ operator, i.e. numeric comparison. So Apgar >=8 = baby is fine, 7 = observe for a while, <=6 = send to PICU.
I’m not sure how this would work - Apgar numbers 0-2 and 0-10 for the total were not invented by us, they are international definitions. Same for ?all scales I have ever seen, e.g. Barthel, Waterlow etc.
I think it is better to educate people that ordinal = ‘ordered’, and is not quantitative - which is why we have another type for this. The reference models illustrates this pretty well in fact.
If clinical modellers and developers alike understand that, I think there will be no problems. Agree with all your other comments about ordinals only being statistically analysable etc.