Better accepts the archetype_details in the POST but does not return them in the GET - I appreciate this is a little academic right now but it might bite us later.
Better accepts PERSON as the external_ref.type but overwrites that to ‘PARTY_REF’ which I think is incorrect.
THe rule is
Type_validity: type.is_equal(“PERSON”) or type.is_equal(“ORGANISATION”) or type.is_equal(“GROUP”) or type.is_equal(“AGENT”)or type.is_equal(“ROLE”) or type.is_equal(“PARTY”) or type.is_equal(“ACTOR”)
const ehrStatus = {
_type: "EHR_STATUS",
archetype_node_id: "openEHR-EHR-EHR_STATUS.generic.v1",
name: {
_type: "DV_TEXT",
value: "ehr status"
},
subject: {
external_ref: {
id: {
_type: "HIER_OBJECT_ID",
value: '{{subjectId}}',
},
namespace: '{{subjectNamespace}}',
type: "PERSON" // This is overwiritten to 'PARTY_REF' in BetterCDR
}
},
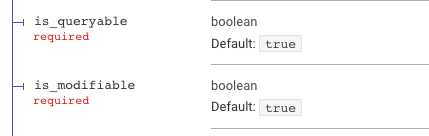
// If not specified these default to false in EhrBase and true in BetterCDR
is_modifiable: true,
is_queryable: true
}
Having said all that, the variance is impressively small and hopefully easily corrected.
Where EHR_STATIUS is not defined on a createEHR, the spec says.
An EHR_STATUS resource needs to be always created and committed in the new EHR. This resource MAY be also supplied by the client as the request body. If not supplied, a default EHR_STATUS will be used by the service with following attributes:
and finally Better overwrites subject/external_ref/type e.g PERSON with PARTY_REF, which is not valid according to the RM - @matijap - would changing this present a problem?
and @matijap - I think Better should return the EHR_STATUS archetype details and name for any GET calls , though I appreciate these may be a ‘virtual’ entity internally.
That is what I mentioned that should be required in the JSON schema, if the systems let that pass, they might not be using the json schema for validating the payload. But let me check because that is from memory too.
Yes, both are required and should be “boolean”. So I think neither CDR is actually using the official JSON schemas to validate payloads. Not sure what happens if you remove any of the other required fields too.
Ideally this would be one day done with a check using the BMM schema for the demographic model, via a test like Type_validity: Demographic_model.type_conforms_to (“PARTY”).
And is there an argument for handling other required values in EHR_STATUS similarly.
i.e. defaults for archetype_nodeID and name plus defaulting subject to PARTY_SELF. since this is what happens if ehr_status is not explicitly provided at all?
The archetype details re all ‘virtual’ in any case - there is note actual archetype or validation. It might be sensible to keep it that way, so that if actual archetypes come along they cannot use the same Id.
I would say the JSON schema is what the server skills consider as valid at the endpoint level. Modifying the received JSON at the endpoint level and then validating it is strange, though technically possible. The problem is that will generate a different behavior is different implementations. Atomik CDR for instance will validate the JSON add it is without modifying it, so your JSON will be rejected, telling you both attributes are mandatory but not present.
Another thing to consider is we need API JSON schemas, which are more relaxed than RM JSON schemas, and those attributes could be made optional there. In fact I have contributed such schemas some time ago when I found errors in the published openEHR JSON schemas which were only based on the RM, so there were no API schemas. Those are in my openEHR-OPT repo in GitHub and I think also in a PR to the openEHR JSON schemas on GitHub.
I’m not sure if this is a good moment to tell/remind that we actually have started an OpenAPI schema already in the REST API specs 1.0.3 specs, partially to address the RM simplification/deviation in the case of REST handling.
@sebastian.iancu In another thread I think we reached the conclusion both kinds of schemas are needed, the OpenAPI ones for ode generation, and the standalone JSON Schemas just for data validation, similar to the RM-based JSON Schemas. Since I don’t need to generate code, I use only standalone schemas.
A diff between the api and the rm schema will reveal all the flexibility points added to the API flavor schema.
On the other hand, @pieterbos was considering my changes to fix the generator on Archie, because the RM schemas were generated from the BMMs, though I don’t think there are relaxed BMMs for the API flavor which could be use to generate those schemas to. @thomas.beale might now about that.
Then if we have the API exchange models represented as BMMs and a generator working on Archie, we could be able to generate the OpenAPI schemas too instead of building them by hand. Would that be possible?