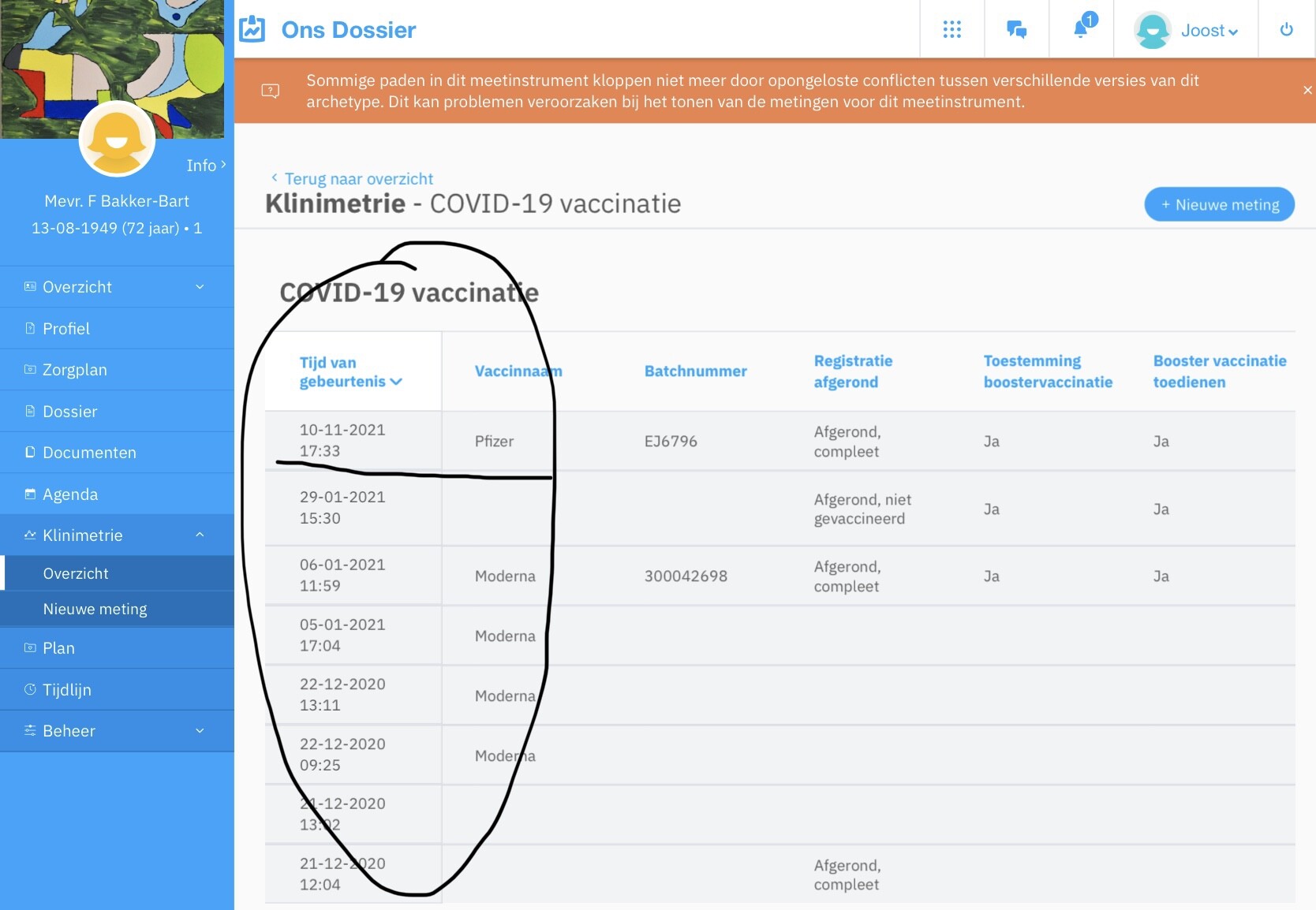
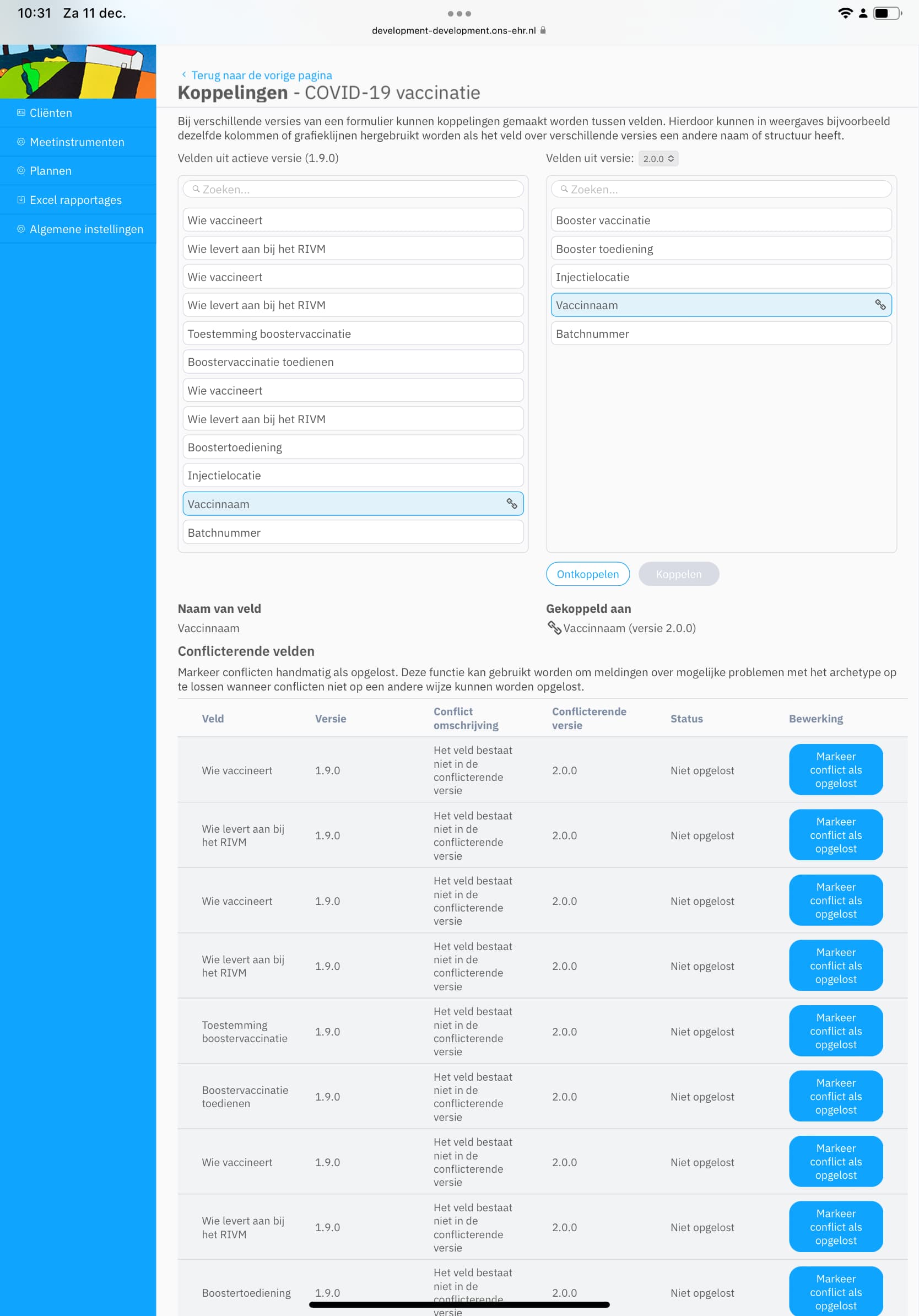
Already published archetypes sometimes need to be republished, to incorporate a change. We have clear rules for how different levels of changes affect the versioning of the archetype:
- A patch change such as correcting a typo or adding a translation, leads to a 0.0.1 increase in version numbering.
- A minor change, such as the addition of a data element or changing the text of an element without significantly changing its semantics, leads to a 0.1.0 increase in version numbering.
- A major or breaking change, such as removing a data element, significantly changing the semantics of a data element, or moving a data element to a different part of the archetype tree, leads to a 1.0.0 increase in version numbering.
What we’re missing is a similar set of rules for the process of committing changes, especially the major changes.
- Patch changes can be applied and republished at any time, and for translations only this is often performed by translation editors.
- Minor changes are usually also applied and republished without any ceremony, but it may be prudent to consider any outstanding change requests or discussions.
- Major changes are more difficult. What are the requirements for republishing an archetype with a new major version, e.g. going from v1 to v2? In the past this has been done by consensus among clinical knowledge administrators (CKAs), but it’s always been uncomfortable and it would be a good idea to have clearer guidance which is anchored in the community.
So just to throw some ideas out there, these are some alternatives for the process of republishing an archetype as a new major version.
- The editor makes sure to clear all pending change requests before republishing, but otherwise no significant process.
- The editor polls the community about any additional change requests or considerations.
- There’s a discussion and decision among editors about each archetype which is a candidate for a major version republication.
- There’s a formal CKM community review before an archetype can be republished as a new major version.
These ideas each have their own pros and cons, ranging from lack of oversight for #1, to extensive overhead and the risk of reopening cans of worms for #4.
There may also be an argument for creating a special status for some archetypes which have been extensively explored and tested in multiple implementations, including adjacent use cases. These would be the archetypes where #4 was a necessary requirement before republication as a new major version.
I’d like for members of the community to respond with their thoughts on the matter.
 , but we all know that’s not going to happen. We promote the archetypes to be “future-proof”, but at the same time we realise that there will be a need to change them due to errors, new requirements or new medical knowledge or changes in the pattern established in archetypes.
, but we all know that’s not going to happen. We promote the archetypes to be “future-proof”, but at the same time we realise that there will be a need to change them due to errors, new requirements or new medical knowledge or changes in the pattern established in archetypes.