We have recently been looking into the requirements around PEWS based on requirements in Sweden.
I am by no means an expert on the topic, but PEWS seems to be interpreted differently based on country and other contexts. There does not seem to be any consensus on how to calculate a PEWS score. There is no PEWS archetype in the international ckm either.
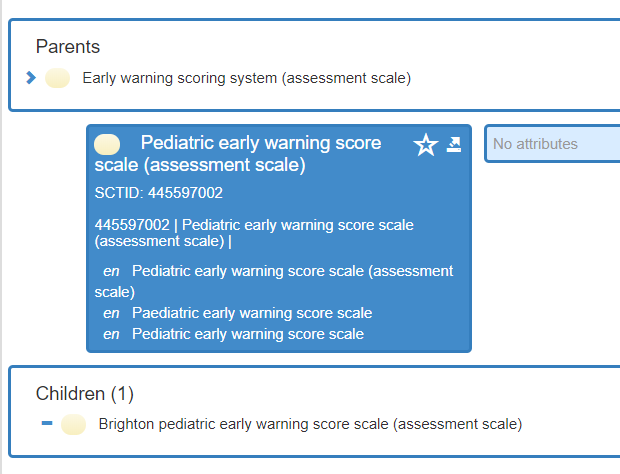
I hade a brief discussion with @siljelb who mentioned the Norwegian PEWS archetype (https://arketyper.no/ckm/#showarchetype_1078.36.1402). Turns out, in Norway PEWS is always calculated in the same way, whereas in Sweden, the calculation is done differently based on patient age.
My initial thought was that this means that we cannot share the Norwegian PEWS archetype. Especially as it has explicitly modelled scoring rule for calculation in the archetype, e.g. what respiration interval corresponds to what score.
Then I started to think about the impact of modelling the actual scoring rule into the archetype like this for us in Sweden. Should we then have 5 or so different PEWS archetypes, one for each age interval for the patient? This does not sound reasonable?
Instead, wouldnt it be better to not include this type of rule inside the archetype? That means that we can create one common international PEWS (assuming that we can agree on the different type of Observations that could be included in the rule, or agree to include the maximum set). A PEWS is a PEWS. Then you would have some other attribute (as part of the Protocol?) where you define what rule (a GDL rule?) that the score was based on.
I can of course see a hardcore informatics view on this, a PEWS calculated based on one formula is not exactly the same as a PEWS calculated by some other formula, hence they need to be modelled as different archetypes. But what benefit does this really give? It wont make life easy for implementers or enable interoperability. Cant we see PEWS as a score for assessing the clincial status of pediatric patients, regardless of the method of getting to the score?
There are other concepts like this, we are currently looking into the RETTS triage method which is common in Sweden. It also has age intervals impacting the method of determining the RETTS triage level. But having discussed that use case, the RETTS scores is seen as the same, regardless of how they have been calculated. Meaning, we should probably not model different RETTS archetypes per age interval, and we should probably not model the rule inside the RETTS archetype.
Question
Isnt it a more sustainable pattern for modelling scores and similar concepts to not include the actual formula, rule, protocol etc that gives you the score inside the archetype, and instead include some type of metadata for this in the protocol or similar.