Since a recent discussion about date/time types the idea of summarizing several improvements to the openEHR RM proposed and discussed from time to time into a list we can review and discuss over something concrete, I did a quick review of the specs to bring this discussion over the table, mainly checking the UML diagrams and remembering some issues I had when implementing the specs in the EHRServer and the openEHR Toolkit. This is just an exercise for the future, not something we need to do for tomorrow.
Note some of these are breaking changes! That is why this is RM v2.0.
Have some kind of system-wide CONTRIBUTION+AUDIT_DETAILS for EHR operations like create EHR, delete EHR (even the physical delete use case required by some countries), etc. Currently CONTRIBUTIONs are just for in-EHR and VERSIONED data.
Support lifecycle state (incomplete, complete, deleted) for EHRs: allow to create ‘incomplete’ EHRs, for instance without the minimal required information. Currently only versioned data has lifecycle state.
Define an architectural component for a terminology service (TS), including the REST API and exchange format schemas (ITS). There is currently an initial spec for this in the support package that seems to be just for the openEHR terminology (?). It would be nice to generalize this package to access any terminology on an openEHR TS (SNOMED CT, LOINC, ICD X).
composition.EVENT_CONTEXT should be LOCATABLE. It is PATHABLE but I think we might need the node_id in the archetype, for instance to define alternatives.
Remove ENTRY.workflow_id if it’s not used on any implementations.
ACTION.ism_transition should be optional. Just recording an ACTION without any state or transition information should be allowed.
ACTIVITY.timing: DV_PARSABLE should be fully specified.
Timing of the activity, in the form of a parsable string. If used, the preferred syntax is ISO8601 ‘R’ format, but other formats may be used including HL7 GTS.
May be omitted if:
timing is represented structurally in the description attribute (e.g. via archetyped elements), or
unavailable, e.g. imported legacy data; in such cases, the INSTRUCTION.narrative should carry text that indicates the timing of its activities.
a. The ‘R’ format mentioned is formally the ‘recurring time interval’ expression in ISO8601.
b. We could restrict all the possible formats to just couple and add examples of each in the specs, making life of implementers a little easier.
INSTRUCTION_DETAILS.activity_id should be defined in a way it always identifies a single ACTIVITY within an INSTRUCTION: see updated issue description [SPECPR-221] - openEHR JIRA
a. all ITEM_STRUCTURE concrete types are a special case of TREE.
b. the ITEM hierarchy is enough to represent a TREE
c. ITEM could take the place of ITEM_STRUCTURE in the RM
d. if needed we could have some field that could state which kind of structure is represented at runtime
e. either way most archetypes use ITEM_TREE
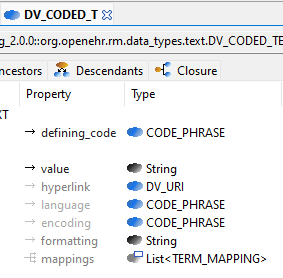
DV_IDENTIFIER.type could be a DV_TEXT instead of String, allowing this field to be free or coded text via DV_CODED_TEXT. Since the ID type sometimes need to be controlled by a coding system.
Remove DV_STATE, doesn’t seem to be used, it’s a leftover from some previous design of the RM.
Remove DV_PARAGRAPH, doesn’t seem to be used.
TERM_MAPPING might be defined inside, or linked to, our terminology server (see 3.)
DV_PROPORTION: separate the concepts of percentage, ratio and fraction in different data value classes. This simplifies implementation in terms that the meaning of the numerator and denominator don’t depend on the PROPORTION_KIND code, also removes the need of PROPORTION_KIND. It’s just cleaner.
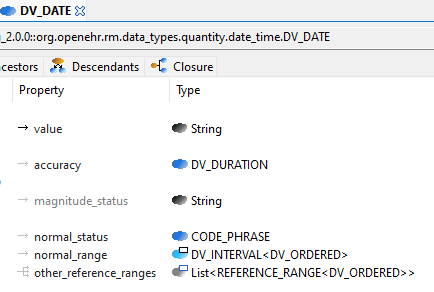
Remove double inheritance from date/time/duration classes, and make the internal representation independent from ISO8601. After studying our specs and the ISO specs, it seems we mixed what is representation for data exchange and representation for data management. ISO 8601 is for data exchange, and it’s limited for manipulation, management, and computation.
Define semantics and detailed operations for date/time/duration classes (after making the change in 15.)
DV_PARSABLE.formalism: String could be DV_TEXT to allow free or coded text via DV_CODED_TEXT when archetyped of at runtime.
Complete the ehr_extract spec, it has a lot of TO BE SPECIFIED/DEFINED comments.
ehr_extract diagram 1 shows “version container”, is that a VERSIONED_OBJECT instance? After that in the spec, that “container” doesn’t seem to be defined.
Define how to query over LINKs in AQL.
Define how to query over INSTRUCTION/ACTIVITY+ACTION to know the current state or the history of states of an ACTIVITY. (depends on 8.)
We could do this, but it starts to create junk data in the EHR, which is a major source of grief in today’s systems. An Action with no state means that queries looking for say active or suspended orders don’t know what to return for such actions.
A better way to deal with it is to allow an ‘unknown’ state, or else the the state ‘unknown’ in the null-flavours sense (i.e. no data on state available). Then the query engine needs a mode to return only positive hits and also positive + unknown (= possible hits).
Just a note on when to use DV_XXX types - they should only be in places like ELEMENT.value, to allow polymorphic attachment. For attributes of known types, the more basic underlying primitive type can usually be used, e.g. Terminology_code, String, the Iso8601_xxx types etc. We made a few mistakes in the original RM, so this was not always followed, but it is in Task Planning.
Probably true I think.
I did originally have exactly that separation, but it wasn’t popular… here’s the way the model looked back in 2017
I will create one page for each topic so we can discuss in detail.
Not sure if that is junk data, because there could be cases for recording actions when there is no previous instruction, for instance in emergency care, ambulance/paramedic services.
So in the case the ACTIVITY is linked to an ACTION archetype_id and an ACTION has INSTRUCTION_DETAILS, the ISM_TRANSITION would be required, but it that is not the case, the mandatory ISM_TRANSITION could still generate junk data, since the mandatory ISM_TRANSITION might not be needed.
On the other hand, it’s strange that INSTRUCTION_DETAILS is optional and ISM_TRANSITION is mandatory in an ACTION, which is strange to have a current_state without having the reference to the INSTRUCTION/ACTIVITY from INSTRUCTION_DETAILS.
Not sure why is that self-imposed constraint. DV_TEXT is like any other type. If a DV_XXX complies with the requirements of data elsewhere in the RM, why using something else?
The main point is: DV_IDENTIFIER.type could be codified, and if that is the case, we need a place to store the terminology_id. The same happens with any other String attribute in the RM that could be a coded value. Architecturally it’s better to define a type for those fields instead of inventing some patch solution like encoding code+terminology_id in the String field. Also using String and requiring to store a code would require implementers to create their own custom subclass of String, like a CodedString. IMO that is a bad solution but is arguable.
@thomas.beale on a second thought, what you mention about using DV_XXX just at the ELEMENT level is not what we have right now, you can see DV_DATE, DV_DATE_TIME, CODE_PHRASE, DV_PARSABLE, DV_TEXT and DV_CODED_TEXT everywhere in the RM from EHR to ELEMENT, so I’m not sure if that argument could be sustained for not using DV_TEXT/DV_CODED_TEXT elsewhere to formalize some fields that could be coded or could be just plain strings.
Even in LOCATABLE there is a name: DV_TEXT field, so most classes in the RM actually have a DV_TEXT field because they inherit from LOCATABLE.
At the DV level we also have DVs using other DVs as types for their internal fields:
Yes they are used in places with fixed types, but that was an error. Simpler types could be used, particularly Terminology_code and the Iso8601_date / time types. This is what we have done in Task Planning.
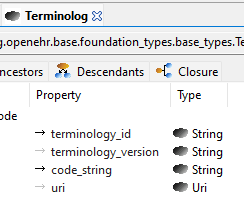
Compare a DV_CODED_TEXT to Terminology_code:
And similarly DV_DATE to Iso8601_date:
The DV_ types could of course be more efficient, and an openEHRv2 approach might be something like what I proposed for FHIR, except translated into openEHR types.
Thanks @thomas.beale though architecturally I don’t understand why one approach is better than the other. What you mention “feels” (needs an in deep review) there is a need of having each of those types kind of duplicated as DV_XXX and as foundation types. I don’t see a clear advantage of that approach.
I understand the foundation types could be simpler since the inheritance hierarchies are flatter and there are few attributes, but there is an overlapping between the DV_XXX and the foundation type that serves the same purpose. Then, why not using the foundation type inside the DV_XXX type to reduce the overlapping-duplication of fields and increase reusing those fields.
In your example, I would prefer something like DV_CODED_TEXT.coding: Terminology_code and remove DV_CODED_TEXT.(hyperlink, defining_code)
Similarly to the date/time/duration types, though there are other issues with that model, like mentioned form the ISO 8601 review, the RM representation could be independent from the exchange format, which is the purpose of the ISO standard (see point 15. on my initial message), so this might require a deeper refactoring.
In conclusion, I get what you say, and besides using foundation types for all RM attributes, as said I would also refactor the dava_types model trying to reuse the foundation in the DVs too. Anyway, all this would certainly break the RM so it’s good to discuss for RM v2.
I’ll answer properly later on, but here is a demonstration of what happens when there is no parent ‘Data value’ type of some kind - you get this, common in FHIR.
But I’m not proposing removing the parent or avoiding any hierarchy here, my comment is about preventing the duplication of attributes in different classes that play the same role in the RM, like code_string or terminology_id. I believe we are talking about different things.
That post indicates one way to achieve a set of primitive data types, as well as simple types like coded term, quantity etc, that can have a common parent. We don’t have this structure in openEHR. For data fields that have statically known types (Date, Coded term etc) it is attractive to use the simplest type available for the purpose. For polymorphic fields like ELEMENT.value representing values from the real world, we need something else - not just a parent type, but a clean way to distinguish measured / stated, and probably a few other things.
When I first started with openEHR I was confused by the duplicate datatypes like Terminology_code and CODE_PHRASE. I soon realized why they are needed. Before RM classes are generated from the RM specification files, they “don’t exist” and RM specification files use e.g. Terminology_code.
Foundation types in BASE are needed to specify RM.
RM data types are used once the RM “comes into existence”.
Indeed, if we had had Terminology_code back then, we would not have created CODE_PHRASE. Terminology_code is a good example of a data type that is of a better design than the original we created (i.e. CODE_PHRASE) - it is based on SNOMED experts’ analysis of how to point to a terminology concept code.
Hi @thomas.beale I’m afraid there are still some bits here I don’t get. Are you implying inheritance shouldn’t be used at the foundation types? If yes, what purpose does it serve?
What I would try to reach for openEHR RM 2.0 is just to remove all duplicated attributes in similar types, and use the foundation types where needed in the RM, including in data_types classes.
If that involves having some inheritance in the foundation types or not is something to determine, not sure why that should be avoided a priori.
Again, this is just an exercise, I didn’t think about how this should be modeled in a concrete UML, when I have some time I’ll do that to understand the scope and reach of this refactoring and I will share it here to discuss.
It generally won’t exist in the Foundation types as such, because they are usually built-in types of languages, and they will just inherit from Any or Object, but not from some Primitive type. So there is usually no type available to use in a place like ELEMENT.value. To construct one, an inheritance structure has to be created - in our case, with DATA_VALUE as the parent - and with wrapper classes for the various primitives, plus more complex data value types like DV_QUANTITY and so on.
But it would be helpful in some places, e.g. Subject Proxy, to have simpler types, even like Quantity, Terminology_term that don’t assume much, and can be synthesised from openEHR, MPI systems, RDMBS sources, FHIR, HL7 v2 and so on.
Do you mean that foundation types do not have any inheritance more because of the concrete technology than for our decision to do so?
If that is the idea, I would say it might be true in some cases if we chose to use fairly basic types, though, for instance, a foundation date type in Java might be mapped to a class that certainly don’t inherit from Object/Any but from another class.
But I understand we don’t need to represent the full inheritance structure of the foundation types in our model. I would still like to make the exercise to refactor DVs + foundation to check if that holds true.
This is clear for me, never questioned that point. I don’t think ELEMENT.value should be something else than a DV. My point was to analyze the design of a refactored model which reuse foundation types inside DV types to avoid duplication of attributes in the RM, and remove unneeded types.