I’m developing PROMs in the UK in openEHR. I have noticed that a self reported data archetype (container for PROMS) has been created: Clinical Knowledge Manager
I wanted to know from the correct modelling perspective to maximise reuse etc should I have used the container archetype or is the one I created OK? Do I need to change anything.
The COMPOSITION archetypes are like a blank paper sheet, with a name. No archetypes can be added to a template, unless there are a COMPOSITION to put them in.
Your quick assessment can reside in any COMPOSITION, depending on whether it is self-reported, during a consultancy or stay or something else.
The assessment should be worked on a bit more, to comply with the design style.
So what is the purpose of the self reported data archetype (container for PROMS) if its a blank sheet? How does it fit in with what I have created (QuickDASH) (again forgive me for the stupid questions from a newbie!).
I appreciate the style guide hasn’t been militantly followed but pretty good for a newbie I think in particular for a fairly new concept of self reported PROMs etc. Isn’t that the purpose of publishing it on the CKM so that people can contribute and improve it? (Apologies again for my ignorance).
The Self-reported data Composition acs as the top-level container for one or more Entry archetype like PROMS scores.
Any time you commit data to an openEHR CDR it has to be in the context of a composition. So templates provide you with the way of slotting in Entry archetypes like PROMS or procedure inside a composition.
You don’t have to use the self_reported_data composition, that will make sense in some cases but not in others. As Thomas has said there is a way of flagging a composition composer (author) as being PARTY_SELF which says that the person themselves was the author but the self-reported data composition allows a bit more detail to be recorded about exactly who was involved (may be a carer)
So my original version is an observation archetype. So its ok to carry on with this way of creating it or do I use the self_reported_data composition that you have shown in the archetype designer above? ALL PROMS are self reported by the patient.
Should I upload the self reported one that you have created in the link above or leave it as it is and it can be changed later?
As you know we are creating a whole suite of these PROMs so its worth ensuring we have best modelling practice for reuse (I appreciate we have certain requirements from our developer SC13 that may not follow perfectly the correct openEHR approach?)
Carry on with just getting the PROMS Observation reviewed. |Each archetype is regarded as its own sperately governed component, that can be embedded in any appropriate composition. What I have linked to is a ‘template’ not an archetype - the template brings together the self_reported composition container archetype and you new archetype to create a delpoyable but use-case specific model.
It would be perfectly reasonable for the same QuickDash archetype to be used inside completely different compositon e.g an Encounter, if perhaps the score wa completed as part of a clinical encounter. Ultimately these are all cross-queryable.
How can I invite reviewers to review it? Should I post it in the new archetype section of discourse to make everyone aware of it?
To me its a quick one to review as the data is fixed to the specific questions from the validated PROMs. I guess its essentially a review to check style guide (not sure how this differs for self reported (Patient) archetypes).
The problem (in both CKMs) is the difficulty in getting Editorial support for the process. Even though, as you say, it is not likely to be hard to do, nevertheless, it does need someone to manage the process and ensure compliance with Style guides.
It is something we would expect openEHR UK to help get running more efficiently but will require finding some sustainable resource and a fair methodology.
We can probably get something going temporarily but it really needs to be put on a more sustainable footing, especially as openEHR is advancing in the UK.
I am keen to get speciality societies from the British Orthopaedic Association (BOA) involved. I wanted to get a few reviewed in particular these to show how it all works to get engagement:
Here’s a very draft PROPOSAL I prepared for modelling the content and workflow for patient reported questionnaires (PROMs, PREMs, FREMs etc.). Feedback welcome. Hoping to discuss in detail during the openEHR Conference in Reading (and the sessions on the 4th of Monday). @pablo@ian.mcnicoll@Kanthan_Theivendran@heather.leslie@ukpenguin
Thanks Koray,
It’s become more a manifesto, but very useful as a background for further work. We need to tease out what belongs in the archetypes, templates and the app using them, and also what the tools allow us to do. Some of it isn’t possible to sort out in a short timeframe.
I am working on my first project after completing the Rosaldo Masterclasses.
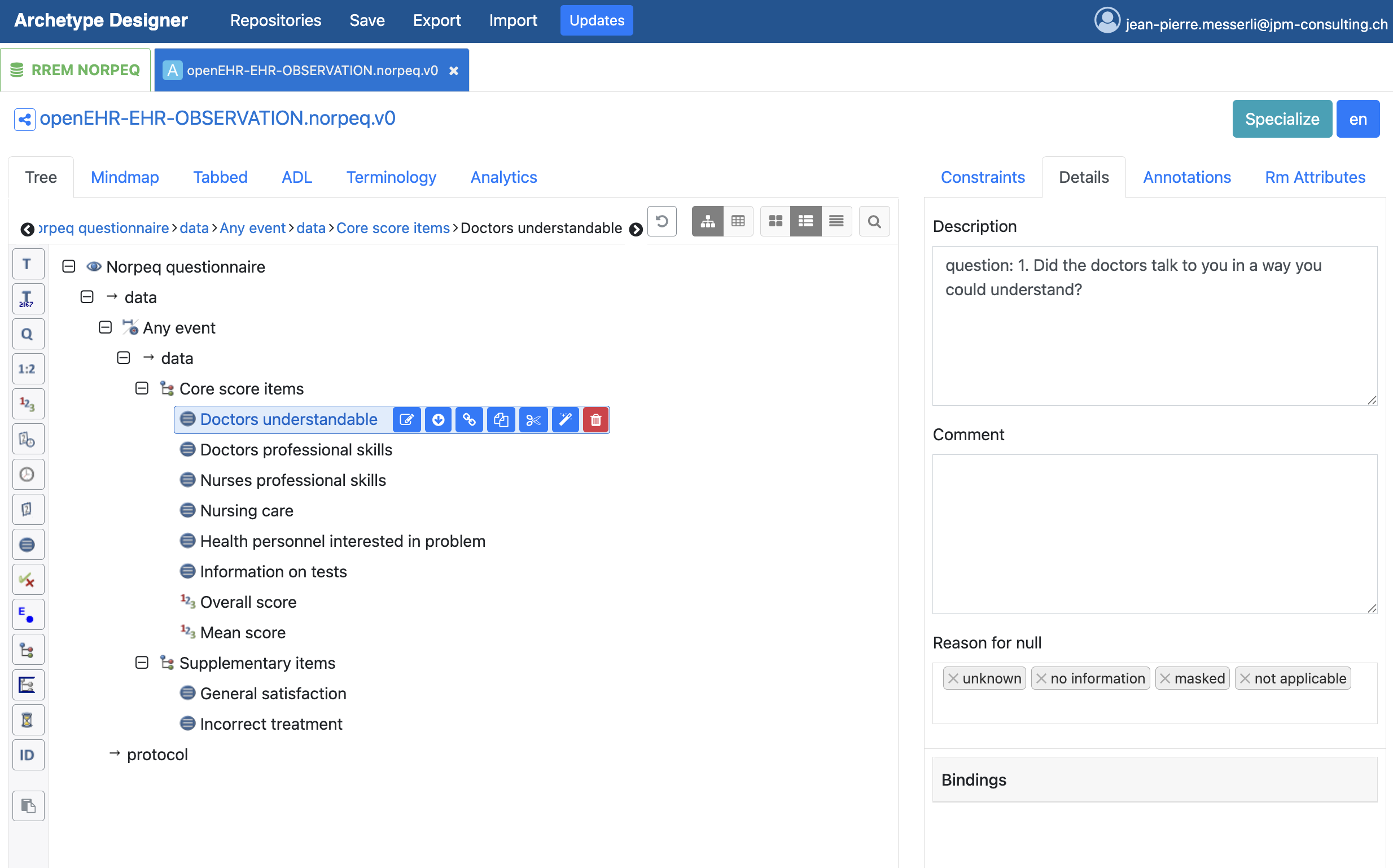
As part of the Swiss Federal Quality Commission (EQK) OpenPROMs pilot programme, I am modelling the PROM EQ-5D-5L and the PREM NORPEQ in openEHR.
I found the PROM EQ-5D-5L in CKM and translated it into German (de-ch), French (fr-ch) and Italian (it-ch) according to the official translations of the Swiss register SIRIS.
I have to recreate the PREM NORPEQ. To do this, I found Ian’s template and Koray’s instructions in this post. However, I mainly followed Ian’s template.
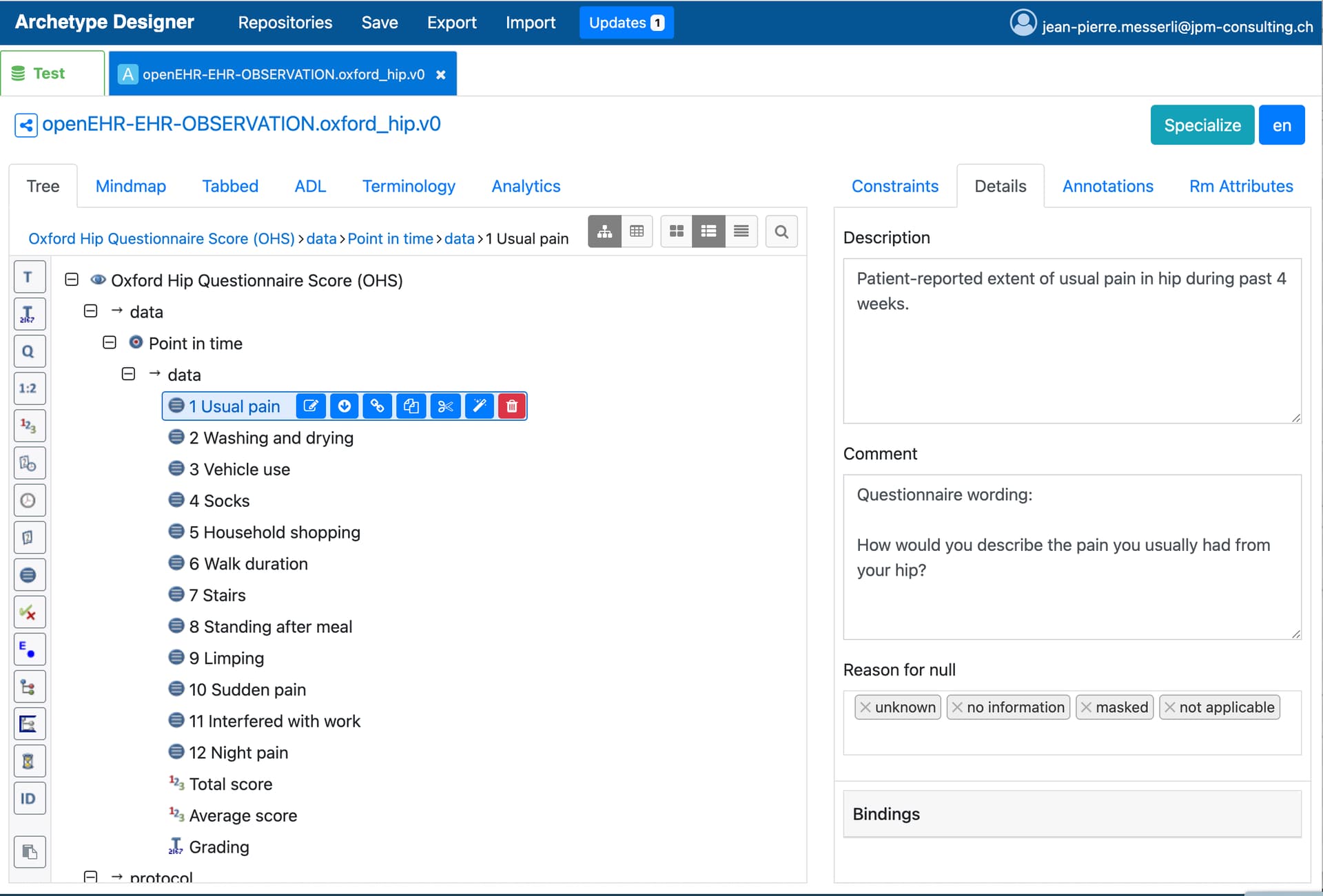
The challenge with the PREM NORPEQ is the lengthy wording of the question per item. I therefore chose a short text for the name of the data field and placed the actual question for the patient in “Description” as in Ian’s template.
I’m not up to date on the rest of this topic and the discussions around prom modelling.
But in general I would say best practice is to put the ‘question’ in the ‘text’ and only more elaborate descriptions and remarks in ‘description’. Because form renderers (like medblocks ui, and similar for proprietary offerings) pick the ‘name’ field as a label for an input text box, and some pick the ‘description’ as a ‘secondary label’, that’s displayed only on some user action like a mouse hover, or clicking an ‘I’ symbol. Unless this is desirable behaviour for the form, I would recommend to just put the long question into ‘text’. But before proceeding we should understand @ian.mcnicoll reasons for his approach.
Hi JP, after further discussions with the team I agree with short labels and put the long form into description. AFAIK this IS the recommended approach but worth checking with @heather.leslie as she could make sure it aligns with other modelling patterns and best practices.
but there was also a very long discussion ‘hosted’ by the openEHR tem at Basel which got a bit stuck on the same topic.
The Apperta archetypes were an earlier attempt to solve the problem but were also driven by a particular openOutcomes application requirement, and a current specific limitation in webTemplates so I would not use these as exemplars.
Fundamentally, there are several compelling requirements that are in-conflict.
We need to be able to represent and easily show the full original text, both to help implementers and to help the CKM editors satisfy PROMS licence-holders that the archetypes are compliant
This tends to go against previous CKM guidance that archetype node names should be kept short, as we are not directly trying to represent UI names. The use of long names also complicates the generation of downstream technical artefacts which use human language e.g. Web templates/FLAT format. The dev community is getting more interested in this because FHIR has shown that using tokenised English has a lot of advantages vs e.g atCodes, in terms of ease of use and e.g FHIRPath
We went round the houses quite a few times and it really came down to a choice between…
Imposing a burden on archetype authors/editors to create appropriate short names, along with some changes in tooling to allow long names to be displayed, if these were held in e.g archetype node ‘description’.
Imposing a burden on developers in potentially having very long tokenised paths in various artefacts esp in FLAT Composition formats
Until recently, I was very much in favour of using short names for archetype nodes but I can see the other argument, and I’m now coming round to the idea that perhaps the place for shortened node names is at template level. i.e if you need/want a short version of a node name, overwrite the original long name in the template, or otherwise direct the short path generator to use a short name carried in the archetype/template.
Either way, we will need some changes in tooling to allow this all to work smoothly for all parties.