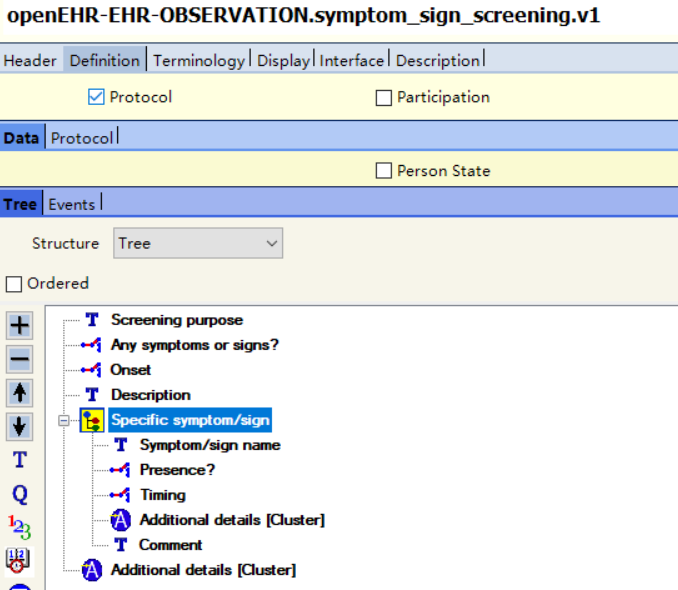
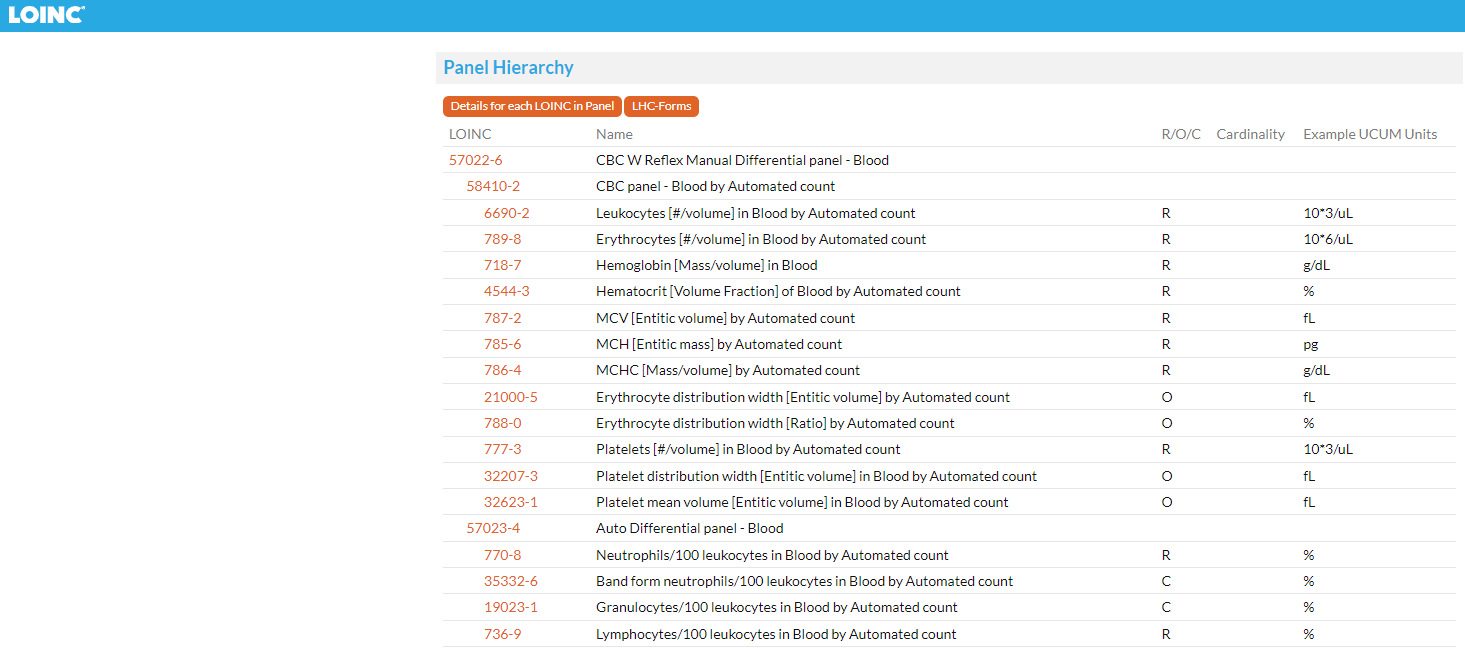
Such a kind of dynamically generated Archetypes could make the mapper’s life much more easier.
1..1 LOINC Panel --> Archetype root concept
0..* LOINC Term of Observation type --> ELEMENT
0..* LOINC Subpanel --> CLUSTER inside Archetype
0..* LOINC Term of Observation type --> ELEMENT
0..* LOINC Subpanel --> CLUSTER inside Archetype
...
I work with a client which has LOINC coded all their archetypes. This allows using LOINC codes instead of AQL paths to identify the elements. An example for blood pressure (but it works the same for questionnaires) using AQL paths:
Notice that the last example is openEHR-neutral (I can explain in more detail how it works if there is an interest). It states a mapping from FHIR using LOINC and SNOMED CT codes alone. It could be used by any information model which has its artifacts coded.
Mapping EHR data and interoperability is not a technical problem. Once the archetypes will be LOINC and SNOMED CT coded, the mapping will be automated.
This is not a critique of the work done on existing archetypes by the clinical modelers. I’m stating my observations on a difficult future work that is still required to achieve semantic interoperability among different information models in healthcare.
And this might not even be the modelers “fault” since I see that people doing the coding have titles like “Clinical Terminologist”. I guess clinical terminologists should be involved with openEHR archetype modeling too.
There may of course be other examples where this is more useful, but for things like (clinical biochem) lab analytes or panels, I wouldn’t want specific archetypes (generated or not) for each of them.
Why? Because there are thousands of them, and they will need to be governed. Additionally, a lab result OBSERVATION will need to contain a lot of additional elements not part of the LOINC panels.
This is an area where information models and terminology work really well together, by using the analyte terms from LOINC, NPU or whatever within more generic information models like Laboratory test result and Laboratory analyte result.
Could maybe generating templates or maybe even just terminology bindings, create similar kinds of effects without the drawbacks of generating archetypes?
The client I mentioned has solved this for 3000+ lab archetypes. As far as I can tell they used a combination of generated archetypes and templates with LOINC coding (so everything you mentioned ). I cannot speak about their work (my part is only generating demo instances for these lab OPTs), but maybe they will decide to comment here.
I can share an example formula that clinicians write for setting random values and then use it for the interpretation (notice the use of only a LOINC code so the formula can be used by different information models):
# The normal range is 3.4 to 5.4 g/dL (34 to 54 g/L).
# Source: https://www.ucsfhealth.org/medical-tests/albumin-blood-(serum)-test
1751-7:
uri: http://loinc.org/1751-7
name: Albumin [Mass/volume] in Serum or Plasma
set:
- attribute: value
element:
value_intervals:
g_dL_snomed: 2.5..6.5
g_L_snomed: 25..65
interpretation_intervals:
g_dL_snomed:
low: 3.4
high: 5.4
g_L_snomed:
low: 34
high: 54
FHIR StructureMap and the FHIR Mapping Language are possible representations of EHR data mapping however in my experience they come short when complex conditions are required. This is why I decided to support the use of a full programming language (see at the end of this example). YAML is great but healthcare data is too complex for YAML. It is good to be able to use code when needed.
Another difference to StructureMap is integrated post-processing of the mapped data. Calculating Body Mass Index (BMI) is such an example. For this calculation we use mapped elements to calculate a value of another element. I wanted to support such use cases in the same YAML and avoid using another tool for the post-processing. Person with clinical knowledge who will write the mapping rules also has the knowledge how other data needs to be calculated. They can use the same YAML to specify additional post-processing rules so that they don’t have to rely on others (e.g. programmers) to do it for them.
@siljelb You know, there are so many lab tests and panels AND their countless combinations that mappers would face significant manual workloads even with models like Laboratory test result and Laboratory analyte result available.
@borut.jures Thanks a lot for your valuable sharing!
That is the problem Lab panels vary enormously even within single countries. At least for lab, we specifically designed the archetypes to be integration driven and not to have specific lab analyte/panel targets.
Could maybe generating templates or maybe even just terminology bindings, create similar kinds of effects without the drawbacks of generating archetypes?
One option worth exploring, I think is the FHIR ObservationDefinition - more of a lightweight set of reference metadata than full models.