There is a new pattern in development for imaging examination. The pattern is based in specialisation.
See the structure from this archetype: Clinical Knowledge Manager
I am ambivalent. In many modelling situations I tend to use expansion by extensions (slots). This is a robust pattern which makes expansions flexible and independent. Still there might be situations where specialisation is the right approach.
What I fear with the suggested pattern is an explosion of archetypes.
I would love to get some feedbacks from you “specifications-specialists”. What is your opinion on the suggested pattern?
specialisation corresponds to the IS-A (or ‘a kind of’) relationship.
the effect of allowing the data elements from both the specialisation parent and the child to be in the same level of structure - i.e. to be structurally integrated.
it also gives you substitutability, like in OO programming languages, such that:
a slot to allow some archetype xyz will allow any specialisation child of xyz;
this is also true of any mention of the archetype xyz in an AQL query - the same data points should be picked up from data created by specialised child archetypes
in a specialised archetype, you can redefine existing nodes from the parent
Using composition (slots) has the following semantics:
composition corresponds to the PART-OF i.e. whole/part relationship. The parts (what goes in the slots) are not ‘a kind’ of the root archetype.
there is no substitutability in of the parts for the whole in archetype slots or in queries
there is no node redefinition by the sub-part archetypes
it doesn’t allow structural mixing as with specialisation; the included parts are always within some sub-structure, usually a CLUSTER
you have to have thought of the possible slots, i.e. the possible joining points, when designing the parent. With specialisation you can freely add what you want in the child after the fact.
In the ideal, both specialisation and composition should be used to obtain re-use (of the parent / central archetype data points) plus componentisation.
NB: specialisation is only properly (and well) supported by ADL2. Tools like Archetype Designer are ADL2 inside, and CKM is moving to the same situation as well. Nedap’s editor (based on Archie) is 100% ADL2.
First of all, is there a reason we can’t have this discussion in a more public part of the Discourse site? After all, it’s about modelling patterns and not specifications per se.
Second, this is an important discussion to have, and it’s timely to have it before or while the archetypes are being reviewed.
Then some generic thoughts about the pattern and its implications:
This is an identical modelling pattern as in the established [physical] examination finding family of archetypes. That pattern was designed in as specialisations partly based on feedback from DIPS about the need to query a single element in an archetype or its specialisations about a specific body structure using SNOMED CT codes. I believe eyes were used as the primary example. The pattern works quite well for modelling, apart from the ADL 1.4 related hassle of managing specialisations when the parent archetype is changed. As @thomas.beale points out, governing the archetypes in ADL 2 would have made things much easier. Archetype Designer works in ADL 2 internally which makes things easier than they were using Archetype Editor, but native ADL 2 in CKM would have been even better.
An explosion of archetypes will happen in this space whether we base our modelling on specialisations or cluster archetypes for insertion in slots. There’ll be a multitude of different body structures which need specific data elements for their specific examinations.
Yes indeed - I had meant to add that same comment. The ‘explosion’ is essentially a consequence of biology + specialisation of clinical investigation, not some information modelling strategy.
I agree that it is an important discussion to have. Over the years there has also been shifting thoughts regarding speicialisation v.s. parallell copied patterns in archetypes not formally linked by inheritance (for example regarding smoking, alcohol etc) that could also be included in this discussion. (Composite PART-OF patterns can be combined with both.)
I believe the discussion has now been moved to a public space, available for reading without login etc. right?
The intention was to have some feedback from my colleagues in the specification group. If I was the only one with concern about the pattern there where no point in spreading uncertainty. I am ambiguous on this and wanted some initial feedback from my peers since we have been talking about the generic concepts of specialisation and composition over the years. Among other @Seref have some thinking on this.
There are no other reason for not going public with the discussion. I can see from the thread that there is lots of competence that could and should be shared with a wider audience.
This need can be achieved with both specialisation and composition IMHO.
I want an explosion of new information model. Health and care is unlimited in the needs for clinical models. We are developing and sharing new archetypes more or less continuously these days. Thus the term explosion was not precise here.
What we need to consider is the level of details or specificity for the models (archetypes) and we need to take into consideration the combination of information models and terminologies/ontologies.
This topic is about a cluster for imaging examination. The concept description is: “Findings on radiological examination of a specified body structure or region”. Looking ahead we will see discussions on when there should be a new (specialised) archetype and when to use compositions to define details about body structures and regions. One archetypes under review is Imaging examination of an adnexal mass. This archetype is third (3th) level specialisation. It does some redefinitions from the parent and add a few elements - as far as I can see. Most of the added definition could be done as suggested or using compositions together with a template.
I have not enough competence to say if it is good or bad. Neither from a technical or clinical viewpoint. I just to want to lift the discussion to a wider group of people. The topic is a “real openEHR” topic; it is where clinic meet software - both on specifications and in implementation. That’s why we would benefit from an open discussion on the patterns we develop and implements in the models and systems.
First: The parent archetype CLUSTER.imaging_exam has just been on review and published, and we’re about to put out for review a bunch of specialised archetypes of it. By reading and participating in the review of the parent archetype the content and plan to use specialised archetypes should be known to the community, so the timing of this discussion is not good. The ART-project in Oslo University Hospital which plan to use the specialised CLUSTERs is in a hurry, so I urge anyone with something to say to come with your input as soon as possible.
Secondly: Some time ago there were a shift from using CLUSTERs to specialising, and a lot of work were done to reflect this shift in the Physical examination CLUSTERs. The Imaging family or archetypes are made with the pattern from the Physical examination archetypes. There is a hassle with “re-specialising” the child archetypes after the parent is published (or go from v1 to vn), but doable. We found an error in Archetype Designer when doing this yesterday, but Better will hopefully solve it soon.
One question I have now that I look at the CKM exam archetypes …
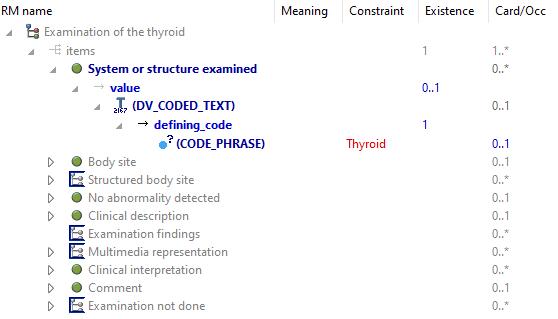
Here’s the top-level archetype, seen in the workbench:
And now the thyroid one:
The only difference is that the coded term for the System or structure examined is overridden with ‘Thyroid’ (normally mapped to Snomed).
There are a lot of exam child archetypes like this - I don’t see the point of doing this, since this can just be a runtime choice. Or is it that these archetypes are just waiting for an (in this case) endocrinologist to come along and add more specific data points? I can see this making sense.
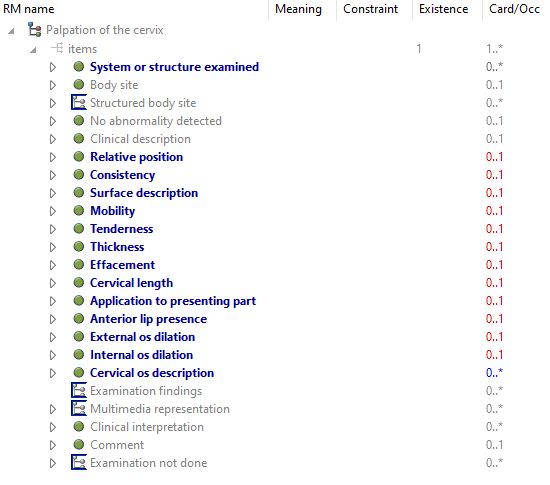
There are of course child archetypes with real differences, e.g. palpation of cervix.
We use ACTION.procedure a lot. The pattern is to add terminologies to group the type of procedure and the specific procedure within that group. Based on different categories of procedure we expand the details with Cluster archetypes. An example might be the Bowel preparation for colonoscopy.
We visited several possible patterns. Create new ACTION archetypes for the domain, specialise, etc. We ended up with the pattern above. First of all it felt good to reuse an already reviewed archetype. The information model is also quite easy to understand. By using extension by composition (slots) it was trivial to extend the reviewed action archetype.
For query (to get the data back) there are several AQL patterns to use. You might query using the terminology at category or procedure element. Another approach would be to query entries which contains a specific archetype. Another mechanism is to use information at template level. All the mentioned strategies might be combined depending on the use-case for querying.
#openehr is quite flexible on this questions. That’s needed to cope with the complexity of healthdata. Just to remind you : The reason why I follow up on this is to understand and learn, and then to make good patterns to be able to govern data for life
Another technical thing to think about in this modelling pattern: if you use a parent exam / procedure etc, and make a bunch of 2nd and even 3rd degree children, of course you’ll still never get everything.
There’ll be some annoying hospital needing exam of trigeminal nerve or mandibular foramen. So if they then create their child archetypes in the same way - as specialisations - their data will at least be interoperable with everyone else for the basic data points without them sharing their archetype. Their modelling will also be pretty easy, because all they have to do is add their specific items in an intuitive way.
So this may be an argument for using this pattern.
Don’t get me wrong - there are very good reasons to use the composition pattern (i.e. using slots), and the combination of the two strategies gives a lot of power.
I am not ADL2 expert (not even close to ). This statement is the same as with a Template where you redefine elemntes and datatype to be more specific. The archetype remains the same, but the elements are constrained?
When you create new specialised archetypes the archetype (root) id will change. If you then query a procedure archetype using AQL you will not get the newly created archetype id. At least not automatically. The developer of the query must relax the constraint on the AQL path to allow all versions and specialisations of the archetype.
If we used composition pattern the archetype identifier will remain the same except for versioning. The AQL will still work without modifications.
Above I said except for versioning. That’s another problem. An archetype going for Vn to Vm has a breaking change. Which means quering is potentially unsafe. You can’t know what to expect from a breaking version into a new one.
And then: How to handle versioning in a multi layer of specialised archetypes? Is this trivial for the clinical modeller? Do the mainstream tooling support this? If there is a no or maybe answer to one of this : what kind of actions do we need to do to make this work across all layers of clinical data driven applications?
You can also add elements in a specialised archetype, if the parent doesn’t prohibit it, which it normally does not.
The query engine needs to have access to the archetype library, which includes the specialisation relationships. That’s a basic requirement. If it’s not doing that, it’s just missing data, and the responses will be wrong.
That should be the default, because by definition, data that is an instance of a specialised archetype A’ is an instance of its parent A. So not picking up the A’ data is an error.
That’s why the major version is considered part of the id, and in that case, the query designer has to decide whether he/she is looking for vN or vN+1 (or later) data.
Well tooling can easily detect if any change breaks the specialisation conformance. My ADL Workbench was designed to do primarily this; Nedap’s Archie-based tool does it, and anything that uses Archie’s library does it. AFAIK, Better’s library and Archetype Designer get this right as well, and CKM has its own code and does this checking as well. There’s no guaranteed that there are literally 0 bugs in any of this code, but it’s been tested for some years now, so it is pretty solid.
Not sure about this. AFAIK the query engine doesn’t need access to any archetype library. This is needed in design-time for templates and other artefacts for input, and also for the query developer for tooling and guidance. The query engine can work without any such archetype knowledge. It must somehow know about the RM, but that’s another story.
I would be happy to know if other implementers do this. This will certainly break most of our applications. Navigation though a hierarchy of archetyped data either with AQL or traversing paths within a composition tend to use the archetype root id as is. Adding some regexp around this adds new level of complexity.
What are the experiences from other vendors building clinical applications on this?
We’ve found that Archetype Designer doesn’t change an element’s occurence in the child archetype, if it has been changed in the parent. Also an error when there has been changes of ‘Included’ Clusters in a SLOT element in the parent. Better is informed. Otherwise it seems to work.
One challenge we might experience in the review of specialised archetypes, is to make the reviewers understand that the inherited elements are “not for review”, only the specialised (or added) elements. To clinicians not knowing the way specialisations works, that can be a mystery, I guess. We have to deal with that in the invitation text, and explain.
Well that requires good visualisation. You can see in the screen shots I posted above in this thread how the ADL Workbench does it - new nodes are in blue, and new or changed constraints in red; nodes inherited unchanged are in grey. So this view shows you the totality of the archetype, but also the subset that you could review. Any visualisation that does the same kind of thing should help users understand specialisation I would think.
This makes me nervous. I don’t have the technical insight or experience from implementation to evaluate what is right and wrong, or the implications. To my knowledge, there is very few specialised archetypes published - I only know of TNM Pathological classification Clinical Knowledge Manager (openehr.org) which is specialised from TNM Clinical classification. It would surprise me if these aren’t already in use somewhere. How have vendors solved this? Calling for @ian.mcnicoll@borut.fabjan@joostholslag@Seref . Any others?