I would frame a ‘good’ questionnaire simply as one that gets the job done. They can be ‘garbage’ from a pure design point of view - I really don’t mind. Let local archetypes be used as messily and frequently as needs be if they provide value at that local level. But, please, let’s all agree not to encourage ‘garbage’ archetypes or even data elements to be shared or reused.
In contrast, I care enormously about how to try to converge the common use cases toward higher quality, standardised models. The approach that we’ve outlined previously is the current collective modelling view that best suits that goal.
Creating a ‘questionnaire service’ fulfils a technical and theoretical goal to support reuse, but simultaneously misses the semantic goal of :
- promoting the reuse of high-quality, semantically unambiguous questions that converges data, and
- guiding future modellers on how to build better quality questionnaires, even ones that could be broadly reused in multiple languages.
Can we manage a massive questionnaire proliferation? Remember, it is not just adding an archetype here or there, but involves maintenance across languages, terminology binding and governance? What happens where questions conflict - do we care? should we care? I think it is our role to care, and I strongly suspect this approach is unsustainable, or it will not provide the value and end-solution that we all seek.
The screening questionnaire family of archetypes in CKM is the starting point for converging common patterns for common concepts - a baby step towards higher quality, standardised questionnaires.
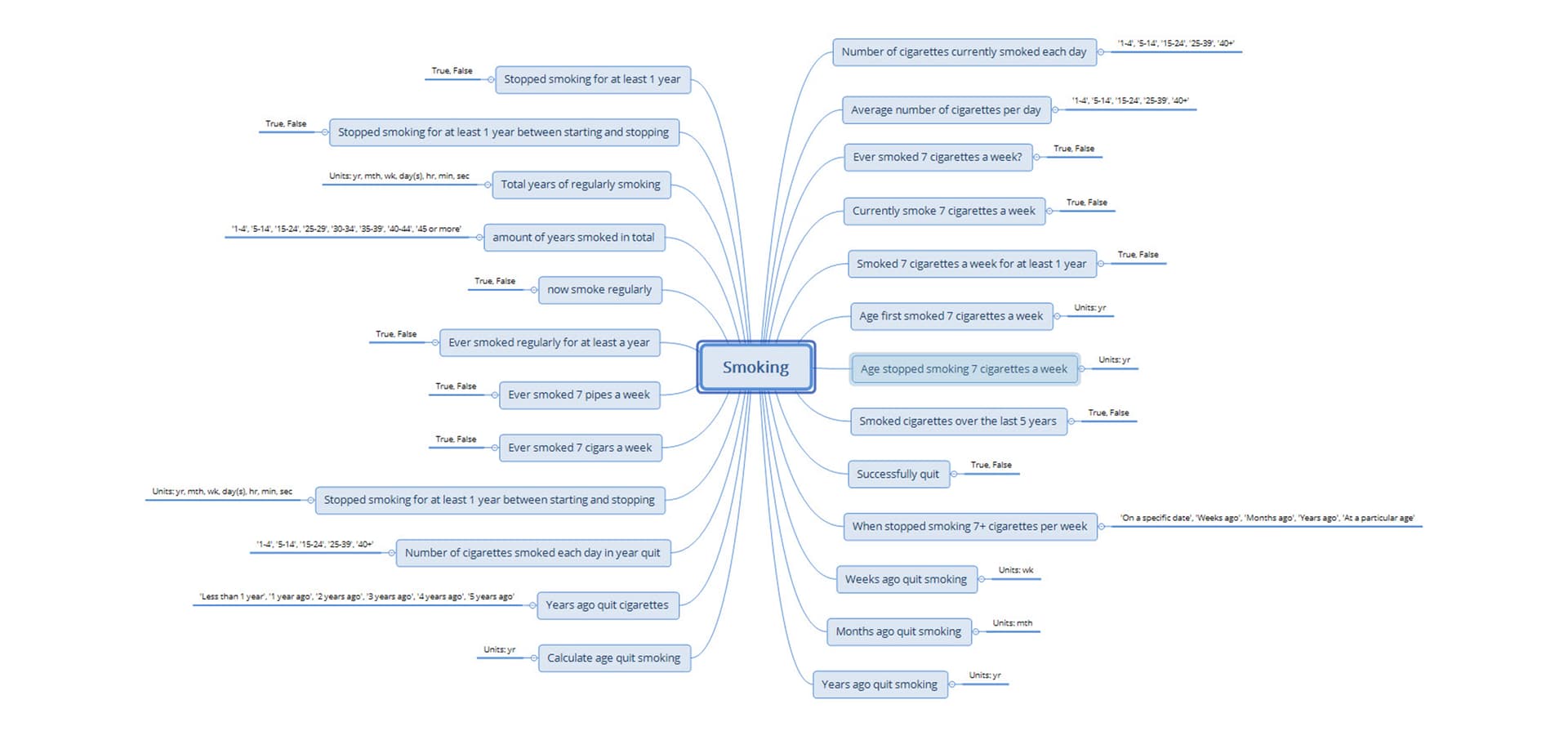
Without this approach, the questions in the mindmap, below, are good examples of what would likely be proliferated in the proposed questionnaire service. These questions came from one project I worked on nearly 15 years ago. It has shaped the current clinical modelling approach and I use it as an example of what not to do in all my modelling training.
The context: 15 years of questionnaire data captured by a SINGLE organisation. The resulting 83 data dictionaries (published in 83 Excel spreadsheets) represented 7 different cancers. Over those 15 years, they had 4 different data managers, each tweaking and improving the data dictionary ever so slightly… all with the absolute best of intentions!

When I was engaged by this client my first step in analysis was to deconstruct each of those 83 spreadsheets to identify common concepts within each. This mindmap is the result of gathering all of the smoking-related questions in one place. The resulting archetypes provided the client with a visualisation of the inconsistency in their data and they were so horrified, that they stopped the project to try to harmonise their data for each disease.
The potential number of questions that can be ‘questionnaired’ is probably never-ending, because no one tends to think of the underlying patterns, nor of the consequences of the question design - they just want ‘their question’. This is the same thinking that every vendor has used when they design their unique, special and proprietary data format over the previous 60 years.
Instead, we need to find ways to provide some guidance and nudges towards improving quality:
- What is the concept? Is the focus on the data collection on cigarette smoking? Tobacco smoking, from all forms? All smoking, including non-tobacco? If tobacco, then is it about smoking or non-smoking use?
- Is it about typical use, including episodes of use? Or about actual use - on a specified date, over the past 3 days, average over the past 5 years or amount between the ages of 20-30?
- What conclusion can be determined if a single question containing multiple variables has a simple binary answer? There are many examples in that mindmap, designed by experienced and well-published researchers!
Common screening topics/patterns already represented in CKM:
- Published -
– Diagnostic investigation screening - what tests have you had?
– Exposure screening - what health risks have you been exposed to - smoke, noise, asbestos, infectious diseases?
– Management screening - what has been done to you?
– Medication screening - what are you taking?
– Symptom/sign screening - what are you experiencing?
– Problem/Diagnosis screening - what problems do you have?
– Procedure screening - what operations/surgeries have you had?
– Social context screening - social isolation, dependents, homelessness, interpreter need
– Travel screening - where have you been travelling to, under what circumstances?
- In review
– Substance use screening - tobacco, alcohol, other drugs
- Draft
– Family history screening - do you have any family health issues we need to know about?
– Medical device screening - do you have any implants we need to know about eg before you get in the MRI?
At the very least, each of these OBSERVATIONs focuses common questions into an ENTRY level model that will support potential querying at concept level. The screening questionnaire archetypes are effectively hybrids between a ‘single source of truth’ archetype and a generic one containing zero semantics. They are deliberately loosely modelled to start to provide some pattern guidance on how to screen for health information. Templates can be then used to support local variations of questions within the context of these common patterns. In the future, maybe we will start to govern templates that are built on these patterns, always aiming towards convergence and governability, rather than random proliferation.
As a community, software engineers and clinical modellers (especially the CKM Editorial leaders) need to co-design solutions together, that bring the expertise of both into the openEHR offerings. We need to solve problems by investigating both the technical opportunities and modelling approaches, and then make collective decisions on a joint approach. Unilateral solutions only create divergence, fragmentation, and pulling in different directions.
What we also know from Stan’s experience is that the CEM proliferation was not governable, so much so that he initiated the CIMI project so that the model governance would be lifted from a single data element to more sustainable groupings, aka CIMI archetypes. We must learn from that experience and not repeat it.