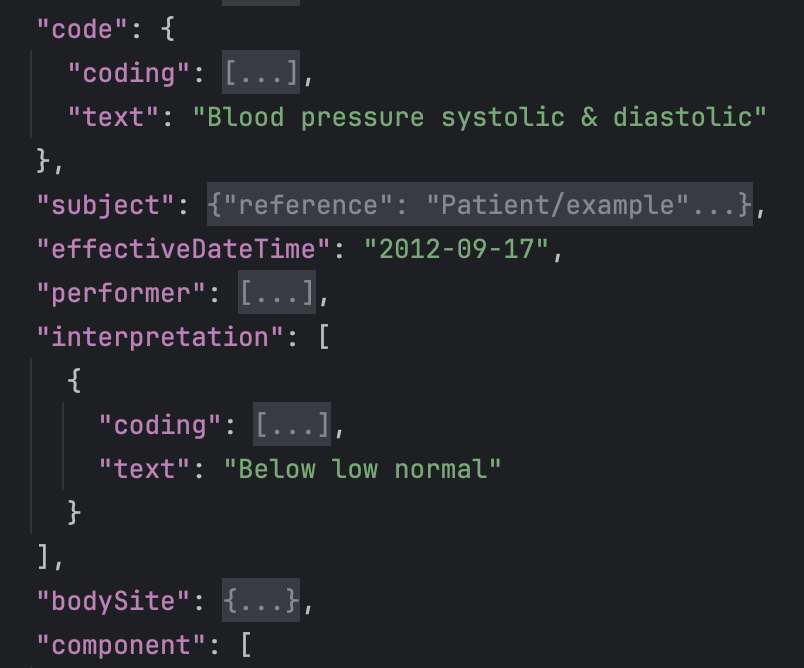
Currently I’m mapping panel level interpretation to /data[at0001|History|]/events[at0006|Any event|]/data[at0003|Data|]/items[at1059|Clinical interpretation|] in openEHR-EHR-OBSERVATION.blood_pressure.v2.
Where do you usually map the systolic/diastolic interpretations found in FHIR? I don’t want to “skip” them since the data would be lost.
If I understand you correctly, this profile has separate “Clinical interpretation” elements for each of systolic and diastolic in addition to the “Clinical interpretation” element for the overall blood pressure measurement? Is this a real world clinical requirement?
I hope they don’t publish such widely used “hello world” examples without clinical review
I have seen other non-FHIR data where systolic and diastolic have their own clinical interpretations. Wouldn’t it be logical that any quantity value could have an interpretation (and range).
I guess it depends on who you ask? Personally, I’ve never heard of this clinical requirement before. That in itself is of course no proof that it doesn’t exist, but the fact that in the 16 year history of the blood pressure archetype we haven’t had a change request about this requirement, is an indication that it’s relatively rare.
As an International CKM, being maximal/inclusive enough might be a nontrivial requirement. One of reasons for this would be that data requirements of various juridiction levels/scopes are nearly always different and maybe strange, even wierd for outsiders. For example, here (zh-CN), the CDA-based Document Exchange Specification for Health Checkup Report requires many physical examination findings should have both a textual description and an abnormality flag (T/F). The latter is often a headache for the mappers who would therefore think the openEHR Archetypes are actually not so maximal.
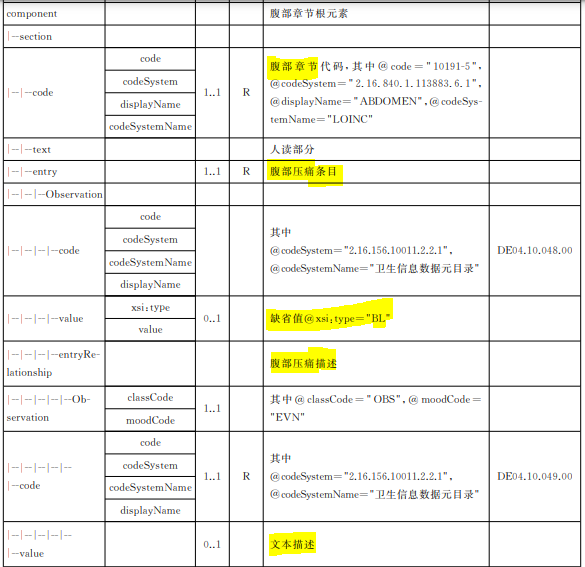
Example from our national CDA-based Document Exchange Specification for Health Checkup Report:
Section: Physical examination finding of abdomen
Data Element (Boolean): Abnormality flag of abdominal tenderness
Data Element (Text): Description of abdominal tenderness
My two cents, I tried for some time to use one of the vital signs observation examples that was on the specifications that made no real sense. Asked around and was told that they were wrong.
I’ll use Synthea FHIR data to map to openEHR. I just checked it and they don’t use “Observation.interpretation” at all
I hope somebody will be willing to share the actual anonymized data they are converting to openEHR with me (doesn’t have to be FHIR)
@SevKohler or @erik.sundvall Do you have an example data sets you are using for your projects? I’m using a different mapping then you but we could exchange ideas for the mapping specifications and compare progress (maybe a friendly competition to motivate me and your vendors to work faster ).
An example of my mapping file: blood_pressure.map.yaml (2.7 KB)
I first checked your blood pressure data/tests
I did a quick search through your data/code to find out how you solved the mapping of interpretations. Here are my findings (the below is not a critique):
Exactly, this is a problem of model alignment. So the answer by @siljelb was on the right track.
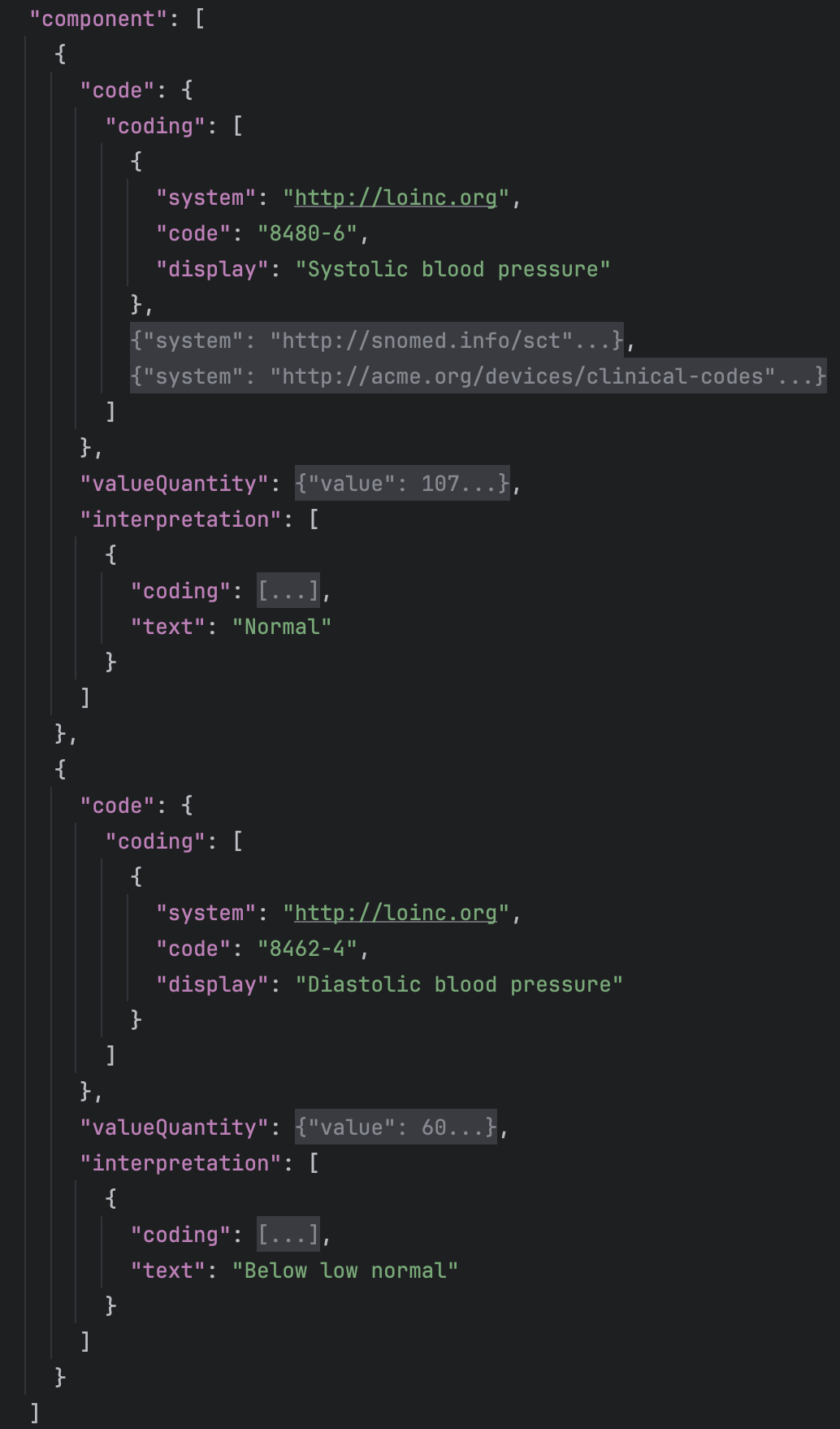
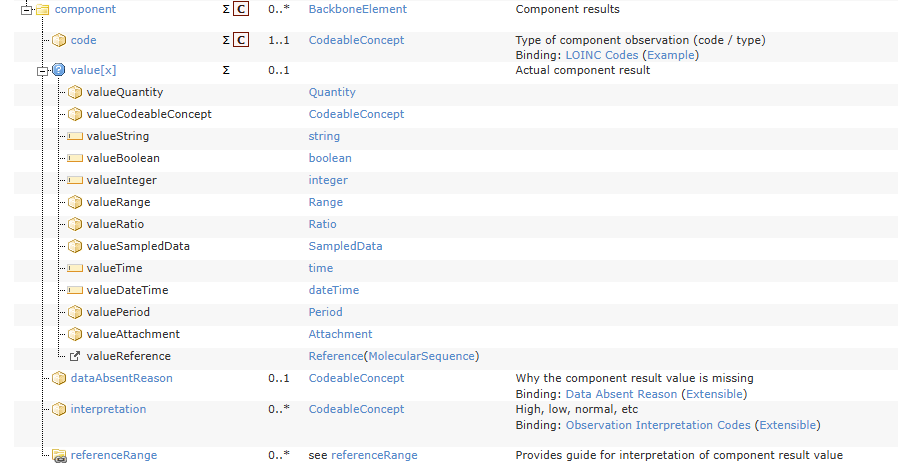
The Observation resource in FHIR defines an interpretation field for the main Observation value, but also an interpretation field for each of the component values. And that data has been filled in the example you provided. It maybe has a sense as a generic pattern for an observation, but I don’t know if it should be used specifically for systolic and diastolic data.
In the Blood pressure archetype we have only one Clinical interpretation ELEMENT for the whole Observation and not one for each of its ELEMENTs.
So, as @siljelb said, is this a real clinical information requirement?
If yes, then at some point the modeling team could add it to the archetype and you will have a straightforward mapping.
If no (i.e. it has no sense to independently provide an interpretation to the systolic and to the diastolic values), the you will have to be more flexible with the data mappings by either:
–aggregating all the FHIR interpretation fields into the single Clinical interpretation ELEMENT, or
–using the Blood pressure archetype Comment ELEMENT to put that information.
There is also the Extension CLUSTER in the archetype, but I think it would not be appropriate to use it as it is in the protocol attribute.
I checked another data source which does have separate interpretations for systolic + diastolic + both. The same as in the provided FHIR example.
I’m not a clinician but it does seem logical to have the interpretations on all 3 elements. Clinical interpretation for .../items[at1059|Clinical interpretation|] in openEHR-EHR-OBSERVATION.blood_pressure.v2 is obvious, but what if a clinician (or a system) wants to point out that e.g. systolic is in the expected range, but diastolic is way off. Currently they have to add this data in a comment element. Wouldn’t it be better to have it inside the systolic/diastolic elements?
I expect to find more similar examples in the labs data where multiple measurements have individual interpretations (and ranges) but also a summary clinical interpretation.
Is there a need to add an interpretation of measured values to the RM?
I’m not convinced there’s an actual clinical need to record this in a structured way. We’ve tried in the past to model archetypes based on “what if” extrapolation. It usually results in bloated or just plain wrong models. If a clinician presents a well founded argument why they need this, we’ll probably have to adapt the archetype. Until that happens, I wouldn’t worry about it.
While it’s all well and good to be rigorous about Archetype modeling, it’s important to know that the quality of the data structures as mapping sources could also vary. And mappers often don’t have full control over their quality when mapping their elements to Archetype data points.
When the required data points are not available in the international CKM, while it is possible to create a local Archetype to provide a required data point (which may undermine the value of openEHR in terms of interoperability) because of some reason(s) such as timeliness/efficiency of the Archetype review/publication process of the international CKM, it is not always possible to insert the created data points into the appropriate place in the Archetype structure used by the template.
In contrast, every FHIR Resouce type has an “inherited” extension because of the abstract DomainResource. Even a datatype element may have one or more extensions as children.
What I mean above is simply to suggest that we consider the inclusiveness, not to compare the merits of the two standards.
Ubiquitousness of the two nodes (i.e., Additional details [Cluster] and Comment) Would be desirable for mapping although it has the potential to undermine interoperability.