Hi all, I’m progressing with a demographics data repository and demographics REST API and found some issues I would like to share to have your opinions.
For reference, this is the demographics UML:
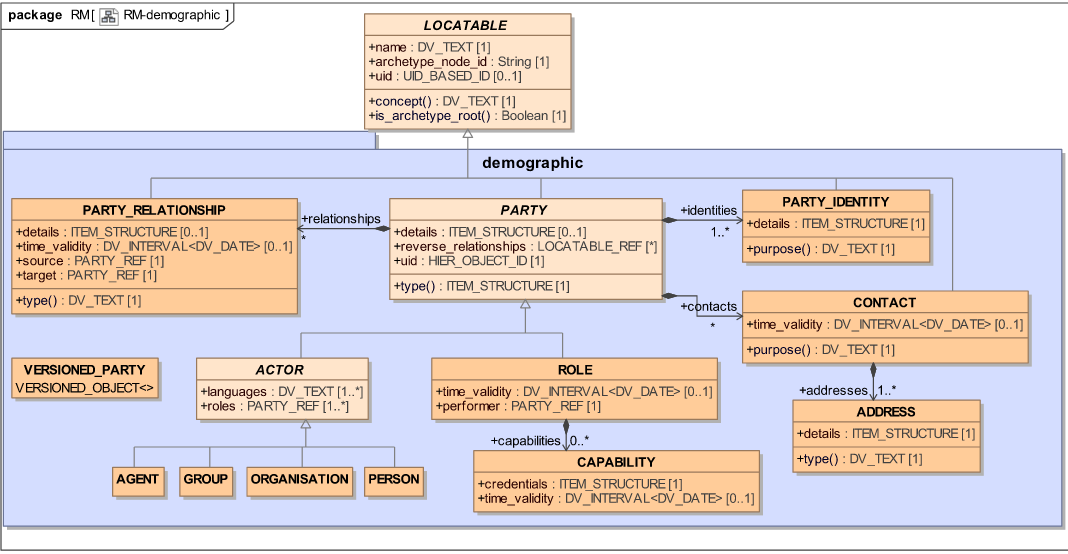
- many to one association between ACTOR and ROLE
ACTOR has a reference to 1 or many ROLEs
ROLE has a reference to 1 ACTOR
When creating those objects, since the references between them are bidirectional and mandatory, you can’t actually create an ACTOR having a reference to an existing ROLE and viceversa, so if the ACTOR is created first then the roles collection will be empty, then the ROLE is created and can have a reference to the existing ACTOR, and after that you can update the ACTOR adding the reference to the existing ROLE in roles.
So the model won’t be valid until this “transaction” is completed.
IMO bidirectional relationships in these kind of generic models are problematic, and there are many ways of representing the same thing without bidirectional associations.
One way is leaving ROLE as it is, and removing ACTOR.roles. Then ACTOR.roles() could be a method that returns all ROLEs that have performer to be this ACTOR (by uid).
Another way is not making one of the sides mandatory, like ACTOR.roles [0…*], though that could lead to ACTORs without a ROLE.
- PARTY_IDENTITY and CONTACT have a purpose() method
In the spec, the purpose() is said to be taken from the inherited LOCATABLE.name
Though the semantics of a purpose and a name are very different, and what the spec says will depend on how modelers designed the archetypes and set the names there, I mean, to be compliant with what the spec says modelers should use the LOCATABLE.name field to actually set a purpose for that class (identity or contact), which is difficult to check.
Another thing is we might be missing terminology items for those “purposes”. The spec doesn’t specify how the purpose is formalized, and doesn’t mention if it needs to be formalized or coded at all, which I think it might be useful.
- Overwhelming container objects
Since both, ACTOR and ROLE, are LOCATABLE, when creating an ACTOR (PERSON, ORGANISATION, etc.) or ROLE, a CONTRIBUTION, VERSIONED_OBJECT and ORIGINAL_VERSION should be created for each.
So let’s say we have an API to create PERSON and ROLE, and the ACTOR.roles was removed (see 1.), follow this flow:
a. p = create_person(…) > creates CONTRIBUTION, VERSIONED_PERSON, ORIGINAL_VERSION and data PERSON.
b. r1 = create_role(…, p) > creates CONTRIBUTION, VERSIONED_ROLE, ORIGINAL_VERSION and data ROLE, with performer = PARTY_REF(p)
c. r2 = create_role(…, p) > same as above
So when creating one PERSON with two ROLEs we have 3 CONTRIBUTIONS, 3 VERSIONED_OBJECTS, 3 ORIGINAL_VERSIONs, etc.
Since ROLE is a per-instance role, meaning that two PERSONs with the same ROLE ‘doctor’ will generate 2 objects ROLE each with ‘doctor’ and a different performer (PERSON), then we can consider ROLE is a weak entity in relation with PERSON or any ACTOR, so a simpler solution would be to create VERSIONED data at the ACTOR level and leave ROLE as depending on the ACTOR versioning, like subfolders in a directory FOLDER structure.
With that, creating a PERSON with 2 ROLEs will generate just one CONTRIBUTION, VERSIONED_OBJECT and ORIGINAL_VERSION, while the version.data will be the PERSON containing 2 ROLEs, of course for this to happen, also the relationships between ACTOR and ROLE need to be modified, like I mentioned in 1. or by removing the ROLE.performer and just having the ACTOR.roles on the ACTOR side, that way the current bidirectional kind-off graph structure could be just a tree, because in the current model ACTOR and ROLE are both top-level classes, though conceptually and technically a ROLE, how it’s currently modeled, can’t exist without a performer.
Note these considerations and changes to the model can simplify how the demographic API could work in the near future.
What to others think?