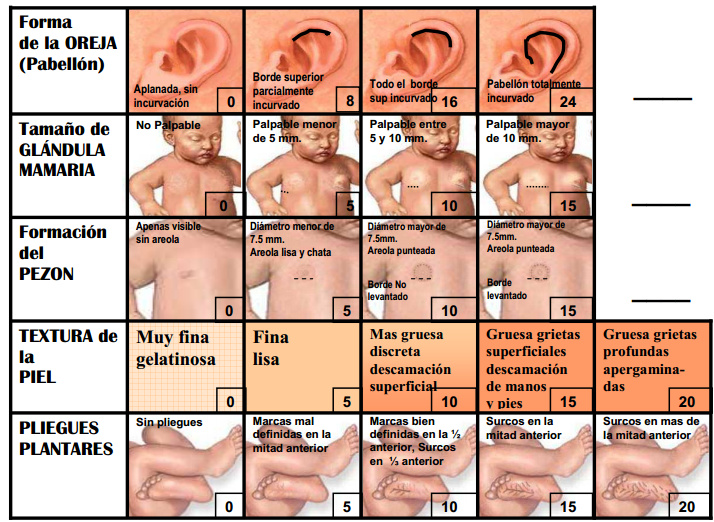
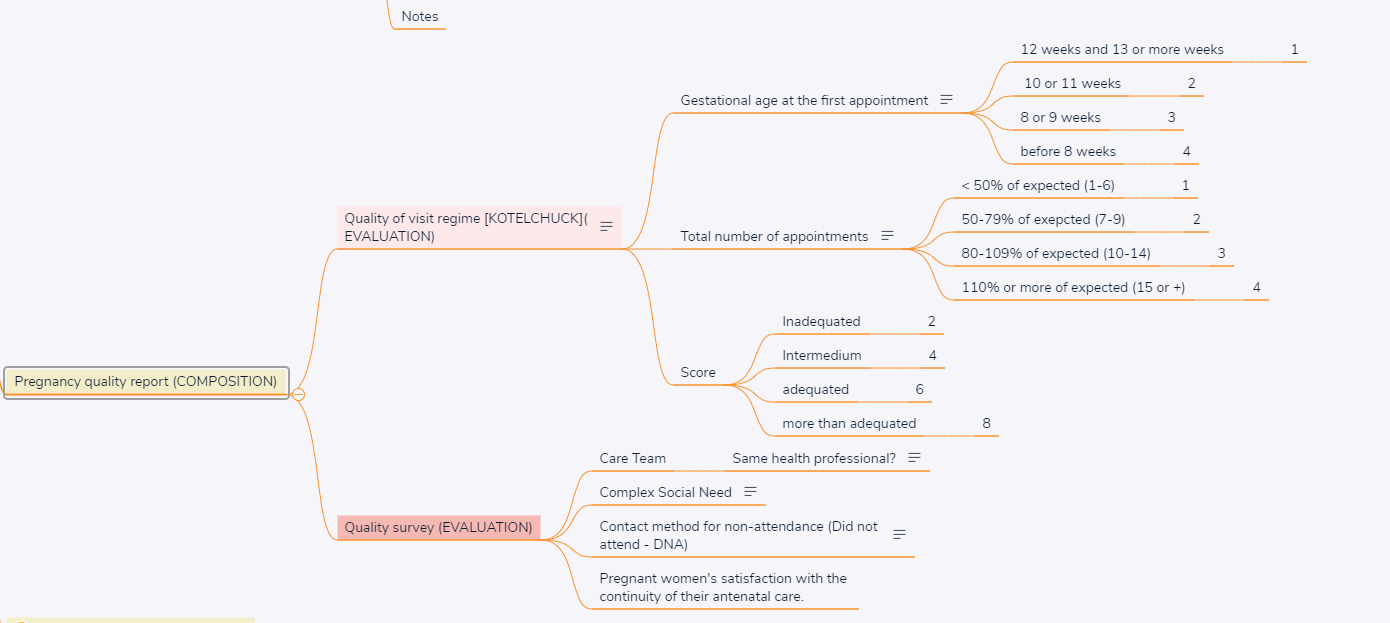
In recently reviewing the various obstetric archetypes from @danielle.santosalves, and many other archetypes over the years, and perusing CKM, I had a thought about whether scores are Observations or Evaluations.
Just to start a little fun controversy, I thought I would suggest how this should be decided and see what modellers think.
Firstly, the interesting thing about a score is that it is intended to generate some level of ‘assessment’ beyond the phenomena it observes. An Apgar generates a number that is quickly understood to mean the newborn is good to go home, or needs to go to the ICU. GCS gives an initial assessment of head injury severity. Etc.
Since scores have a built-in interpretation, they seem like they could be openEHR Evaluations, i.e. the same general category as diagnoses and other kinds of assessments. However, there is a difference. The general category of ‘assessment’ (including diagnosis) is intended for assessments that are understood as true for some time (often permanently, as in the case of a Dx for CF or diabetes type I). Even a diagnosis of severe strep throat remains true for a few days until the penicillin has kicked in.
I would argue that many scores provide more a real-time interpretation of the patient situation rather than a stable assessment of underlying disease or other process. They mostly convert underlying patient observables to a severity number, i.e. they provide an immediate interpretation of the significance of what is being observed.
I would argue that this isn’t the same thing as a diagnosis of underlying causal process. An Apgar of 5 doesn’t tell you what is wrong with the newborn, only that something is wrong right now. In some cases, the situation can be sorted quickly with a simple intervention, and the baby goes back to being ‘healthy’. A low GCS doesn’t tell you anything about what’s going on with the patient, only that it is probably urgent.
This is an argument as to why scores generally should not be Evaluations.
On the other hand, most scores are time-linked. You have to keep doing them to get the current interpretation. Barthel is an example - it might be good this month, and bad next month.
By that argument, scores should mostly be Observations. Nearly all scores in CKM are in fact Observations, so either the authors agree with the above, or have other reasons.
As I said, a bit of philosophy fun…!