After encountering my first DV_INTERVAL<DV_DATE_TIME> I fear that their use is not consistent in the implementations.
For example, the archetype openEHR-EHR-EVALUATION.death_summary.v0 contains two alternatives in the Date/time of death, one of them being DV_INTERVAL<DV_DATE_TIME>
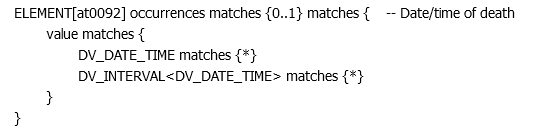
So far so good. However, if we create a template for this it ends up like this
This correctly creates the types of the elements in the interval, but the type is still DV_INTERVAL<DV_DATE_TIME> (encoded, which could make things worse)
Should the type in the template be just ‘DV_INTERVAL’ as it is the class in the schema? is anyone out there storing the type as DV_INTERVAL<DV_DATE_TIME> in their data instances? (or worse, as DV_INTERVAL& lt;DV_DATE_TIME& gt;)
I would say it should be DV_INTERVAL<DV_DATE_TIME> - that is the correct type of the top-level object. The only way it could be just DV_INTERVAL is if any hierarchy of typed objects was to be interpreted as generic parameterisation - which obviously would not be generally correct. To make that work, a flag of some sort would be needed at the root of a generically typed object to say ‘isGeneric’ or similar.
But the <DV_DATE_TIME> is pointing to a runtime constraint that it is satisfied already by the definition in the OPT. The actual type is just DV_INTERVAL. Different runtime constraints shouldn’t define different types in data.
The class name DV_INTERVAL on its own can’t be the type of anything. Type names like DV_INTERVAL<Any>, DV_INTERVAL<DV_ORDERED> and DV_INTERVAL<DV_DATE_TIME> are all possible static types of runtime objects with concrete types, of which only DV_INTERVAL<DV_DATE_TIME> among those examples is an example.
In ADL and the OPT it should have the complete type DV_INTERVAL<DV_DATE_TIME>.
In JSON/XML serialization of instances complying with those ADL/OPT, it should be just DV_INTERVAL (this was agreed some time ago, though I would prefer to have the same type everywhere for consistency).
Also not having the generic type specified, makes the need, in some contexts, to do a look ahead of the interval upper and lower types, to know which type to create, or to query the corresponding OPT.
That was the answer I was looking for
What I found strange was to have in the OPT both the DV_INTERVAL plus the type itself in the lower and upper, which seemed redundant
XSD is not a guide to model accuracy, only a guide to approximations of model ‘types’ that are supported in XML data. XSD doesn’t support generics, so then you have to use some workaround. Dropping the generics is like Java type erasure. So that’s ok for XML data conforming to the RM XSD. But it still has to be materialised at some point into proper types, e.g. Java objects or whatever, which requires the generic type information.
And other serial forms like JSON, YAML, etc should really carry the full typing information.
Let’s say your deserialiser hits the DV_INTERVAL node. It’s trying to materialise Java (or C#, or Kotlin, or … whatever) objects. What does it do? How does it even know it is on a generically typed object? It could theoretically look up an in-memory representation of the RM, figure out that DV_INTERVAL is a generic type, and instantiate the highest static type possible, which is DvInterval<DvOrdered>. But the runtime type is DvInterval<DvDateTime> - and it won’t instantiate that, without some sort of help from the typing info in the data.
But if you get a DvInterval with DvDateTime inside it would be perfectly usable, you could even serialize it again and get the same result. Even archie has “instanceof” in the interval methods to do different kinds of compares
Yep, that’s the issue I mentioned need to be solved by a look-ahead to be able to instantiate the interval type profiled by the correct generic type for T, and it’s why it would be more consistent to have the generic type on JSON/XML instances too.
Even if XSD doesn’t support DV_INTERVAL as a type, that is just a name in the schema, so even if each DV_INTERVAL, DV_INTERVAL, DV_INTERVAL need a different type in the XSD/JSON schemas, it would worth the extra bytes just for consistency.
I can’t believe you’re having all this fun without me
Warning: most of the content below is mostly geekery.
This is the design choice between reified (as Java and Haskell does) and non-reified (as C# and .NET langs do, also C++ templates) implementation of parametric polymorphism (not being a wisea**, just in case someone wants to search relevant literature).
Java did this (with input from Philip Wadler, a real heavyweight in FP) to keep the java compiler output backward compatible while supporting generics at the language level (read: code running in the banks). Many other plausible justifications were given through the years, but Occam’s razor is still sharp Once you lose the generics related info for a type, things can become difficult in the trenches. For example, to take a glimpse at the rabbit hole @thomas.beale describes above:
(.NET design team have been laughing their backsides off since 2002 and have not been available for comment re the above…)
So based on all the above: I’d say you want to have type information around whenever you can. Ideally, you’d even encode it in the data serialisation to help with deserialisation. Why?
You’d see that really quickly if you implemented the logic that’s delegated to Java/C# libraries. That is, if you came up with a data format without a serialisation library that jumps through the hoops as existing ones does, it’d be you who’d have to figure out the type of the RM object encoded in that data format.
I think the good news is this is already delegated to libraries that handle json/xml, but having the information in the opt means that you can use it as type metadata to derive your own serialisation/deserialisation logic using the opt as your guide, if you ever do that.
So having the full generic type is unlikely to be useful? Yes, most probably. Still good to have? Yes, I’d say so, because it allows some advanced implementations if need be, and a small price to pay to keep some future implementations possible.
None of the above matters for practical purposes, but the discussion is intellectually just too tempting to skip
My point about OPT is: why do you need to say DV_INTERVAL<DV_DATE_TIME> as the type of the interval if you already have the type of the lower and upper defined in the OPT itself. That’s what I see as redundant (but of course I can be wrong)
I completely understand where you’re coming from. The thing with generics is, things look redundant in many cases, but then there’s an edge case where the redundant looking approach helps avoid a problem. It’s usually easier to keep our guard than selectively use some mechanism/syntax.
In this example, you “know” the value of the type parameter as you indicated, so you’re not wrong. It’s just that there are some use cases where it helps to have the full type of the interval. It won’t be redundant then, so you’re not wrong for this case, but you may be wrong (re it being redundant) in some other cases.
Well you still need to know that DV_INTERVAL is a generic type. From the JSON data, you won’t know unless there is some indicator (e.g. putting _type = "DV_INTERVAL<>" will achieve this), or else you can look up in a schema / BMM / other model representation. But if you don’t have either of those in place, the deserialiser is not going to be able to distinguish between the DV_INTERVAL<DV_DATE_TIME> object and this (illegal, in openEHR) structure (this is AOM serialised to JSON):
The type implied by DV_INTERVAL is the type-erased form of some DV_INTERVAL<XX> generic type - but it won’t match anything statically typed in the code. A Java deserialiser would probably just instantiate DV_INTERVAL<Object>, but code that assumes DV_INTERVAL<XX> won’t work - it would need to manually do type casting of the sub-parts to do so.
In instance data there would be some _type: "DV_INTERVAL" at the top.
As @Seref says, for a small cost, it’s usually better to put all the typing information you’ve got.
But isn’t this the same case for using abstract classes? (or methods/properties) why is fine to require knowledge of the schema in some cases and not the others?