The purpose of openEHR.CKM or for Norway arketyper.no versus the library of all clinical models containing both bad patterns and also the ideal/good ones which represents the future of modelling for specific purposes.
I tend to look at the CKM as the reference library of what is in use in different domains. openEHR.CKM is the international go-to reference and the Norwegian one for national models. Any actor who wants to develop, use or mandate the use of clinical concepts should be safe picking one archetype from those services.
The problem here is how to do release management. For archetypes which is widely used the cost of breaking change is big. Sometimes the cost of change is higher than the benefits of the improved model.
How do we as a community choose the right way to cope with such changes. It is hard and the complexity of different interests/views will impact the decisions.
The tensions are real, but CKM is not the single solution here and it is not the Editors’ role to keep everyone happy - that will fail for sure.
As a broad community, we need to be able to disambiguate all the stakeholders, especially focusing on how each needs to use/consume the archetypes, and potentially develop solutions to support each use case.
CKM should be the ‘source of truth’, or best practice or however you want to phrase it, neutral to how end users use them in practice.
If release sets or similar solutions are developed, they also have value for measuring conformance etc. It could be a good thing in more ways than one…
A simplistic process would be to take a baseline (= list of {archetype id, version} pairs) today, or at some known date where no major version changes to archetypes had occurred for a while. And then to compute a new baseline each time a new major version of anything is published (or perhaps a set of new versions on the same day or whatever). Additions of new v0 archetypes would not cause new baselines. Incubator and local project archetypes would be ignored.
Then a simple means of tagging baselines would be useful.
This could be done in CKM, but it could be done more easily, probably in the CKM-mirror Git repo, and indeed could be retrospectively computed back to the start of that repo.
This would provide a means for user orgs to identify what release they are using, and to decide whether to stick with it. In the Git repo some releases (identified by their tags) could have a branch created for them, with the only additions on the branches being ‘fixes’ - minor & patch version republications of included archetypes.
Just a few thoughts on what is a really helpful discussion.
‘Implementers’ are increasingly not software engineers or vendors - they are actually healthcare organisations. Perhaps ‘consumers’ rather than ‘implementers’ and certainly not vendors. The cost (money and clinical risk/upheaval) of managing breaking changes essentially lands at their door.
This was one of the issues that emerged from the ADL2 discussions - that while some openEHR implementations are essentially single vendor systems (and therefore the vendor can take a view on the cost/risk of handling a breaking change, but in many more, it is the hc provider that will make that decision and they are quite likely to operate much more tactically.
The risk is that the vast majority might decide never to adopt a breaking change whose change seems an edge case, so we end up with all of the established systems using the old version, whilst new entrants, not unreasonably are likely to adopt the new version.
The current approach to model governance, as Heather outlined, is I agree, pretty well optimal, but I don’t think it can work without any regard for ‘consumer impact’. Now, I know that is not the case … the CKAs, as Heather has said do recognise the significance of breaking changes and the fact that this Discourse topic exists at all is due to a recognition by the CKAs that this is a tricky modelling problem and may have a potential impact. So thanks for raising it.
I do wonder though, if this good and welcome practice might need to be underpinned by a more formal process that ensures widespread community engagement. Doing that for every breaking change would be both counter-productive and unsustainable but perhaps we can define a small set of ‘premium / mature’ archetypes, where really wide community reflection is sought before publication, including a deep-dive into the challenges which the modellers faced which led to the recommendations.
@Siljeb@heather.leslie - can you help us better understand why the current model could not be made to work, or was problematic?
As Joost said earlier, it was possible to differentiate heartbeat vs. pulse by the device or location used, but I would certainly have supported a specific new ‘mode’ element which explicitly allowed us to record ‘pulse’ vs ‘heartbeat’ vs ‘electrical RR rate’ to make the usage crystal-clear where necessary.
I saw in @siljelb original post that the need to use differential term bindings to support export to FHIR Observations may have been a factor. This might also be relevant to separate discussions about how bindings relate to run-time mappings.
Hi again all, and thanks for your responses in this thread and in the separate thread specifically about the semantics of “pulse” and “heart beat”. Based on the responses we’ve received from clinicians and others that “pulse” and “heart beat” are conceptually different, it’s looking more and more likely that we’ll end up with two completely separate archetypes.
Then there is the “ontology of practical clinical recording” view than Ian mentioned in the other thread:
The issue of mixing up these concepts has been present since the days of paper record forms with limited flexibility and limited space. The data written in paper forms will always be subject to human interpretation both when captured and when used, while digital forms are much more dependent on clearly defined information concepts for computer reuse. On the other hand, digital forms make it much easier to allow the user the option of choosing which of the two concepts they’re observing and recording. Additionally, it seems likely that in most use cases you can make good assumptions about which of the two concepts should be the default choice presented in a user interface.
On this basis, we’re proposing to remodel the concepts as two completely separate archetypes.
Are there any practical uses, apart from existing applications, where this approach would be problematic?
Sorry I still feel this is going in an unhelpful direction but was bending to majority views.
To be clear, I absolutely understand and support the need to be able to clearly distinguish between heart beat, pulse and indeed electrical heart rate in some clinical circumstances.
However, I feel that forcing designers to actively choose the particular flavour ‘up front’ will be confusing, or where there is a potential switch between e.g. a single -lead ECG to pulse oximetry, then there is now a need need to carry 2 different archetypes in any template to represent Artery site, plus a set of guidance to the developers.
I still don’t really understand why the simple of addition of the Method element in the new heat beat archetype to the existing archetype could not have solved the problem, along with a couple of embedded templates to show how to represent ‘pure heart beat’ vs ‘pure pulse’ and ‘pure heart rate’ if people want to model them as specific artefacts.
That’s it - no more from me!! If I’m in the minority, so be it … @joostholslag was, I think, the other rebel ??
We do not yet have a simple solution to the competing needs, which are:
being able to model ‘properly’ what is in reality, including things that are needed 1% of the time, but when they are needed, we need them done right (and in healthcare, 1% is still big - so it matters. 1% of 100m health visits is a million visits…)
making the 99% need (here: record heart rate in ‘normal’ situation; peripheral pulse is an acceptable surrogate for heartbeat) easy and obvious
not breaking existing software and systems.
All of these really matter. In the ‘real world’ of economics, business, purchasing, keeping customers happy, the last one has some priority, since vendors and procurers tend to vote with their feet, not their hearts (see what I did there), so we can’t ignore it.
I have not followed the detailed modelling discussion all the way through, but some way of allowing a ‘simple heart rate’ (usually by peripheral surrogate, i.e. standard pulse oximeter or manual count) and a ‘detailed heart rate’ (all the other non-routine stuff) is needed.
To me this seems similar to the common modelling situation of ‘simple body location’ and ‘structured body location’, which is currently achieved with two separate Elements in openEHR (in S2, we have fixed this, and it is very nice), and a couple of others that have a pair of ‘simple’ and ‘structured’ (Person address, is another example from memory).
I don’t have a proposal, but I would counsel against ignoring the last bullet above. If the modelling approach is too complex to do the 99% of routine heart rate easily, vendors & implementers will just do something else, and the beautiful new models are for nothing.
The ‘Method’ element doesn’t really differentiate between the two concepts, especially the ‘Palpation’ value is common between both.
In use cases where this switch is likely to happen, that would certainly be a necessity. But which cases are we talking about then? Most monitoring in a perioperative or ICU setting would use both of these (although usually more than a single lead) at the same time, and it would be important to be able to tell them clearly apart. Or are we talking about exercise watches?
We’ve discussed this earlier, and while I agree we shouldn’t break anything existing, I don’t agree publishing new major revisions of any archetype “breaks” anything. It’s not like we’re removing the older revisions from existence, they’re even still in the CKM although in a deprecated state. Vendors will in any case have to make decisions about which archetypes they use and don’t use.
Tbh it’s a struggle trying to consolidate all of these requirements and issues when so many of the responses are of the form “I don’t know how to do this, but it’s definitely not this way”. I do appreciate everyone’s participation, but I’d also very much appreciate suggestions on how to solve the problem.
This kind of conversation is difficult and hard work, and this is why the thread exists. Personally, behind the scenes the investigation and proposal of alternative models for these concepts has taken more days of my life than I care to think about - many iterations over many years to try to ‘nail it’. We make some progress with each iteration, understanding the use cases better but still butting up against the messy current clinical documentation. It would have been far easier to take the lazy way out and leave well enough alone, except it doesn’t work for the less frequent yet clinically critical use cases. This is the responsibility for each Editor/CKA to try to create modelling patterns that work for all.
As @siljelb says, nothing is broken if the current model remains, even if deprecated to indicate this is not best practice, and we replace with new models that best reflect best practice documentation as a road map for new vendors and existing vendors to use as a roadmap for future development.
If clinicians were offered these alternative models as options, it is very possible they would be preferred. It would promote discussions on how to differentiate the edge cases and document them more clearly, and accurately. This approach improves the quality of our data, decreases variability, and can positively impact on health outcomes. And after all, this is why I am a clinical modeller.
We really need to question the acceptance of having a deliberately vague or ‘muddy’ archetype that ‘does it all’, but is possibly not fit for the job. Especially if we are to rely on it for CDS, AI and personalised medicine.
In which case, lets agree and publish the ‘gold standard’ archetype for each concept, even if it is not yet a popular implementation choice, leave the existing archetype in the CKM, and let the market and associated rise of knowledge-driven activities naturally drive the changes in implementations.
What is the extent of current implementations? Is it only the rate (heart or pulse) or is it more of the existing model? Does anyone have a good insight into the level of detail of implementation?
Fair enough. Well, as you can see my view above is (and remains) ‘release management’. @heather.leslie thinks that’s not a function of ‘clinical modelling’, which I probably agree with, and/or something that should be in CKM. I don’t agree with the latter - CKM is just a tool. Heather said earlier that vendors should define releases. I can see that that might be useful, but vendors won’t be the definers of something like a LTS (= Long Term Support, a term used in general IT to refer to long term stable versions of things like Linux) release of ‘models for core general medicine’ or similar.
So arguably our real task is to figure out who defines such releases and for what purpose. openEHR should be the coordinating org, but we might take the approach that we get input from Org partners and similar orgs (even if not currently a paid up org partner), e.g. Karolinska, various UK trusts etc.
If such orgs + vendors (we need them because it’s their code and other products that are directly affected) could help us define releases that everyone can use as the baseline for the future.
If we could actually start defining these releases, bleeding edge clinical modelling activities can keep going with no worry of breaking anything or getting pushback.
This overall situation is really no different from general adoption of IT products, where 10% are always using the latest beta of some tool (Firefox or whatever), 75% use the LTS release and 15% are laggards stuck on ancient versions.
We should definitely do this; but we need to be super careful that breaking changes are always recognised with major version change. Otherwise release management can’t be implemented.
@thomas.beale I’m not sure you’ve understood me correctly. I suggest that:
the publication of ‘gold standard’ archetypes is the domain of the CKAs in CKM.
In parallel, the development and publication of release sets as combinations of archetypes via CKM is another layer of governance. Who is responsible and what the purpose is obviously yet to be defined. It may be best done by those with skin in the game, whether for conformance testing of ‘core’ or for specific use cases, as you suggest. Maybe this is a role for the new Software Board, on behalf of the implementers and orgs.
IMO I believe there is a need for an additional tool that supports implementation governance at vendor or org level across all of their applications eg the situation where v1 of an archetype is implemented in one application and when a new application developed by the same vendor it uses the latest version, a v2. When any update in CKM, whether a revision or v3, occurs it helps inform the vendor if and when they need to update either or both archetypes.
This kind of functionality is mainly tooling, that doesn’t yet exist. But at a minimum, some API calls could be developed for CKM that allowed an external party to subscribe to a) an archetype or other single artefact, b) a release, c) a ‘project’ or other grouping of artefacts. For any of these, the subscriber would receive a notification for any change to the published form of any constituent artefact.
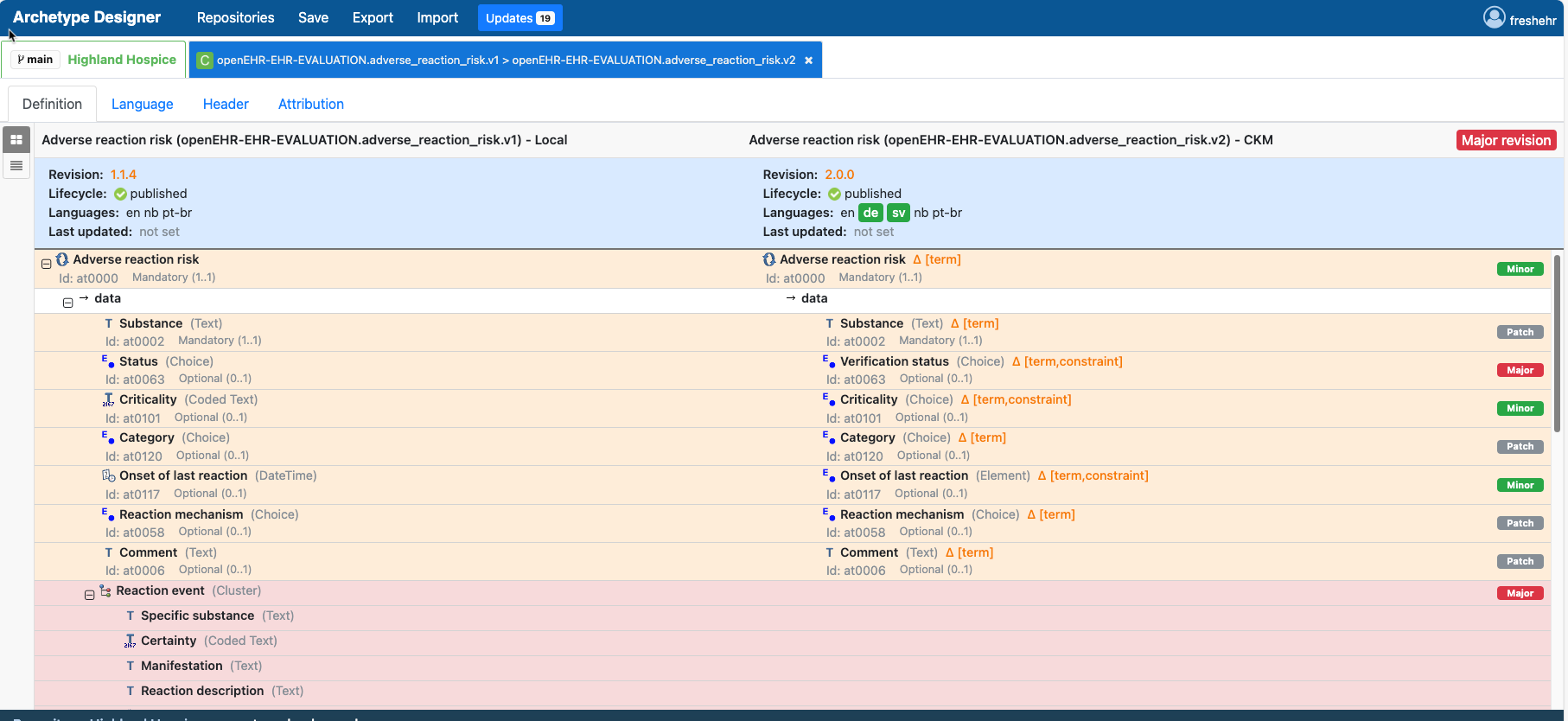
AD does actually support this moderately well already via the ‘Updates’ option, This needs to be enabled in Settings.
If enabled, a new tab appears which shows if there are any differences between the versions of archetypes used in the locla repo vs. the versions in CKM (via the Github repo).
Clicking on the tab then gives you detailed ‘diff’ information on each archetype, based on semver, and the opportunity to update and outdated archetype very cleanly.
This actually fits our current practice more cleanly, than a simple notification of a change, as almost certainly we will want to review use (or not) of the latest version of archetypes at the start of a new round of development , and perhaps near the end before we need to lock things down.
The diff feature is not perfect but it is proving very helpful and definitely going in the direction that @heather.leslie rightly expects - something much more
project orientated than CKM is intended (at least for now).
I also think this ‘project tool’ is quite likely to be something much broader than just openEHR as it will need to handle Valuesets, mappings, and various other dependencies.
I suspect this is the POV of an author / editor more than an organisation though. Consider if (say) Sweden) decided to use some Release called ‘Models for General medicine 2024 LTS’. Over time, models in that release will get new versions and there will also be new models added for general medicine. It would be very helpful to have automated notifications that don’t rely on a human working on a particular model in a tool.
Good point - those things should normally be considered as contents of a ‘Release’ as well.